
蟲師帶你入門Chrome Headless,從此爬蟲0門檻!
阿新 • • 發佈:2019-01-03
爬蟲終結者 Chrome Headless
簡介
- 自從Google官方釋出了Chrome瀏覽器的無形態模式之後,
PhantomJS維護者 Vitaly Slobodin 隨即在郵件列表上宣佈辭職,可見該模式的影響力,那麼下面小編帶大家快速入門如何使用該技術實現資料抓取,可以說掌握這套技術能夠應對90%的網站,從此爬蟲0門檻。
安裝
Chrome Headless 配置
- 開啟chrome瀏覽器,位址列輸入
chrome://version/,需要版本59.0以上 - Mac配置如下(
vim ~/.bashrc):
alias chrome="/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome" - 配置完成後記得
$ source ~/.bashrc - 在終端執行
$ start_chrome_server,可以看到如下圖所示,且有一個新的瀏覽器開啟: ps. 如果按照上面沒有操作成功或者其他系統配置,可以看這裡

相關庫安裝
$ sudo pip install pychrome或者
$ git clone https://github.com/MrPaoBrother/headless_spider.git
實戰
ps. 因為所有的操作都是模擬瀏覽器進行操作,所以執行前必須先開啟chrome headless:$ start_chrome_server
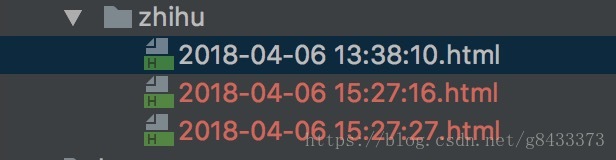
知乎自動化爬蟲
- 上面原始碼下載好了之後,在根目錄下執行:
$ python run_zhihu.py執行成功後可以看到知乎網站在不停的下滑重新整理,直到最後一頁。
結果:
法治線上自動翻頁爬蟲
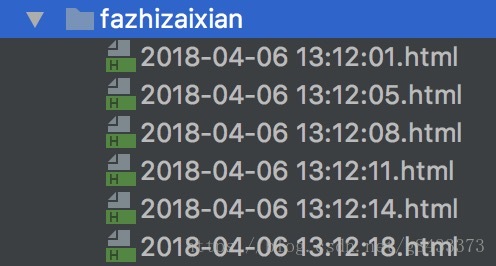
- 上面原始碼下載好了之後,在根目錄下執行:
$ python run_fazhizaixian.py執行成功後可以看到頁面會自動翻頁且會在最後一頁停住,完全自動化。
結果:
豆瓣模擬登陸爬蟲
上面原始碼下載好了之後,在原始碼中填入自己的
豆瓣賬號用於模擬登陸:
之後在根目錄執行
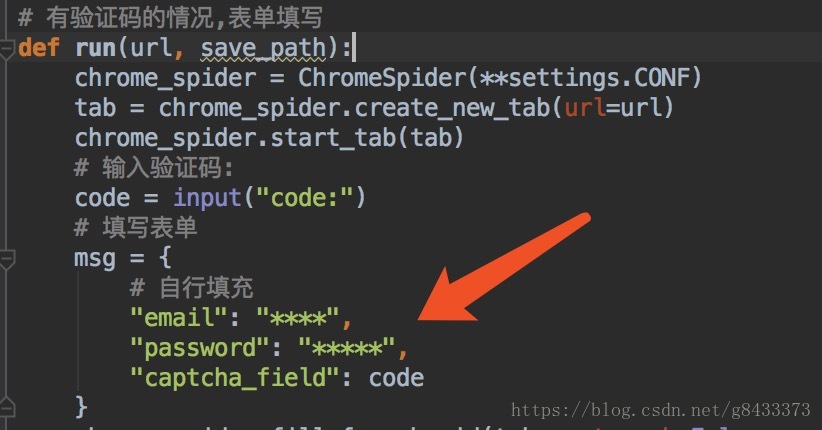
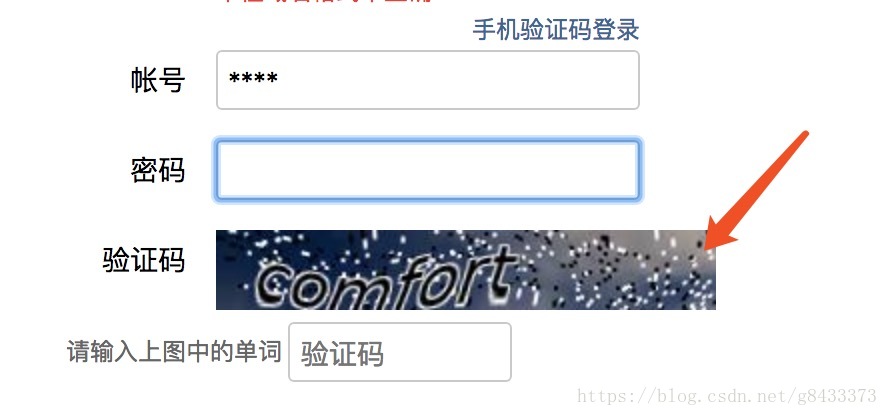
$ python run_douban.py- 有些時候需要驗證碼,注意控制檯需要填寫
code:這裡按照自己看到的填就行:
- 成功的話,我們可以看到幾秒之後瀏覽器自動進入豆瓣電影頁面進行自動翻頁爬蟲了。
- 結果:
核心程式碼簡介
- 下載頁面
def download_html(self, url=None, delay=1, tab=None, disable_css=False, close_tab=True):
"""
返回一個頁面的html
:param tab: 頁面物件,預設為空,自己會自動建立一個
:param url: 傳入的url
:param delay: 下載延遲
:param disable_css: 是否禁止CSS
:param close_tab: 每次爬完是否關閉tab
:return:
"""
try:
if tab is None:
tab = self.create_new_tab(url=url)
self.start_tab(tab)
tab.wait(timeout=delay)
html = self.exec_js_cmd(tab, js_cmd.DOWNLOAD_HTML)
if disable_css:
self.disable_css(tab=tab)
if html is not None:
html = html["result"]["value"]
if close_tab:
self.close_tab(tab)
return html
except Exception as e:
print "download_html error:", e
self.close_tab(tab)
return None- 該函式是整個框架的核心函式,爬蟲的
核心也就是將瀏覽器上看到的使用者資訊抓取下來,其中我這裡只給出了一部分功能即delay(控制下載延遲),disable_css(下載時候是否需要css資源),close_tab(每次抓取後是否關閉網頁),原始碼中 還封裝了很多其他功能,讀者可以自行挖掘,理論上來說只要你能在瀏覽器上看到的東西基本都能抓下來,就是控制delay這個引數就行。
總結
- 該技術通常用來獲取一些
資料加密網站的方法,對一般的靜態網站抓取成本較高,因為在時間上相對來說慢一些,大家可以試著用該框架爬下淘寶,京東等網站,小編有測試過,也是沒什麼問題的,最後希望大家給我點個贊或者在專案中給個star!