
【Python】打響2019年第一炮-Python爬蟲入門(一)
打響2019第一炮-Python爬蟲入門
2018年已經成為過去,還記得在2018年新年寫過一篇【Shell程式設計】打響2018第一炮-shell程式設計之for迴圈語句,那在此時此刻,也是寫一篇關於程式設計方面,不過要比18年的稍微高階點。 So,mark一下,也希望對您有所幫助。
進入正題,在雙十一想必大家都逛過淘寶and京東,比如我們需要買一部手機或電腦,但是我們需要點開手機或者電腦頁面看需要購買的商品價格,型號,評論,等等資訊。 你沒有聽錯,本章目的獲取京東商城手機&電腦的資料,包括價格,評論,型號等資訊。
一、認識爬蟲
1.1、什麼是爬蟲?
爬蟲:一段自動抓取網際網路資訊的程式,從網際網路上抓取對於我們有價值的資訊。
1.2、Python爬蟲架構
- 排程器:相當於一臺電腦的CPU,主要負責排程URL管理器、下載器、解析器之間的協調工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重複抓取URL和迴圈抓取URL,實現URL管理器主要用三種方式,通過記憶體、資料庫、快取資料庫來實現。
- 網頁下載器:通過傳入一個URL地址來下載網頁,將網頁轉換成一個字串,網頁下載器有urllib2(Python官方基礎模組)包括需要登入、代理、和cookie,requests(第三方包)
- 網頁解析器:將一個網頁字串進行解析,可以按照我們的要求來提取出我們有用的資訊,也可以根據DOM樹的解析方式來解析。網頁解析器有正則表示式(直觀,將網頁轉成字串通過模糊匹配的方式來提取有價值的資訊,當文件比較複雜的時候,該方法提取資料的時候就會非常的困難)、html.parser(Python自帶的)、beautifulsoup(第三方外掛,可以使用Python自帶的html.parser進行解析,也可以使用lxml進行解析,相對於其他幾種來說要強大一些)、lxml(第三方外掛,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 樹的方式進行解析的。
- 應用程式:就是從網頁中提取的有用資料組成的一個應用。
下面用一個圖來解釋一下排程器是如何協調工作的:
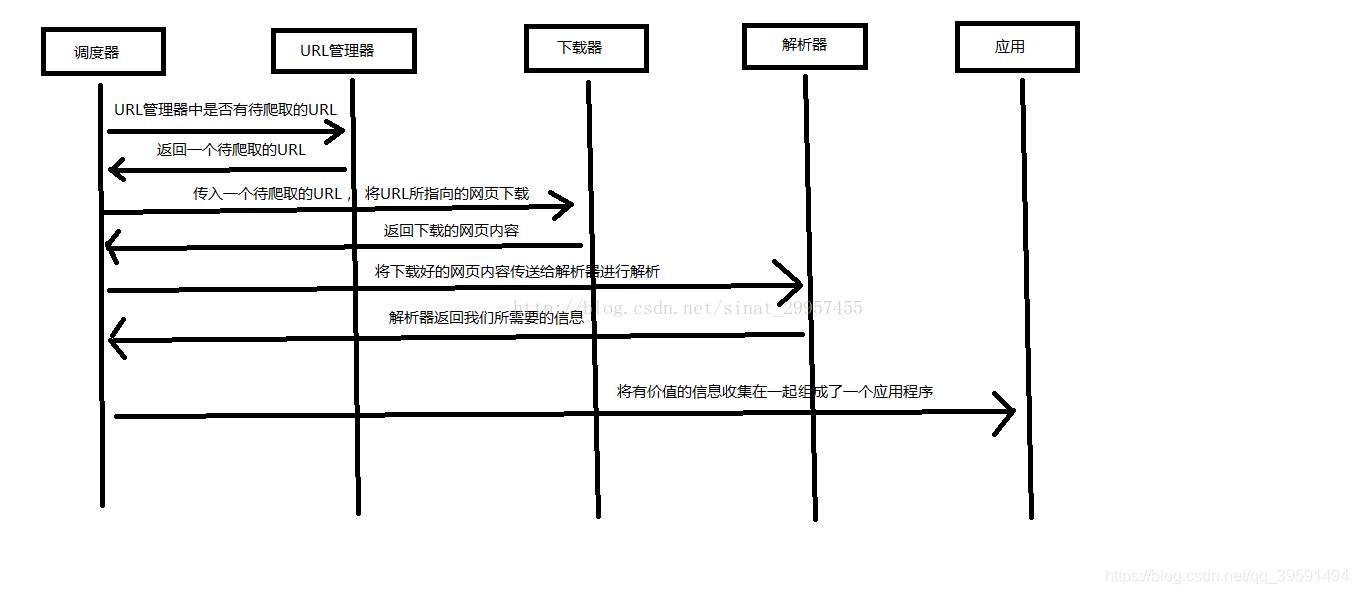
以上內容來自:http://www.runoob.com/w3cnote/python-spider-intro.html
二、訓練爬蟲
訓練自己爬蟲的技巧,從簡單的網頁開始,掌握多種技能(語言,html,css,js等等),在訓練的過程中積累經驗,逐漸可以爬取任意型別的網站。
2.1、爬前準備
2.1.1、爬蟲類型
- 小爬:各種庫來爬
- 中爬:框架
- 大爬:搜尋引擎
2.1.2、目的
- 解決資料來源的問題
- 做行業分析
- 完成自動化操作
- 做搜尋引擎
2.1.3、目標型別
- 新聞/部落格/微博
- 圖片
- 新聞
- 評論
- 電影視訊
- 視訊
- 評論
- 音樂
- 音訊
- 評論
三、開始爬蟲
本章為爬蟲入門,所以我們只需要安裝幾個Python庫即可,如下:
-
requests | pip install requests -
bs4 | pip install bs4 -
lxml | pip install lxml
3.1、Python之requests庫
快速上手
requests已安裝requests最新版
讓我們從一些簡單的示例開始吧。
3.1.1、傳送請求
我們每天訪問百度,其實就是一次請求,這個requests作用其實就是使用程式碼模擬我們人類給網站傳送了一次請求。 首先我們需要匯入requests庫 如下:
In [2]: import requests # 匯入requests庫
匯入之後我們就可以使用requests庫中的方法了,例如我們需要獲取我csdn某一篇文章。
r = requests.get('https://blog.csdn.net/qq_39591494/article/details/85331388')
現在,我們有一個名字為:r的Response響應物件,也就是我們訪問網站,網站肯定會給我們資料。一些引數如下:
In [4]: r.status_code # 檢視訪問狀態碼 200為ok 是成功的
Out[4]: 200
In [5]: r.headers # 檢視響應頭部
Out[5]:
{'Server': 'openresty',
'Date': 'Tue, 01 Jan 2019 06:52:56 GMT',
'Content-Type': 'text/html; charset=UTF-8',
'Transfer-Encoding': 'chunked',
'Connection': 'keep-alive',
'Keep-Alive': 'timeout=20',
'Set-Cookie': 'uuid_tt_dd=10_7631126010-1546325576025-268248; Expires=Thu, 01 Jan 2025 00:00:00 GMT; Path=/; Domain=.csdn.net;, dc_session_id=10_1546325576025.334557; Expires=Thu, 01 Jan 2025 00:00:00 GMT; Path=/; Domain=.csdn.net;',
'Vary': 'Accept-Encoding',
'Content-Encoding': 'gzip', 'Strict-Transport-Security': 'max-age= 31536000'}

r.request.headers # 請求頭
Out[6]: {'User-Agent': 'python-requests/2.20.0',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'keep-alive'}
Requests簡便的API意味著所有HTTP請求型別都是顯而易見的。例如,你可以這樣傳送一個HTTP POST請求:
r = requests.post("http://httpbin.org/post")
漂亮,對吧?那麼其他HTTP請求型別:PUT, DELETE, HEAD以及OPTIONS又是如何的呢?都是一樣的簡單:
In [11]: r = requests.put("http://httpbin.org/put")
In [12]: r = requests.delete("http://httpbin.org/delete")
n [13]: r = requests.head("http://httpbin.org/get")
In [14]: r = requests.options("http://httpbin.org/get")
在這裡http://httpbin.org/只是一個測試網站
3.1.2、Json響應內容
若網站響應的內容為json格式那麼requests中也有一個內建的JSON解碼器,助你處理JSON資料:
In [21]: r = requests.get('http://httpbin.org/json')
In [22]: r.status_code
Out[22]: 200
In [23]: r.json()
Out[23]:
{'slideshow': {'author': 'Yours Truly',
'date': 'date of publication',
'slides': [{'title': 'Wake up to WonderWidgets!', 'type': 'all'},
{'items': ['Why <em>WonderWidgets</em> are great',
'Who <em>buys</em> WonderWidgets'],
'title': 'Overview',
'type': 'all'}],
'title': 'Sample Slide Show'}}
如何檢視返回原始碼?
In [25]: r = requests.get('http://httpbin.org/')
In [26]: r.status_code
Out[26]: 200
In [27]: r.text
更多requests內容請參考:http://docs.python-requests.org/zh_CN/latest/#
3.2、Python爬蟲利器二之Beautiful Soup的用法
簡單來說,Beautiful Soup 是python的一個庫,最主要的功能是從網頁抓取資料。官方解釋如下:
Beautiful Soup提供一些簡單的、python式的函式用來處理導航、搜尋、修改分析樹等功能。它是一個工具箱,通過解析文件為使用者提供需要抓取的資料,因為簡單,所以不需要多少程式碼就可以寫出一個完整的應用程式Beautiful Soup自動將輸入文件轉換為Unicode編碼,輸出文件轉換為utf-8編碼。你不需要考慮編碼方式,除非文件沒有指定一個編碼方式,這時,Beautiful Soup就不能自動識別編碼方式了。然後,你僅僅需要說明一下原始編碼方式就可以了Beautiful Soup已成為和lxml、html6lib一樣出色的python直譯器,為使用者靈活地提供不同的解析策略或強勁的速度。
3.2.1、Beautiful Soup安裝
Beautiful Soup 3 目前已經停止開發,推薦在現在的專案中使用Beautiful Soup 4,不過它已經被移植到BS4了,也就是說匯入時我們需要 import bs4 。所以這裡我們用的版本是 Beautiful Soup 4.3.2 (簡稱BS4)。
bs4已安裝bs4最新版
下表列出了主要的解析器,以及它們的優缺點:
| 解析器 | 使用方法 | 優勢 | 劣勢 |
|---|---|---|---|
| Python標準庫 | BeautifulSoup(markup, “html.parser”) | Python的內建標準庫,執行速度適中,文件容錯能力強 | Python 2.7.3 or 3.2.2)前 的版本中文件容錯能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文件容錯能力強 | 需要安裝C語言庫 |
| lxml XML 解析器 | BeautifulSoup(markup, “xml”)、BeautifulSoup(markup, [“lxml”, “xml”]) | 速度快、唯一支援XML的解析器 | 需要安裝C語言庫 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容錯性、以瀏覽器的方式解析文件、生成HTML5格式的文件 | 速度慢、不依賴外部擴充套件 |
以下內容通過soup物件呼叫
| 方法/屬性 | 含義 | 示例 |
|---|---|---|
| prettify() | 漂亮的格式化列印內容 | soup.prettify() |
| text | 返回標籤裡面的字串 | soup.text |
| tag | html 文件中的標籤名 | soup.head、soup.title、soup.p等 |
| find() | 返回第一個找到的物件 | soup.find(‘a’) |
| find_all() | 返回所有找到的物件 | soup.find_all(‘a’) |
| get() | 根據soup裡面物件的屬性取到資料,類似字典。 | for link soup.find_all(‘a’): —> print(‘link.get(‘href’)’) |
本章內容重點學習find & find_all即可, 案例程式碼
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
查詢所有關於title標籤
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
title = soup.find_all('title')
print(title)
>>> [<title>The Dormouse's story</title>]
查詢所有的p標籤
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
p = soup.find_all('p')
print(p)
>>>
[<p class="title"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <p class="story">...</p>]
查詢p標籤中的title
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
p = soup.find_all('p', 'title')
print(p)
>>> [<p class="title"><b>The Dormouse's story</b></p>]
查詢a標籤
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
a = soup.find_all('a')
print(a)
>>>
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
查詢id="link2"標籤
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
link = soup.find_all(id="link2")
print(link)
>>> [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
查詢所包含id屬性的tag
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
link = soup.find_all(id=True)
print(link)
>>>
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
使用多個指定名字的引數可以同時過濾tag的多個屬性:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
link = soup.find_all(href=re.compile("lacie"), id="link2")
print(link)
>>> [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
按CSS搜尋
按照CSS類名搜尋tag的功能非常實用,但標識CSS類名的關鍵字class在Python中是保留字,使用 class 做引數會導致語法錯誤.從Beautiful Soup的4.1.1版本開始,可以通過class_ 引數搜尋有指定CSS類名的tag。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
CLS = soup.find('a', class_ = "sister")
print(CLS)
>>> <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
CLS = soup.find_all('a', class_ = "sister")
print(CLS)
>>>
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
結合正則查詢
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
CLS = soup.find(class_ = re.compile("ti"))
print(CLS)
>>> <p class="title"><b>The Dormouse's story</b></p>
完全匹配 class 的值時,如果CSS類名的順序與實際不符,將搜尋不到結果:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
CLS = soup.find('p', attrs={'class':'title'})
print(CLS)
>>> <p class="title"><b>The Dormouse's story</b></p>
更多關於Beautiful Soup內容:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
3.3、開始正題
經過以上的鋪墊,現在正式開始寫程式碼,我們需要獲取京東的電腦資料,首先我們需要開啟京東網站去搜索電腦如下:
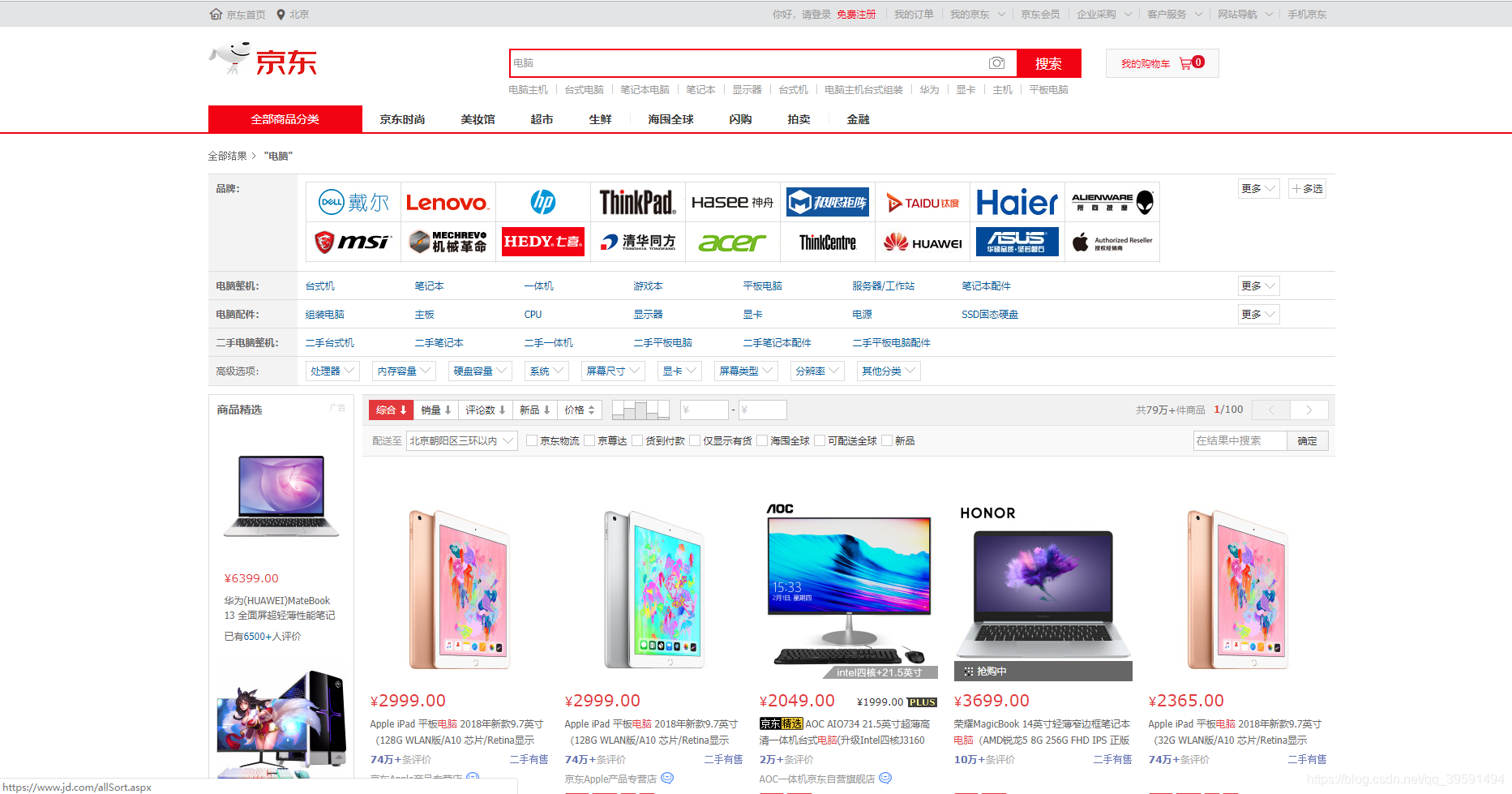
3.3.1、選擇其中一臺電腦選擇右鍵檢查


我們目的是需要取京東這一個頁面上所有的電腦資料,包括價格,評論,名稱等資料,那麼在取所有資料之前我們第一步應該需要取第一臺電腦的資料,如下:
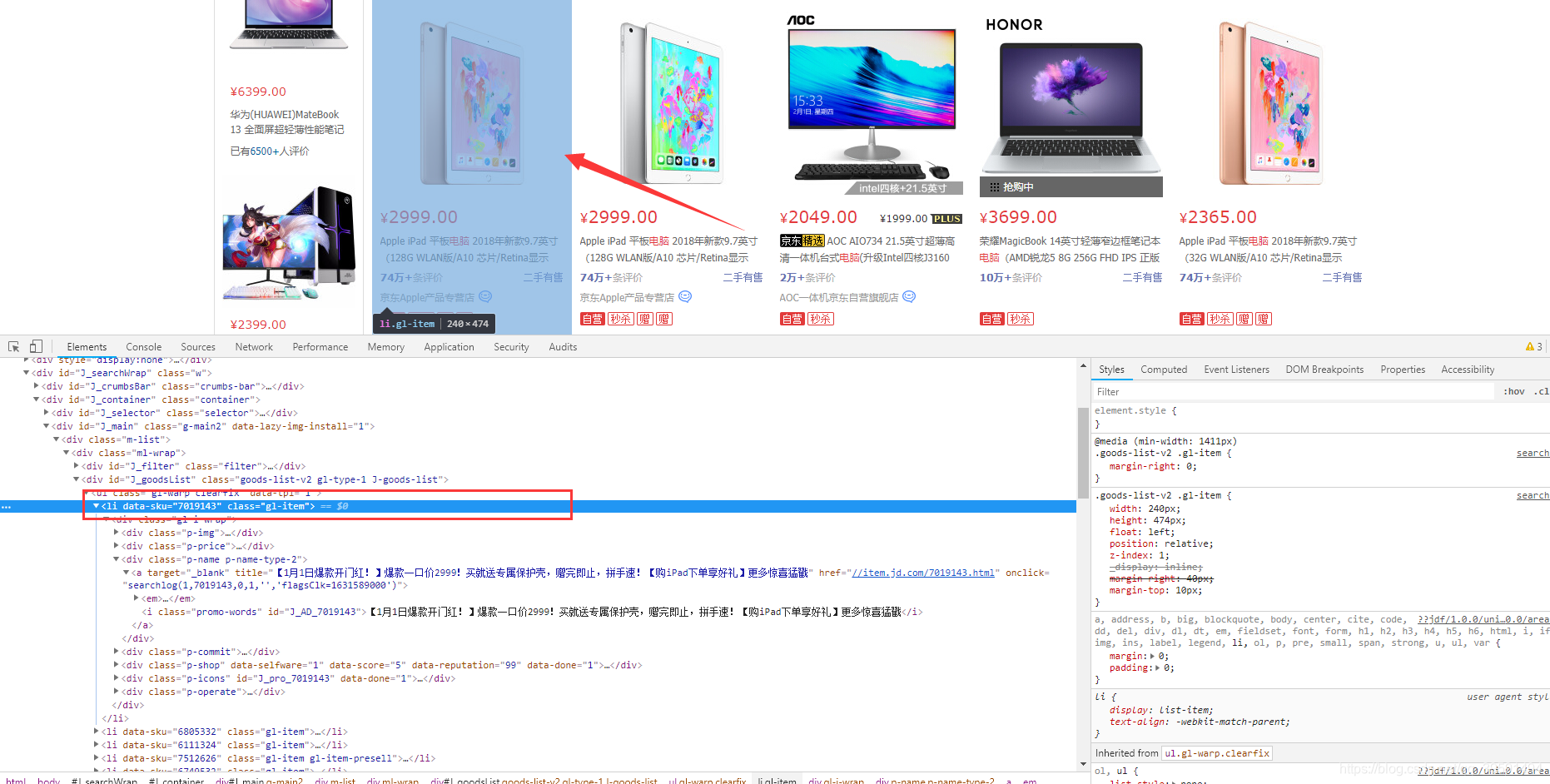
當我們選中Li標籤時,頁面會將水印指定到第一臺電腦上,如果我們選擇第二個Li標籤呢? 如下:
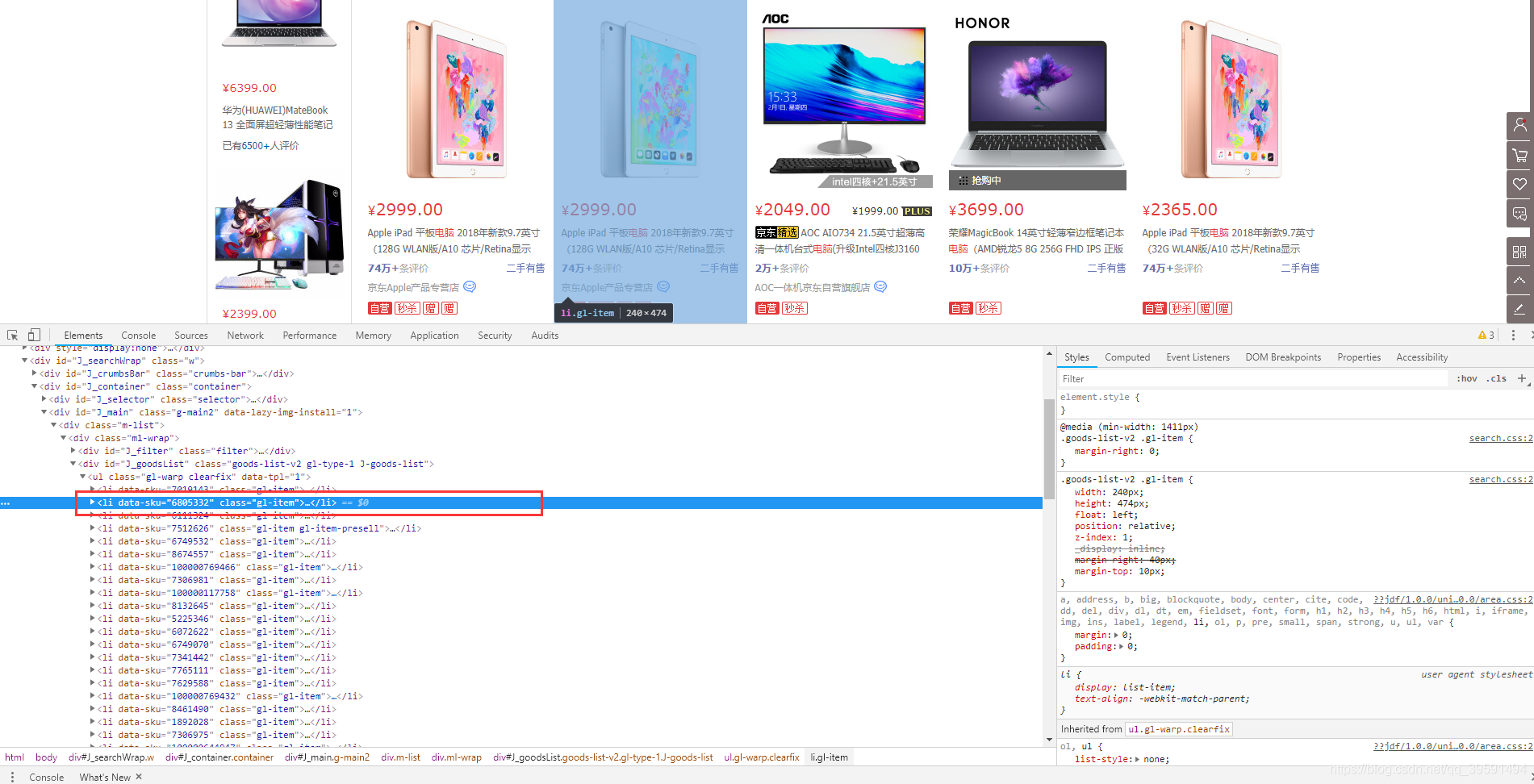
因此可以得出,在目前此頁面中每一臺電腦的資料都在< li data-sku >標籤中。將< li data-sku >程式碼拷貝。選中< Li data-sku=“6805332”>—>右鍵—>Copy—>Copy elemrent. 內容如下:
<li data-sku="6805332" class="gl-item">
<div class="gl-i-wrap">
<div class="p-img">
<a target="_blank" title="【1月1日爆款開門紅!】爆款一口價2999!買就送專屬保護殼,贈完即止,拼手速!【購iPad下單享好禮】更多驚喜猛戳" href="//item.jd.com/6805332.html" onclick="searchlog(1,6805332,1,2,'','flagsClk=1631589000')">
<img width="220" height="220" class="" data-img="1" source-data-lazy-img="" data-lazy-img="done" src="//img12.360buyimg.com/n7/jfs/t16759/298/1134242689/85617/2b4ccc02/5abb0fd5Nd40c72e1.jpg">
</a> <div data-lease="" data-catid="2694" data-venid="1000000127" data-presale="" data-done="1"></div>
</div>
<div class="p-price">
<strong class="J_6805332" data-done="1"><em>¥</em><i>2999.00</i></strong> </div>
<div class="p-name p-name-type-2">
<a target="_blank" title="【1月1日爆款開門紅!】爆款一口價2999!買就送專屬保護殼,贈完即止,拼手速!【購iPad下單享好禮】更多驚喜猛戳"