R語言實現關聯規則與推薦演算法(學習筆記)
R語言實現關聯規則
筆者前言:以前在網上遇到很多很好的關聯規則的案例,最近看到一個更好的,於是便學習一下,寫個學習筆記。
推薦演算法中
物品-物品用關聯規則;
人物-物品用協同過濾;
人-人用社會網路分析;
特徵-物品用預測建模,分類模型。(本總結來自CDA DSC相關課程)
關聯規則和協同過濾演算法
關聯規則,將所有使用者的高頻產品進行推薦,但是如果要清倉,清除一些低頻的產品,關聯規則不太適用;而協同過濾可以顧及長尾。
————————————————————————————————————————————————————————————
一、關聯規則資料規則
1、資料格式
關聯規則需要把源資料的格式轉換為稀疏矩陣。
把上表轉化為稀疏矩陣,1表示訪問,0表示未訪問。
| Session ID | News | Finance | Entertainment | Sports |
| 1 | 1 | 1 | 0 | 0 |
| 2 | 1 | 1 | 0 | 0 |
| 3 | 1 | 1 | 0 | 1 |
| 4 | 0 | 0 | 0 | 0 |
| 5 | 1 | 1 | 0 | 1 |
| 6 | 1 | 0 | 1 | 0 |
2、關聯規則專業術語項集 ItemSet
這是一條關聯規則:
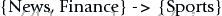
括號內的Item集合稱為項集。如上例,{News, Finance}是一個項集,{Sports}也是一個項集。
這個例子就是一條關聯規則:基於歷史記錄,同時看過News和Finance版塊的人很有可能會看Sports版塊。
{News,Finance} 是這條規則的Left-hand-side (LHS or Antecedent)
{Sports}是這條規則的Right-hand-side (RHS or Consequent)
LHS(Left Hand Side)的項集和RHS(Right Hand Side)的項集不能有交集。
二、關聯規則強度指標
1、支援度——商品出現頻次
項集的支援度就是該項集出現的次數除以總的記錄數(交易數)。
Support({News}) = 5/6 = 0.83
Support({News, Finance}) = 4/6 =0.67
Support({Sports}) = 2/6 = 0.33
支援度的意義在於度量項集在整個事務集中出現的頻次。我們在發現規則的時候,希望關注頻次高的項集。
2、置信度——兩商品同時發生概率
關聯規則 X -> Y 的置信度 計算公式
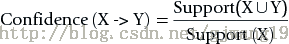
規則的置信度的意義在於項集{X,Y}同時出現的次數佔項集{X}出現次數的比例。發生X的條件下,又發生Y的概率。
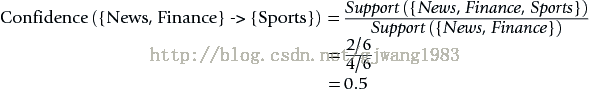
表示50%的人 訪問過{News, Finance},同時也會訪問{Sports}
3、提升度——兩商品獨立性
當右手邊的項集(consequent)的支援度已經很顯著時,即時規則的Confidence較高,這條規則也是無效的。
舉個例子:
在所分析的10000個事務中,6000個事務包含計算機遊戲,7500個包含遊戲機遊戲,4000個事務同時包含兩者。
關聯規則(計算機遊戲,遊戲機遊戲) 支援度為0.4,看似很高,但其實這個關聯規則是一個誤導。
在使用者購買了計算機遊戲後有 (4000÷6000)0.667 的概率的去購買遊戲機遊戲,而在沒有任何前提條件時,使用者反而有(7500÷10000)0.75的概率去購買遊戲機遊戲,也就是說設定了購買計算機遊戲這樣的條件反而會降低使用者去購買遊戲機遊戲的概率,所以計算機遊戲和遊戲機遊戲是相斥的。
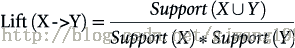
所以要引進Lift這個概念,Lift(X->Y)=Confidence(X->Y)/Support(Y)
規則的提升度的意義在於度量項集{X}和項集{Y}的獨立性。即,Lift(X->Y)= 1 表面 {X},{Y}相互獨立。[注:P(XY)=P(X)*P(Y),if X is independent of Y]
如果該值=1,說明兩個條件沒有任何關聯,如果<1,說明A條件(或者說A事件的發生)與B事件是相斥的,一般在資料探勘中當提升度大於3時,我們才承認挖掘出的關聯規則是有價值的。
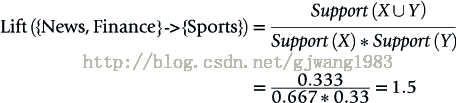
最後,lift(X->Y) = lift(Y->X)
4、出錯率——規則預測精度
Conviction的意義在於度量規則預測錯誤的概率。
表示X出現而Y不出現的概率。
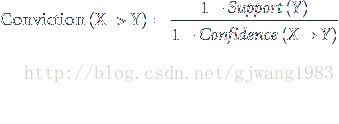
例子:

表面這條規則的出錯率是32%。
三、關聯規則核心演算法——Apriori演算法
如果項集A是頻繁的,那麼它的子集都是頻繁的。如果項集A是不頻繁的,那麼所有包括它的父集都是不頻繁的。
例子:{X, Y}是頻繁的,那麼{X},{Y}也是頻繁的。如果{Z}是不頻繁的,那麼{X,Z}, {Y, Z}, {X, Y, Z}都是不頻繁的。
生成頻繁項集
給定最小支援度Sup,計算出所有大於等於Sup的項集。
第一步,計算出單個item的項集,過濾掉那些不滿足最小支援度的項集。
第二步,基於第一步,生成兩個item的項集,過濾掉那些不滿足最小支援度的項集。
第三步,基於第二步,生成三個item的項集,過濾掉那些不滿足最小支援度的項集。
如下例子(頻繁項集):
| One-Item Sets | Support Count | Support |
| {News} | 5 | 0.83 |
| {Finance} | 4 | 0.67 |
| {Entertainment} | 1 | 0.17 |
| {Sports} | 2 | 0.33 |
| Two-Item Sets | Support Count | Support |
| {News, Finance} | 4 | 0.67 |
| {News, Sports} | 2 | 0.33 |
| {Finance, Sports} | 2 | 0.33 |
| Three-Item Sets | Support Count | Support |
| {News, Finance, Sports} | 2 | 0.33 |
四、R語言實現關聯規則
可參考該部落格:http://blog.csdn.net/gjwang1983/article/details/45015203
貼一些實現的圖:
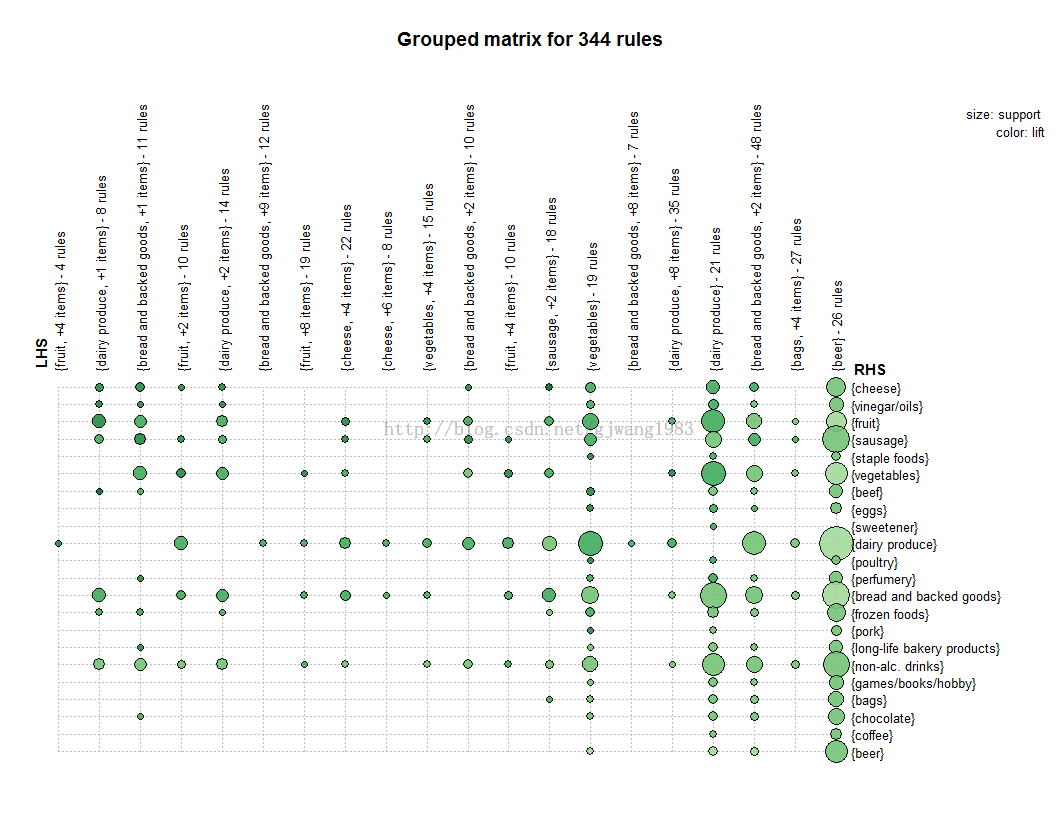
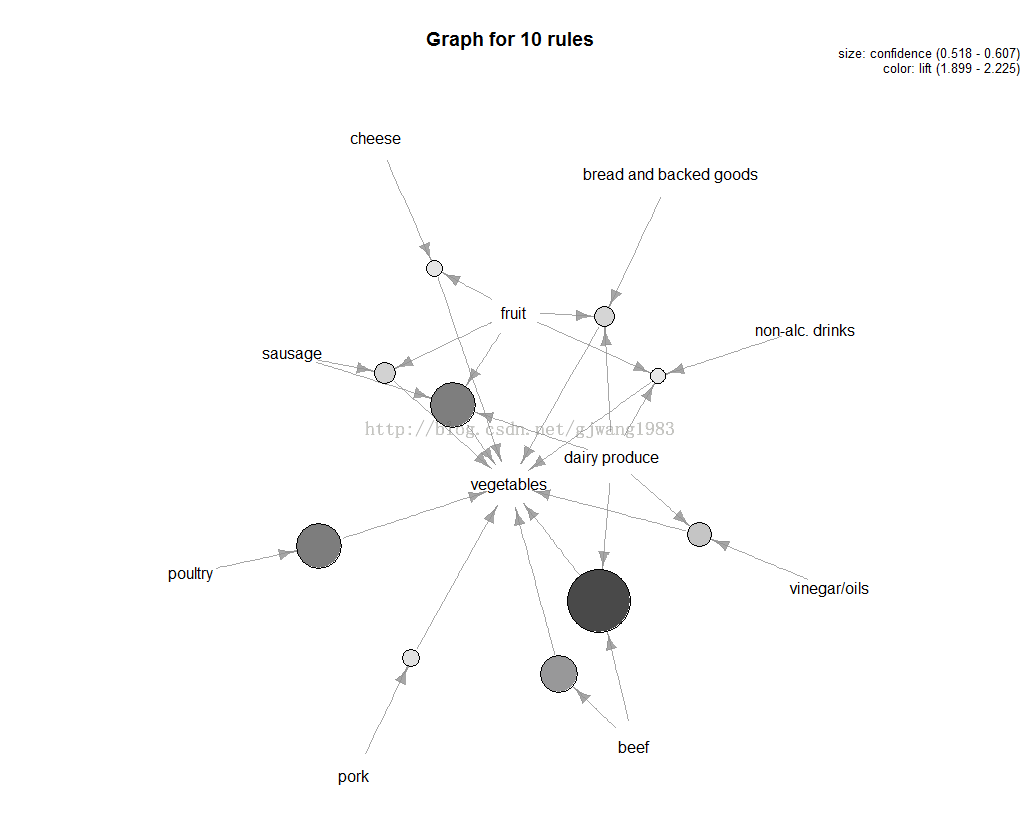
________________________________________________________________________________________
五、關聯規則的推薦案例解讀
1、支援度、置信度、提升度用法
本總結來自CDA DSC相關課程三個指標,支援度、置信度、提升度的用法。
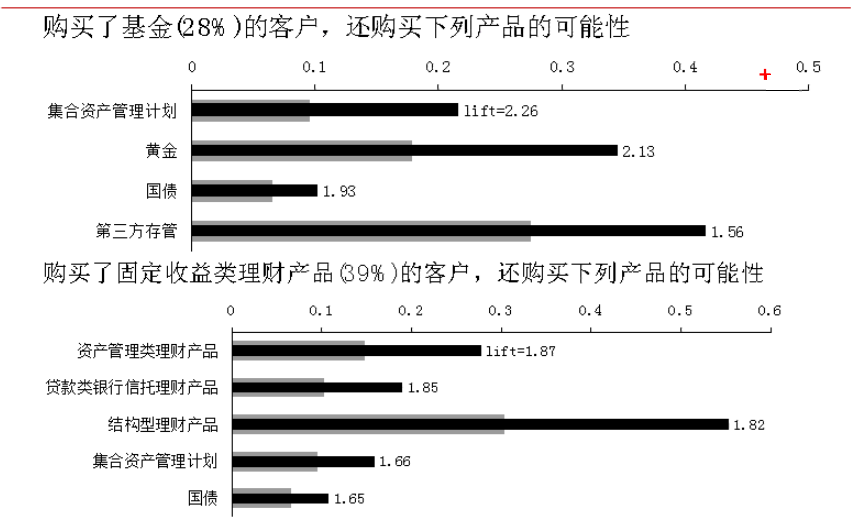
本圖的解讀,
第一幅上圖,買了基金的人還買了黃金的佔0.35,所有的人中買了黃金的有18%(基準),此時提升度為0.35/0.18=1.94>1,可以作為推薦;
作為客戶要衝銷量,則選擇面向基數大的部分,則選擇支援度、置信度大的,比如第一張圖的第三方存管,第二圖的結構性理財產品。
所以三個指標的基本用法:沖銷量、KPI會重點關注置信度大的;隨機推薦用提升度。
2、網商時代關聯規則背棄長尾效應
在實際案例運用過程中關聯規則與協同過濾的區別在於,
關聯規則推薦的是本來就很熱門的產品,因為代表同時發生頻率越高,關聯性越強。在網商時代會背棄長尾效應,讓差異擴大,2/8定律會一定程度上擴充至1/9,助長馬太效應。
一般要推薦冷門產品會使用協同過濾。下圖就是京東上使用關聯規則的例子。