
ubuntu18.04 搭建hadoop完全分散式叢集(Master、slave1、slave2)共三個節點
一、硬體配置以及作業系統:
所需要的機器以及作業系統:一臺mac os筆記本、一臺window筆記本(CPU雙核四執行緒,記憶體8G),其中mac os用於遠端操作,window筆記本裝有虛擬機器,虛擬出3個ubuntu18.04系統(配置CPU1個執行緒2個,記憶體1.5G,硬碟分配每個70G),對於mac os(可以用window機或者linux機)的配置沒有要求
- 使用vm建立3個ubuntu18.04系統,一個主節點:master(NameNode)和兩個從節點slave1(DataNode)和slave2(DataNode)
- 節點IP分配:主節點IP為:192.168.0.109、從節點1IP為:192.168.0.110、從節點2IP為:192.168.0.111
- 虛擬機器的網路選擇橋接模式與物理網路的網段相同,這樣有助於遠端連線。
- master的主機名為:sunxj-hdm,slave1的主機名為:sunxj-hds1,slave2的主機名為:sunxj-hds2,如下圖所示:



- 定義域名:sunxj-hdm.myhd.com(master),sunxj-hds1.myhd.com(slave1),sunxj-hds2.myhd.com(slave2)
- 配置hosts,將3臺的hosts配置為:
192.168.0.109 sunxj-hdm.myhd.com 192.168.0.110 sunxj-hds1.myhd.com 192.168.0.111 sunxj-hds2.myhd.com
如下圖所示:
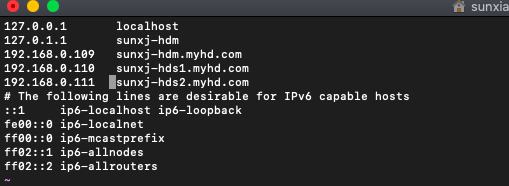
注意:不能放在最下邊,從註釋行開始往下是配置ipv6的,ip和域名之間必須是一個tab,且域名後不能有空格,否則是ping不通的,還有3個主機必須配置相同才能互ping。
7.然後使用如下命令進行重啟網路
sudo /etc/init.d/networking restart如下圖所示:
![]()
8、然後通過ping sunxj-hds1.myhd.com檢視是否可以ping的通,如果是通的則配置成功,如果不通需要在找原因了,如下圖所示:
在master機ping slave1和slave2

在 slave1機ping master和slave2

在 slave2機ping master和slave1

二、節點需要安裝的工具:
三個節點需要安裝的工具為:vm-tool、gcc、net-tools、openssh-server、vsftpd、vim(用於ftp服務)
安裝順序:
(1)sudo apt install gcc
(2) 安裝vm-tool
(3)sudo apt install net-tools
(4)sudo apt install vim
(5)sudo apt install openssh-server(可以使用/etc/init.d/ssh start 啟動ssh)
(6)在安裝好ssh後即可遠端操作,在macos中開啟終端進行ssh遠端連線,如下圖所示:

(7)安裝ftp服務並配置vsftpd請看:https://blog.csdn.net/sunxiaoju/article/details/85224602
三、安裝JDK環境
1、安裝java,三臺主機都需要安裝,安裝方法請看:https://blog.csdn.net/sunxiaoju/article/details/51994559
四、建立hadoop使用者
1、在master節點上使用如下命令來建立hadoop使用者
sudo adduser hadoop如下圖所示:

2、使用如命令把hadoop使用者加入到hadoop使用者組,前面一個hadoop是組名,後面一個hadoop是使用者名稱
sudo usermod -a -G hadoop hadoop如下圖所示:
![]()
3、可以使用如下命令來檢視結果
cat /etc/group |grep hadoop如下圖所示:
![]()
4、把hadoop使用者賦予root許可權,讓他可以使用sudo命令,使用如下命令編輯
sudo vim /etc/sudoers修改檔案如下:
root ALL=(ALL) ALL
hadoop ALL=(root) NOPASSWD:ALL如下圖所示:
修改前:

修改後:

5、用同樣方法在slave1和slave2上建立hadoop使用者。
五、建立ssh無密碼登入本機
ssh生成金鑰有rsa和dsa兩種生成方式,預設情況下采用rsa方式。
1、首先用hadoop使用者在master主機上建立ssh-key,這裡我們採用rsa方式。使用如下命令(P是要大寫的,後面跟"",表示無密碼)
ssh-keygen -t rsa -P ""如下圖所示:
![]()
2、直接回車即可,然後就會生成相應的資訊,如下圖所示:

3、回車後會在~/.ssh/下生成兩個檔案:id_rsa和id_rsa.pub這兩個檔案是成對出現的,進入到該目錄檢視,如下圖所示:
![]()
4、然後分別在slave1和slave2用同樣的方法生成,然後分別用
scp id_rsa.pub [email protected]:/home/sunftp/ftpdir/slave1_id_rsa.pub
scp id_rsa.pub [email protected]:/home/sunftp/ftpdir/slave2_id_rsa.pub將slave1和slave2的檔案上傳到master上,如下圖所示:


5、使用如下指令,將上傳到master上的slave1_id_rsa.pub和slave2_id_rsa.pub檔案移動到~/.ssh/目錄
sudo mv /home/sunftp/ftpdir/slave1_id_rsa.pub slave1_id_rsa.pub
sudo mv /home/sunftp/ftpdir/slave2_id_rsa.pub slave2_id_rsa.pub如下圖所示:

6、將id_rsa.pub、slave1_id_rsa.pub、slave2_id_rsa.pub追加到authorized_keys授權檔案中,開始是沒有authorized_keys檔案的,只需要執行如下命令即可:
cat *.pub >>authorized_keys如下圖所示:

7、然後可以通過:ssh localhost測試本機無密碼登入,如下圖所示:

8、將master上的公鑰拷貝到slave1和slave2上,使其master無密碼登入slave1和slave2,首先將authorized_keys檔案通過scp上傳到slave1和slave2的/home/sunftp/ftpdir/目錄中,使用如下命令來上傳
scp authorized_keys [email protected]:/home/sunftp/ftpdir
scp authorized_keys [email protected]:/home/sunftp/ftpdir,如下圖所示:

9、此時在slave1和slave2上的/home/sunftp/ftpdir/目錄中存在authorized_keys檔案檔案,如下圖所示:
![]()
![]()
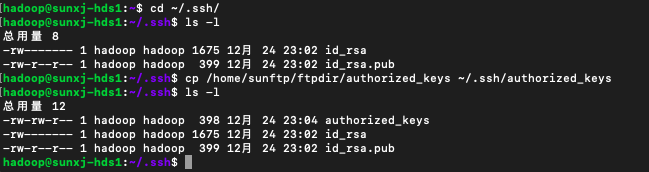
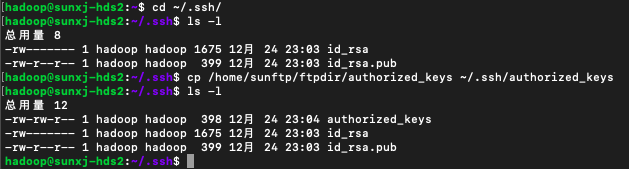
10、分別在兩臺slave機器上執行1~3部,然後如下命令將公鑰拷貝到~/.ssh/目錄中
cp /home/sunftp/ftpdir/authorized_keys ~/.ssh/authorized_keys如下圖所示:
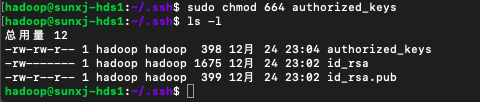
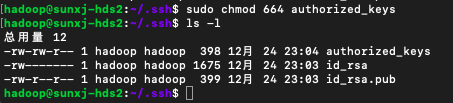
11、使用:sudo chmod 664 authorized_keys 修改authorized_keys的許可權,如下圖所示:
12、然後在mstar上無密碼登入slave1和slave2,如下圖所示:


13、然後在slave1上無密碼登入mstar和slave2,如下圖所示:


14、然後在slave2上無密碼登入slave1和mstar,如下圖所示:


注意:如果無法登入請檢視/home/下的使用者許可權是否是755,如果不是則無法登入的,我的slave1就是將/home/sunxj的許可權設定為:777,只需要將sunxj設定為755即可,如下圖所示:


12、到此就可以在master上無密碼登入slave1和slave2了。
六、安裝hadoop
1、首先從https://hadoop.apache.org/releases.html下載,如下版本:

2、這裡選擇hadoop2.7.7的Binary版本。
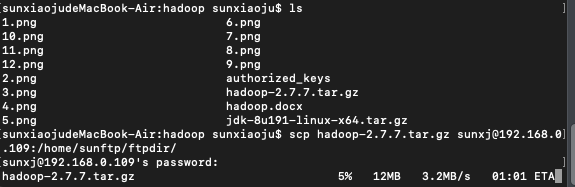
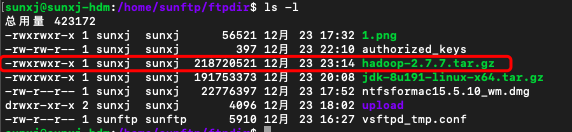
3、使用scp命令將下載好的hadoop上傳到master,(此時的使用者名稱也可以使用其他的使用者配置)如下圖所示:
4、使用如下命令解壓
tar -xzvf hadoop-2.7.7.tar.gz將hadoop-2.7.7.tar.gz如下圖所示:

5、將hadoop-2.7.7移動到/usr/目錄,如下圖所示:

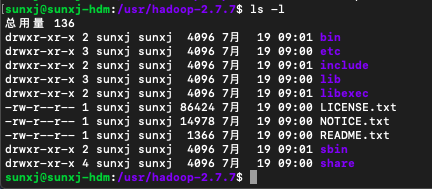
6、檢視hadoop的目錄,如下圖所示:
7、在hadoop-2.7.7目錄中一個hdfs目錄和三個子目錄,如
- hadoop-2.7.3/hdfs
- hadoop-2.7.3/hdfs/tmp
- hadoop-2.7.3/hdfs/name
- hadoop-2.7.3/hdfs/data

8、在hadoop-2.7.7/etc/目錄中檢視需要配置的檔案有:
- core-site.xml
- hadoop-env.sh
- hdfs-site.xml
- mapred-site.xml.template
- yarn-env.sh
- yarn-site.xml
- mapred-env.sh
- slaves
如下圖所示:

9、首先配置core-site.xml檔案,使用如下命令開啟
sudo vim etc/hadoop/core-site.xml然後在<configuration></configuration>中如下配置是讀寫sequence file 的 buffer size,可減少 I/O 次數。在大型的 Hadoop cluster,建議可設定為 65536 到 131072,預設值 4096.按照教程配置了131072:
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop-2.7.7/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://sunxj-hdm.myhd.com:9000</value>
</property>
注意:第一個屬性中的value和我們之前建立的/usr/hadoop-2.7.7/hdfs/tmp路徑要一致。
如下圖所示:

屬性說明:
| 引數 | 屬性值 | 解釋 |
| fs.defaultFS | NameNode URI | hdfs://host:port/ |
| io.file.buffer.size | 131072 | SequenceFiles檔案中.讀寫快取size設定 |
fs.defaultFS //為masterIP地址,其實也可以使用主機名或者域名,這個屬性用來指定namenode的hdfs協議的檔案系統通訊地址,可以指定一個主機+埠,也可以指定為一個namenode服務(這個服務內部可以有多臺namenode實現ha的namenode服務)
o.file.buffer.size //該屬性值單位為KB,131072KB即為預設的64M,這個屬性用來執行檔案IO緩衝區的大小
hadoop.tmp.dir //指定hadoop臨時目錄,前面用file:表示是本地目錄。有的教程上直接使用/usr/local,我估計不加file:應該也可以。hadoop在執行過程中肯定會有臨時檔案或緩衝之類的,必然需要一個臨時目錄來存放,這裡就是指定這個的。當然這個目錄前面我們已經建立好了。<!-- 也有人使用zookeeper,因此,需要在hadoop核心配置檔案core-site.xml中加入zookeeper的配置:-->
<!-- 指定zookeeper地址 。zookeeper可以感知datanode工作狀態,並且提供一些高可用性的特性。暫時不瞭解zookeeper,後續再說。先不加入這個配置了暫時。-->
<property>
<name>ha.zookeeper.quorum</name>
<value>dellserver01:2181,dellserver02:2181,dellserver03:2181,dellserver04:2181,dellserver05:2181</value>
</property>10、配置 hadoop-env.sh檔案,用於配置jdk目錄,使用如下命令開啟
sudo vim etc/hadoop/hadoop-env.sh然後將export JAVA_HOME=${JAVA_HOME}註釋掉配置成具體的路徑:export JAVA_HOME=/usr/jdk1.8.0_191,否則在執行時會提示找不到JAVA_HOME,如下圖所示:

11、在mapred-env.sh加入JAVA_HOME,如下圖所示:

12、在yarn-env.sh加入JAVA_HOME,如下圖所示:

13、配置hdfs-site.xml,使用如下命令開啟檔案
sudo vim etc/hadoop/hdfs-site.xml然後在<configuration></configuration>中加入以下程式碼:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop-2.7.7/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop-2.7.7/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sunxj-hdm.myhd.com:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>注意:其中第二個dfs.namenode.name.dir和dfs.datanode.data.dir的value和之前建立的/hdfs/name和/hdfs/data路徑一致;由於有兩個從主機slave1、slave2,所以dfs.replication設定為2
如下圖所示:

屬性說明:
- 配置NameNode
| 引數 | 屬性值 | 解釋 |
| dfs.namenode.name.dir | 在本地檔案系統所在的NameNode的儲存空間和持續化處理日誌 | 如果這是一個以逗號分隔的目錄列表,然 後將名稱表被複制的所有目錄,以備不時 需。 |
| dfs.namenode.hosts/ dfs.namenode.hosts.exclude |
Datanodes permitted/excluded列表 | 如有必要,可以使用這些檔案來控制允許 資料節點的列表 |
| dfs.blocksize | 268435456 | 大型的檔案系統HDFS塊大小為256MB |
| dfs.namenode.handler.count | 100 | 設定更多的namenode執行緒,處理從 datanode發出的大量RPC請求 |
- 配置DataNode
| 引數 | 屬性值 | 解釋 |
| dfs.datanode.data.dir | 逗號分隔的一個DataNode上,它應該儲存它的塊的本地檔案系統的路徑列表 | 如果這是一個以逗號分隔的目錄列表,那麼資料將被儲存在所有命名的目錄,通常在不同的裝置。 |
14、複製mapred-site.xml.template檔案,並命名為mapred-site.xml,使用如下命令拷貝
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml並編輯mapred-site.xml,在標籤<configuration>中新增以下程式碼:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>sunxj-hdm.myhd.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>sunxj-hdm.myhd.com:19888</value>
</property>
如下圖所示:

屬性說明:
| 引數 | 屬性值 | 解釋 |
| mapreduce.framework.name | yarn | 執行框架設定為 Hadoop YARN. |
| mapreduce.map.memory.mb | 1536 | 對maps更大的資源限制的. |
| mapreduce.map.java.opts | -Xmx2014M | maps中對jvm child設定更大的堆大小 |
| mapreduce.reduce.memory.mb | 3072 | 設定 reduces對於較大的資源限制 |
| mapreduce.reduce.java.opts | -Xmx2560M | reduces對 jvm child設定更大的堆大小 |
| mapreduce.task.io.sort.mb | 512 | 更高的記憶體限制,而對資料進行排序的效率 |
| mapreduce.task.io.sort.factor | 100 | 在檔案排序中更多的流合併為一次 |
| mapreduce.reduce.shuffle.parallelcopies | 50 | 通過reduces從很多的map中讀取較多的平行 副本 |
15、配置yarn-site.xml,使用如下命令開啟
sudo vim etc/hadoop/yarn-site.xml 然後在<configuration>標籤中新增以下程式碼:
<property>
<name>yarn.resourcemanager.address</name>
<value>sunxj-hdm.myhd.com:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sunxj-hdm.myhd.com:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sunxj-hdm.myhd.com:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sunxj-hdm.myhd.com:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sunxj-hdm.myhd.com:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>如下圖所示:

屬性說明:
- master節點配置ResourceManager 和 NodeManager:
| 引數 | 屬性值 | 解釋 |
| yarn.resourcemanager.address | 客戶端對ResourceManager主機通過 host:port 提交作業 | host:port |
| yarn.resourcemanager.scheduler.address | ApplicationMasters 通過ResourceManager主機訪問host:port跟蹤排程程式獲資源 | host:port |
| yarn.resourcemanager.resource-tracker.address | NodeManagers通過ResourceManager主機訪問host:port | host:port |
| yarn.resourcemanager.admin.address | 管理命令通過ResourceManager主機訪問host:port | host:port |
| yarn.resourcemanager.webapp.address | ResourceManager web頁面host:port. | host:port |
| yarn.resourcemanager.scheduler.class | ResourceManager 排程類(Scheduler class) | CapacityScheduler(推薦),FairScheduler(也推薦),orFifoScheduler |
| yarn.scheduler.minimum-allocation-mb | 每個容器記憶體最低限額分配到的資源管理器要求 | 以MB為單位 |
| yarn.scheduler.maximum-allocation-mb | 資源管理器分配給每個容器的記憶體最大限制 | 以MB為單位 |
| yarn.resourcemanager.nodes.include-path/ yarn.resourcemanager.nodes.exclude-path |
NodeManagers的permitted/excluded列表 | 如有必要,可使用這些檔案來控制允許NodeManagers列表 |
- slave節點配置NodeManager
| 引數 | 屬性值 | 解釋 |
| yarn.nodemanager.resource.memory-mb | givenNodeManager即資源的可用實體記憶體,以MB為單位 | 定義在節點管理器總的可用資源,以提供給執行容器 |
| yarn.nodemanager.vmem-pmem-ratio | 最大比率為一些任務的虛擬記憶體使用量可能會超過實體記憶體率 | 每個任務的虛擬記憶體的使用可以通過這個比例超過了實體記憶體的限制。虛擬記憶體的使用上的節點管理器任務的總量可以通過這個比率超過其實體記憶體的使用 |
| yarn.nodemanager.local-dirs | 資料寫入本地檔案系統路徑的列表用逗號分隔 | 多條儲存路徑可以提高磁碟的讀寫速度 |
| yarn.nodemanager.log-dirs | 本地檔案系統日誌路徑的列表逗號分隔 | 多條儲存路徑可以提高磁碟的讀寫速度 |
| yarn.nodemanager.log.retain-seconds | 10800 | 如果日誌聚合被禁用。預設的時間(以秒為單位)保留在節點管理器只適用日誌檔案 |
| yarn.nodemanager.remote-app-log-dir | logs | HDFS目錄下的應用程式日誌移動應用上完成。需要設定相應的許可權。僅適用日誌聚合功能 |
| yarn.nodemanager.remote-app-log-dir-suffix | logs | 字尾追加到遠端日誌目錄。日誌將被彙總到yarn.nodemanager.remoteapplogdir/yarn.nodemanager.remoteapplogdir/{user}/${thisParam} 僅適用日誌聚合功能。 |
| yarn.nodemanager.aux-services | mapreduce-shuffle | Shuffle service 需要加以設定的Map Reduce的應用程式服務 |
16、使用如下命令開啟slaves檔案
sudo vim etc/hadoop/slaves 把原本的localhost刪掉,然後分別改為:sunxj-hds1.myhd.com,sunxj-hds2.myhd.com ,如下圖所示:

17、配置hadoop環境變數,使用sudo vim /etc/profile開啟檔案,在末尾新增入下程式碼:
export HADOOP_HOME=/usr/hadoop-2.7.7
export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop如下圖所示:

18、輸入如下命令使配置立即生效
source /etc/profile 19、使用如下命令:
scp -r hadoop-2.7.7 [email protected]:/home/sunftp/ftpdir/將hadoop-2.7.7傳給slave1,如下圖所示:

20、然後在slave1上將hadoop-2.7.7移動到usr目錄,使用如下命令進行移動
sudo mv /home/sunftp/ftpdir/hadoop-2.7.7 /usr/如下圖所示:

21、用同樣辦法拷貝到slave2上。
22、在兩個slave上執行16~17步。
23、在master主機上執行,此時使用hadoop使用者登入通過如下命令進行格式化
hdfs namenode -format此時會出現兩個異常
8/12/25 00:45:19 WARN namenode.NameNode: Encountered exception during format:
java.io.IOException: Cannot remove current directory: /usr/hadoop-2.7.7/hdfs/name/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:335)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:564)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:585)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:179)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1015)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1457)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1582)
18/12/25 00:45:19 ERROR namenode.NameNode: Failed to start namenode.
java.io.IOException: Cannot remove current directory: /usr/hadoop-2.7.7/hdfs/name/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:335)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:564)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:585)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:179)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1015)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1457)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1582)
18/12/25 00:45:19 INFO util.ExitUtil: Exiting with status 1
如下圖所示:

24、意思是對/usr/hadoop-2.7.7/hdfs/name/current目錄沒有寫入許可權,只需使用如下命令新增寫入許可權:
sudo chmod -R 777 /usr/hadoop-2.7.7為保持一致,也需要在slave1和slave2上執行,然後再次格式化,如下圖所示:


25、在master上開啟hadoop,使用start-all.sh 啟動,如下圖所示:

26、然後輸入yes回車,然後只要是出現此介面都輸入yes即可,如下圖所示:

27、然後在master節點上輸入jps命令檢視hadoop程序,此時master主節點有4個ResourceManager,Jps, NameNode, SecondaryNamenode,如下圖所示:

28、兩個從節點slave1和slave2的hadoop程序,如下圖所示:
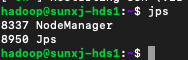
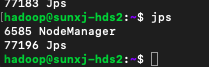
29、正常情況應該還有一個DataNode程序,但是此處沒有啟動,這種情況分為兩種原因,一種是第一次格式化後第一次啟動,slave1和slave2上沒有DataNode程序,另一種已經啟動過一次或者多次重新格式化後在slave1和slave2上沒有DataNode程序,下面分兩種情況分析:
第一種情況:
(1)只需要在slave1和slave2上更改hdfs-site.xml 配置檔案,由於兩個從節點上的hadoop是從master節點拷貝過的,因此需要單獨更改兩個節點上的hdfs-site.xml 檔案,通過如下命令進行編輯slave1節點上的配置檔案:
sudo vim /usr/hadoop-2.7.7/etc/hadoop/hdfs-site.xml 如下圖所示:
更改為:

(2)在slave2上也是同樣的修改,儲存退出。
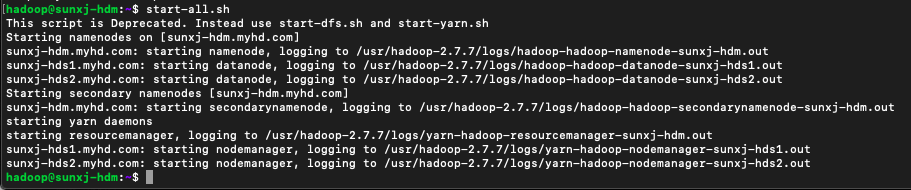
(3)在master節點上在次啟動hadoop即可,如下圖所示:
(4)檢視master節點程序,如下圖所示:
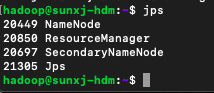
slave1節點的程序,如下圖所示:
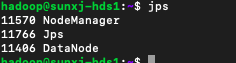
slave2節點的程序,如下圖所示:
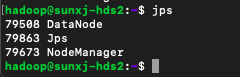
(5)到此hadoop叢集環境安裝完畢。
第二種情況:
此種情況有3個方法來解決:
(1)將slave1和slave2上/usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/VERSION檔案中的clusterID替換到master上/usr/hadoop-2.7.7/hdfs/name/current/VERSION檔案中的clusterID
<1> 先暫停master上的hadoop,輸入如下指令停止:
stop-all.sh 如下圖所示:

<2> 檢視master、slave1和slave2程序情況,如下圖所示:
master程序:
![]()
slave1程序:
![]()
slave2程序:
![]()
<3> 說明hadoop已停止,現在重新格式化,如下圖所示:

<4> 然後在master啟動hadoop,檢視slave1和slave2的程序情況,如下圖所示:
slave1程序:
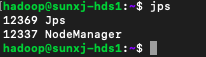
slave2程序:

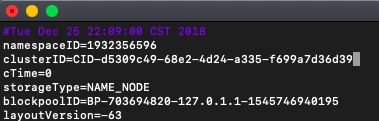
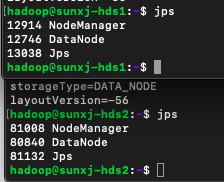
<5> 由此可以看出只要重新格式化後就無法啟動DataNode程序,現在先停止hadoop,然後來檢視master上、slave1、slave2上的clusterID, 在master上有兩個地方有clusterID,位置在:
/usr/hadoop-2.7.7/hdfs/name/current/VERSION
/usr/hadoop-2.7.7/hdfs/tmp/dfs/namesecondary/current/VERSION檢視的clusterID如下圖所示,此時有多處的值不同

<6> slave1和slave2上的clusterID的位置在:
/usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/VERSION檢視的clusterID如下圖所示,由圖可知兩臺上的clusterID是相同的,也與master上的/usr/hadoop-2.7.7/hdfs/tmp/dfs/namesecondary/current/VERSION中的clusterID相同。

<7> 我們先將master上的/usr/hadoop-2.7.7/hdfs/name/current/VERSION位置的clusterID值更改為slave節點上的clusterID(注意:先將原來的ID儲存,以便將master上的clusterID替換到slave上),使用如下命令進行編輯:
<8> 儲存退出,然後啟動hadoop,然後檢視slave1和slave2上的程序已經有DataNode程序了,如下圖所示:
(2)將master上/usr/hadoop-2.7.7/hdfs/name/current/VERSION檔案中的clusterID替換到slave1和slave2上/usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/VERSION檔案中的clusterID
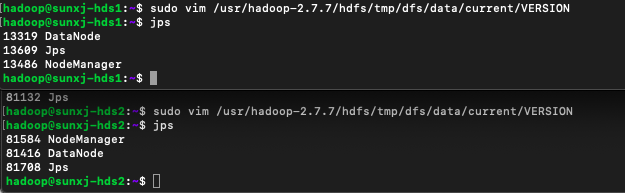
<1>先停止master上的hadoop,然後將儲存下來的clusterID替換master、slave1和slave2上在master使用如下命令編輯:
sudo vim /usr/hadoop-2.7.7/hdfs/name/current/VERSION在slave1和slave2上使用如下命令編輯:
sudo vim /usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/VERSION<2>在master啟動hadoop,然後檢視slave1和slave2上的程序已經有DataNode程序了,如下圖所示:
(3)還有可以將slave1和slave2的檔案刪除/usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/目錄中的VERSION檔案刪除,首先停止hadoop,然後再次格式化,並將VERSION刪除,在啟動hadoop,然後檢視slave1和slave2上的程序已經有DataNode程序了,如下圖所示:

(4)由以上3中辦法中只有第一種是最方便的,由於重新格式化後只有master節點上與其他的slave節點clusterID不同,而所有的slave的clusterID是相同的,因此只需要更改一處即可,而第二種和第三種方法都需要操作多臺機才行。
七、用自帶的樣例測試hadoop叢集能不能正常跑任務
1、使用如下命令測試:
hadoop jar /usr/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10此命令是用來求圓周率,pi是類名,第一個10表示Map次數,第二個10表示隨機生成點的次數,由於是在一臺機器虛擬出了3個系統來執行,所以計算這個有點久,目前是在執行狀態,如下圖所示:

用這個命令運行了一天,結果還是這個狀態,不知道怎麼回事。
2、現在使用另一個測試,hadoop自帶的wordcount例子,這個是統計單詞個數的,首先要在hdfs系統中建立資料夾,要檢視hdfs系統可以通過hadoop fs -ls來檢視hdfs系統的檔案以及目錄情況,如下圖所示:

3、使用如下命令在hdfs中建立一個word_count_input資料夾:
hadoop fs -mkdir word_count_input如下圖所示:

4、然後使用如下命令在本地建立兩個檔案file1.txt和file2.txt:
sudo vim file1.txt然後在file1.txt輸入如下內容,由此可以看到:hello 5,hadoop 4,sunxj 2 win 1:
hello hadoop
hello sunxj
hello hadoop
hello hadoop
hello win
sunxj hadoop在file2.txt輸入如下內容,由此可以看到:hello 2,linux 2,window 2:
linux window
hello linux
hello window如下圖所示:
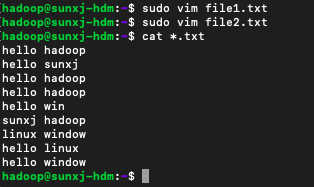
由此可以計算出world的個數分別為:hello有7個,hadoop有4,sunxj有2個,win有1個inux,有2個,window有2個。
5、通過如下命令將file1.txt和file2.txt檔案上傳到hdfs系統的word_count_input資料夾中:
hadoop fs -put file*.txt word_count_input如下圖所示:

6、然後使用如下命令執行wordcount:
hadoop jar /usr/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount word_count_input word_count_output其中wordcount是類名,word_count_input是輸入資料夾目錄,word_count_output是輸出目錄,如下圖所示:

7、在圖中出現了拒絕連線:
18/12/26 20:51:23 INFO client.RMProxy: Connecting to ResourceManager at sunxj-hdm.myhd.com/192.168.0.109:18040
18/12/26 20:51:24 INFO input.FileInputFormat: Total input paths to process : 2
18/12/26 20:51:24 INFO mapreduce.JobSubmitter: number of splits:2
18/12/26 20:51:25 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545828647598_0001
18/12/26 20:51:25 INFO impl.YarnClientImpl: Submitted application application_1545828647598_0001
18/12/26 20:51:25 INFO mapreduce.Job: The url to track the job: http://sunxj-hdm.myhd.com:18088/proxy/application_1545828647598_0001/
18/12/26 20:51:25 INFO mapreduce.Job: Running job: job_1545828647598_0001
18/12/26 20:57:28 INFO mapreduce.Job: Job job_1545828647598_0001 running in uber mode : false
18/12/26 20:57:28 INFO mapreduce.Job: map 0% reduce 0%
18/12/26 20:57:28 INFO mapreduce.Job: Job job_1545828647598_0001 failed with state FAILED due to: Application application_1545828647598_0001 failed 2 times due to Error launching appattempt_1545828647598_0001_000002. Got exception: java.net.ConnectException: Call From sunxj-hdm/127.0.0.1 to localhost:37113 failed on connection exception: java.net.ConnectException: 拒絕連線; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.GeneratedConstructorAccessor47.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:732)
at org.apache.hadoop.ipc.Client.call(Client.java:1480)
at org.apache.hadoop.ipc.Client.call(Client.java:1413)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy83.startContainers(Unknown Source)
at org.apache.hadoop.yarn.api.impl.pb.client.ContainerManagementProtocolPBClientImpl.startContainers(ContainerManagementProtocolPBClientImpl.java:96)
at sun.reflect.GeneratedMethodAccessor14.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy84.startContainers(Unknown Source)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.launch(AMLauncher.java:118)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.run(AMLauncher.java:250)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.ConnectException: 拒絕連線
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.