
hadoop開發環境搭建
作業系統 :Ubuntu 15.04
開發工具 : Eclipse 4.4
hadoop版本:hadoop 2.6.1
安裝hadoop
1.將hadoop的壓縮包解壓,推薦在home/使用者名稱/下,用usr/lib的話,會出現許可權問題,導致eclipse連線不上的情況出現,這裡選擇在home/使用者名稱/下建立
2.解壓完成後就需要配置環境變量了
在命令列中輸入sudo gedit /etc/environment開啟環境變數
輸入如下內容
HADOOP_HOME=/home/pengchen/hadoop
並在path的末尾,新增上之前解壓的hadoop地址
/home/pengchen/hadoop/bin:/home/pengchen/hadoop/sbin
最後在命令列中輸入source /etc/environment使配置生效
3.配置SSH無密碼登陸
當然先安裝ssh
於命令列輸入sudo apt-get install ssh ,安裝完成後就是配置了
配置無密碼登陸本機:
在當前使用者目錄下即/home/使用者名稱/下新建隱藏檔案.ssh,輸入命令:
mkdir .ssh
接下來,輸入命令:
ssh-keygen -t dsa -P ” -f ~/.ssh/id_dsa
這個命令會在.ssh資料夾下建立兩個檔案id_dsa及id_dsa.pub,這是一 對私鑰和公鑰,然後把id_dsa.pub(公鑰)追加到授權的key裡面去,輸入命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
驗證ssh已安裝成功及無密碼登陸本機,輸入命令:
ssh -version
顯示結果:
Bad escape character ‘rsion’.
這樣顯示代表ssh已經安裝成功。
登陸ssh,輸入命令:
ssh localhost
第一次登陸可能會詢問是否繼續連結,輸入yes即可,以後登陸直接登進去。

顯示結果:
Welcome to Ubuntu 15.04 (GNU/Linux 3.19.0-15-generic x86_64)
* Documentation: https://help.ubuntu.com/
287 packages can be updated.
0 updates are security updates.
Last login: Tue Oct 27 22:52:04 2015 from localhost
4.安裝JDK
先去官網下載JDK,linux用
之後再usr/lib下新建一個資料夾,不建也行,直接將JDK解壓到usr/lib下即可
之後就是配置環境變量了,和hadoop的環境變數一樣
JAVA_HOME=/usr/lib/java_1.8.0/jdk1.8.0_65 解壓位置
/usr/lib/java_1.8.0/jdk1.8.0_65/bin,在path後輸入
最後輸入 source /etc/environment使配置生效5.配置linux的jdk,輸入以下命令,會讓選用哪個jdk,選擇即將在編譯外掛中使用的jdk,一定要選對,否則後面可能跑不起來,注,下面的命令只針對當前使用者,切換後別的使用者就會失效
#安裝目錄 #jdk中的java目錄
update-alternatives --install /usr/bin/java java /usr/java/bin/java 300 6.配置hadoop
1.單機模式,不需要任何配置,即可馬上執行
2.偽分佈模式
在使用者目錄下新建一個hadoop_tmp資料夾,用來存放之後的一些執行資訊,下面出現的目錄都可以按照需要修改,不過得保證該目錄存在
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/pengchen/hadoop_tmp</value>
</property>
</configuration>
修改hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/pengchen/hadoop/dfs/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/pengchen/hadoop/dfs/datanode</value>
<final>true</final>
</property>
<property>
<name>dfs.http.address</name>
<value>localhost:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>file:/home/pengchen/hadoop/mapred/system</value>
<final>true</final>
</property>
<property>
<name>mapred.local.dir</name>
<value>file:/home/pengchen/hadoop/mapred/local</value>
<final>true</final>
</property>
</configuration>
修改yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
<description>hostname of Resource Manager</description>
</property>
</configuration>
7.以上步驟完成後,就是啟動hadoop了
cd到hadoop的安裝目錄下
首先是格式化hadoop
./bin/hdfs namenode -format等待格式化完成後,啟動
./sbin/start-all.sh等待命令列輸入完成後,輸入jps,如果出現下面的顯示,就代表執行成功了
pengchen@ubuntu:~/hadoop$ jps
Picked up JAVA_TOOL_OPTIONS: -javaagent:/usr/share/java/jayatanaag.jar
3403 NodeManager
3433 Jps
3123 SecondaryNameNode
2920 DataNode
2801 NameNode
3278 ResourceManager
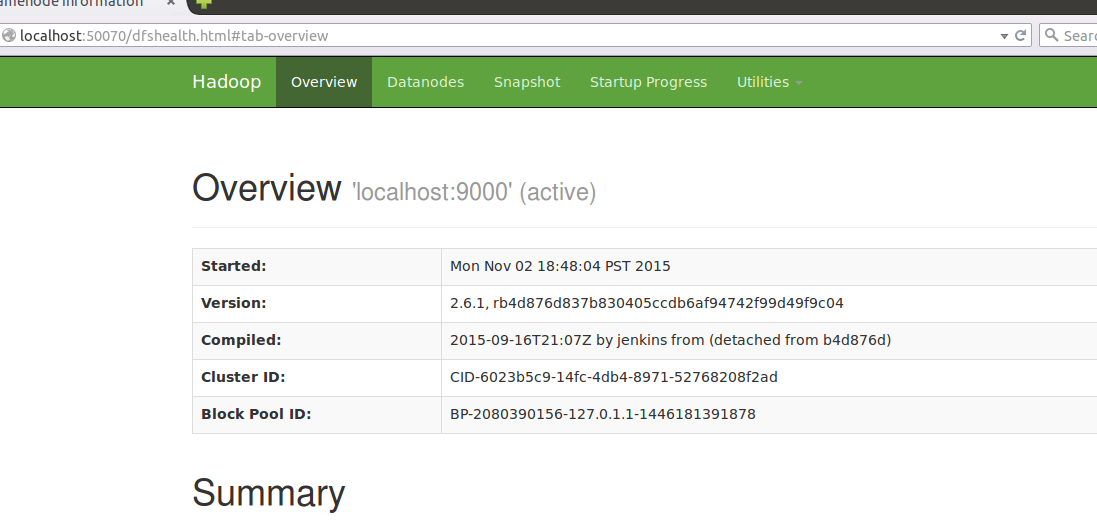
7.web登陸
在hadoop啟動狀態下,於瀏覽器輸入localhost:50070即可登入web介面
- 編譯hadoop用eclipse外掛
1.首先毫無疑問是安裝eclipse,於命令列輸入
umake ide eclipse第一次可能會提示安裝umake,按照提示安裝即可,之後,再輸入一遍上面的指令,速度可能很慢,耐心等待即可,安裝地址會再輸入指令後顯示出來,不滿意可以修改
2.安裝完成後,開啟eclipse,並新建一個專案,將之前下載的eclipse外掛的原始碼拖到該專案下
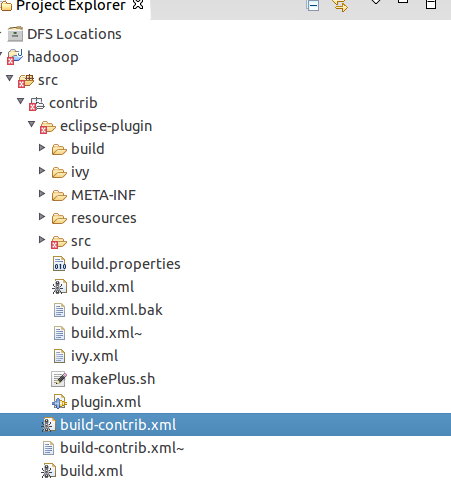
3.開啟src/contrib下的build-contrib.xml輸入以下內容,涉及到目錄的請按照自己的安裝目錄填寫,版本資訊一樣,一定要填對,否則編譯的東西可能不能用,不同的環境可能造成外掛出現問題,務必保證環境一致
<property name="jdk.home" value="/usr/lib/java_1.8.0/jdk1.8.0_65" />
<property name="hadoop.version" value="2.6.1" />
<property name="jackson.version" value="1.9.13" />
<property name="hadoop.home" value="/home/pengchen/hadoop" />
<property name="eclipse.version" value="4.4" />
<property name="eclipse.home" value="/home/pengchen/tools/ide/eclipse" />
<property name="root" value="${basedir}" />
<property file="${root}/build.properties" />
<property name="name" value="${ant.project.name}" />
<property name="src.dir" location="${root}/src" />
<property name="build.contrib.dir" location="${root}/build/contrib" />
<property name="build.dir" location="${build.contrib.dir}/${name}" />
<property name="build.classes" location="${build.dir}/classes" />
<property name="javac.deprecation" value="off" />
<property name="javac.debug" value="on" />
<property name="build.encoding" value="UTF-8" /> 新增完成後,選到build.xml檔案,選run as ant file,等待完成
完成後將外掛放在eclipse安裝目錄的plugin資料夾下,重啟eclipse,如果成功載入外掛,就會在介面上顯示一個小像圖,如下圖,如果沒成功,就跳轉到eclipse安裝目錄用eclipse -clean啟動一下試試,如果還不行,就刪除eclipse安裝目錄下的configuration/org.eclipse.update資料夾試試
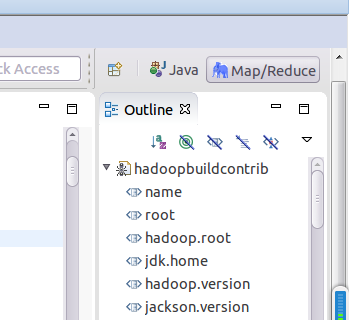
成功後接下來是配置,選擇windows/preference,選擇hadoop選項,將之前的安裝目錄填上即可
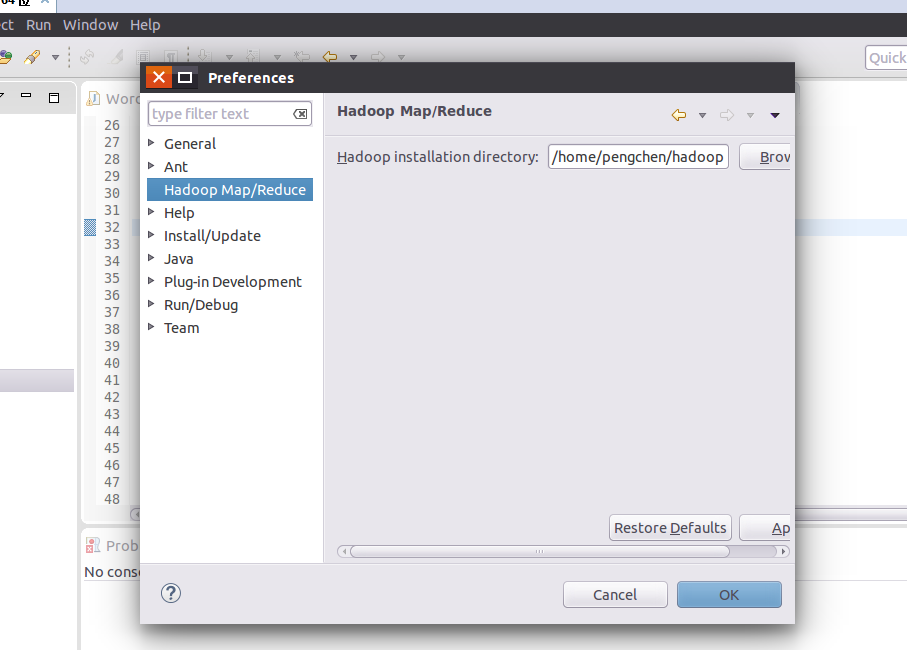
選擇新建專案-map/reduce project,之後hadoop外掛會自行把hadoop下的庫都導進去,之後,應該會在projectExplorer中看到多出一個DFS LOCATION選項,這裡就是用來配置需要連線的hadoop地址
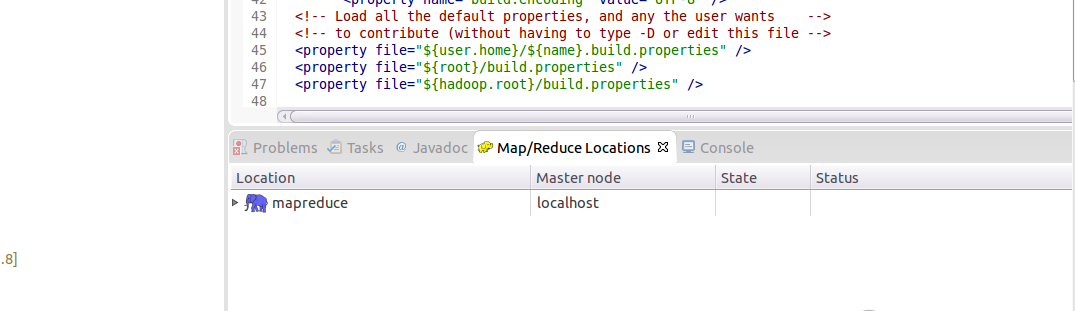
選擇Map/Reduce Locations選項卡,並右鍵點選,新建一個location
會彈出如下對話方塊:
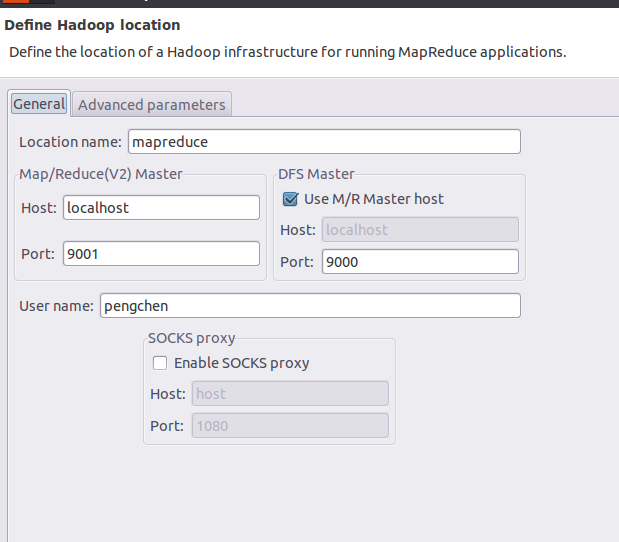
填上名字,左邊對應mapred-site.xml中填寫的資訊,右邊對應core-site.xml中填寫的資訊,之後點選確定即可
這樣在dfs location中顯示出連結的資訊,最開始時,如果沒有命令列配置過輸入輸出目錄的話,就是空的,不要在意自行填上輸入輸出資料夾,命令列,或者eclipse都行
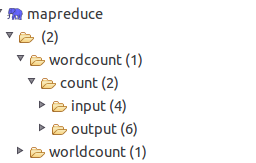
這樣開發環境就搭建完成了
ps:一些簡單的命令列
1.檢視檔案列表,dir對應目錄
hadoop fs -ls dir
2.從本地上傳至hdfs
hadoop fs -copyFromLocal input/hello.txt /input/hello.txt
3.從hdfs下載至本地
hadoop fs -copyToLocal /input/hello.txt input/hello.copy.txt
4.建立資料夾
hadoop fs -mkdir testDir
5.檢視hdfs檔案列表
hadoop fs -lsr /testDir
6.檢視結果
hadoop fs -cat /resultDir
7.執行jar,目錄對應自己本地環境的目錄,輸入輸出目錄同理
hadoop jar /usr/local/hadoop2.4.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.0.jar wordcount input output
8.停止hadoop
.sbin/stop-all.sh注意事項:
1.不要多次輸入格式化命令會導致datanode起不來,解決方法是hadoop安裝目錄下的dfs資料夾下的datanode和namenode資料夾,再次格式化,並啟動hadoop
2.如果在執行程式時發現log4j未打log,解決方法是將hadoop安裝目錄下etc/log4j.properties拖入到對應的專案/src資料夾下即可解決log問題
3.如果出現hadoop顯示無法連線,或者無法顯示問題,可能是對應的編譯外掛的環境與執行環境不一致導致的,請換用一致環境,即可解決,自己windows編譯的放在linux下死活通不過,換了linux一次ok,所以保持一致環境可以保證成功