
1.1JVM記憶體結構——堆、棧、方法區、直接記憶體、堆和棧區別
一、定義
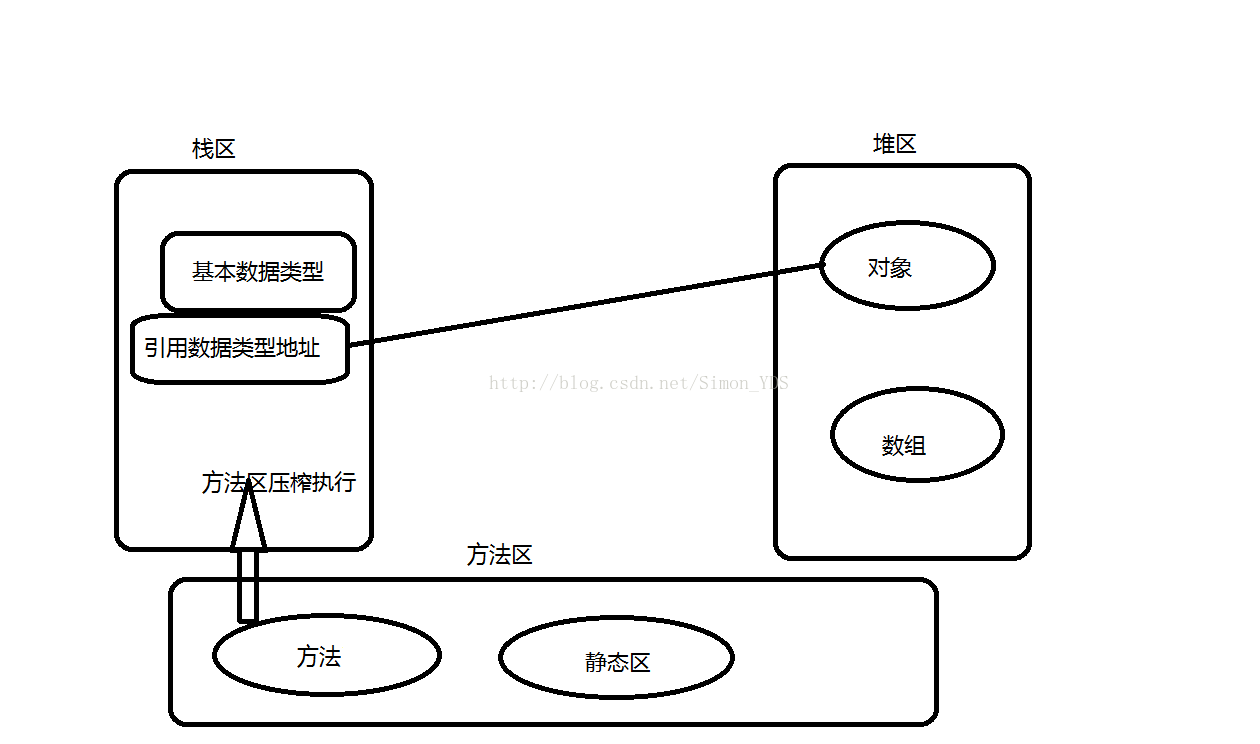
1、堆:FIFO佇列優先,先進先出。jvm只有一個堆區被所有執行緒所共享!堆存放在二級快取中,呼叫物件的速度相對慢一些,生命週期由虛擬機器的垃圾回收機制定。
2、棧:FILO先進後出,暫存資料的地方。每個執行緒都包含一個棧區!棧存放在一級快取中,存取速度較快,“棧是限定僅在表頭進行插入和刪除操作的線性表”。
3、方法區:用來存放方法和static變數。
二、儲存的資料型別
1、堆用來儲存new出來的物件和陣列
2、棧用來儲存基本型別變數和物件的引用變數的地址
3、方法區儲存方法和static變數
三、優缺點
1、堆的優點-可以動態的分配記憶體大小,生命週期不確定。缺點-速度略慢
2、棧的優點-速度快,缺點-存在棧中的資料大小和生命週期必須是明確的,缺少靈活性。
四、直接記憶體
直接記憶體並不是虛擬機器執行時資料區的一部分,也不是Java 虛擬機器規範中農定義的記憶體區域。在JDK1.4 中新加入了NIO(New Input/Output)類,引入了一種基於通道(Channel)與緩衝區(Buffer)的I/O 方式,它可以使用native 函式庫直接分配堆外記憶體,然後通脫一個儲存在Java堆中的DirectByteBuffer 物件作為這塊記憶體的引用進行操作。這樣能在一些場景中顯著提高效能,因為避免了在Java堆和Native堆中來回複製資料。
本機直接記憶體的分配不會受到Java 堆大小的限制,受到本機總記憶體大小限制
配置虛擬機器引數時,不要忽略直接記憶體 防止出現OutOfMemoryError異常
直接記憶體(堆外記憶體)與堆記憶體比較
- 直接記憶體申請空間耗費更高的效能,當頻繁申請到一定量時尤為明顯
- 直接記憶體IO讀寫的效能要優於普通的堆記憶體,在多次讀寫操作的情況下差異明顯
程式碼驗證:
package com.xnccs.cn.share;
import java.nio.ByteBuffer;
/**
* 直接記憶體 與 堆記憶體的比較
*/
public class ByteBufferCompare {
public static void main(String[] args) {
allocateCompare(); //分配比較
operateCompare(); //讀寫比較
}
/**
* 直接記憶體 和 堆記憶體的 分配空間比較
*
* 結論: 在資料量提升時,直接記憶體相比非直接內的申請,有很嚴重的效能問題
*
*/
public static void allocateCompare(){
int time = 10000000; //操作次數
long st = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
//ByteBuffer.allocate(int capacity) 分配一個新的位元組緩衝區。
ByteBuffer buffer = ByteBuffer.allocate(2); //非直接記憶體分配申請
}
long et = System.currentTimeMillis();
System.out.println("在進行"+time+"次分配操作時,堆記憶體 分配耗時:" + (et-st) +"ms" );
long st_heap = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
//ByteBuffer.allocateDirect(int capacity) 分配新的直接位元組緩衝區。
ByteBuffer buffer = ByteBuffer.allocateDirect(2); //直接記憶體分配申請
}
long et_direct = System.currentTimeMillis();
System.out.println("在進行"+time+"次分配操作時,直接記憶體 分配耗時:" + (et_direct-st_heap) +"ms" );
}
/**
* 直接記憶體 和 堆記憶體的 讀寫效能比較
*
* 結論:直接記憶體在直接的IO 操作上,在頻繁的讀寫時 會有顯著的效能提升
*
*/
public static void operateCompare(){
int time = 1000000000;
ByteBuffer buffer = ByteBuffer.allocate(2*time);
long st = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
// putChar(char value) 用來寫入 char 值的相對 put 方法
buffer.putChar('a');
}
buffer.flip();
for (int i = 0; i < time; i++) {
buffer.getChar();
}
long et = System.currentTimeMillis();
System.out.println("在進行"+time+"次讀寫操作時,非直接記憶體讀寫耗時:" + (et-st) +"ms");
ByteBuffer buffer_d = ByteBuffer.allocateDirect(2*time);
long st_direct = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
// putChar(char value) 用來寫入 char 值的相對 put 方法
buffer_d.putChar('a');
}
buffer_d.flip();
for (int i = 0; i < time; i++) {
buffer_d.getChar();
}
long et_direct = System.currentTimeMillis();
System.out.println("在進行"+time+"次讀寫操作時,直接記憶體讀寫耗時:" + (et_direct - st_direct) +"ms");
}
}
輸出:
在進行10000000次分配操作時,堆記憶體 分配耗時:12ms
在進行10000000次分配操作時,直接記憶體 分配耗時:8233ms
在進行1000000000次讀寫操作時,非直接記憶體讀寫耗時:4055ms
在進行1000000000次讀寫操作時,直接記憶體讀寫耗時:745ms
可以自己設定不同的time 值進行比較
分析
從資料流的角度,來看
非直接記憶體作用鏈:
本地IO –>直接記憶體–>非直接記憶體–>直接記憶體–>本地IO
直接記憶體作用鏈:
本地IO–>直接記憶體–>本地IO
直接記憶體使用場景
- 有很大的資料需要儲存,它的生命週期很長
- 適合頻繁的IO操作,例如網路併發場景
參考
《深入理解Java虛擬機器》 –周志明