LR(Logistic Regression) 邏輯迴歸模型 進行二分類或多分類 及梯度下降學習引數
阿新 • • 發佈:2019-01-02
邏輯迴歸(Logistic Regression, LR)是傳統機器學習中的一種分類模型,由於演算法的簡單和高效,在實際中應用非常廣泛。它的起源非常複雜,可以看參考引用1。具體應用實踐可以看這裡。
問題背景
對於二元分類問題,給定一個輸入特徵向量(例如輸入一張圖片,通過演算法識別它是否是一隻貓的圖片),演算法能夠輸出預測,稱之為,也就是對實際值的估計。或者說,表示等於1的一種可能性或是置信度(前提條件是給定了輸入特徵)。
如果代入帶線性迴歸的模型中:

假設輸入為腫瘤大小,上圖表示值大於0.5時演算法預測為惡性腫瘤,小於0.5時預測為良性腫瘤。看上去好像沒有什麼問題,但是在 值大於1或者小於0的地方不能很好地表示分類的置信度。再者看下圖:

如果新加入了一個樣本點(最右),那麼預測很可能就會如上圖不是很準確了,惡性腫瘤的前幾個樣本點會被線性迴歸模型判定為良性腫瘤。因此我們引入sigmoid函式:
LR模型
Sigmoid函式

從上圖可以看到sigmoid函式是一個s形的曲線,它的取值在[0, 1]之間,在0點取值為0.5,在遠離0的地方函式的值會很快接近0或是1。這個性質使我們能夠以概率的方式來解釋分類的結果。
所以對應條件概率分佈(二分類)為
引數求解
那麼我們該如何求救裡面的引數呢?常用的方法有梯度下降法,牛頓法和BFGS擬牛頓法。
梯度下降法
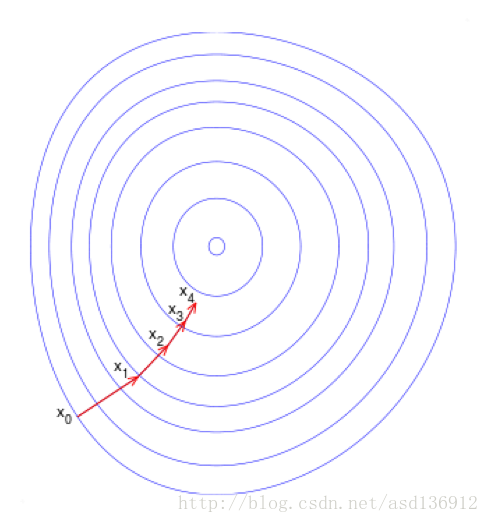
梯度下降(Gradient Descent)又叫作最速梯度下降,是一種迭代求解的方法,通過在每一步選取使目標函式變化最快的一個方向調整引數的值來逼近最優值。基本步驟如下:
- 選擇下降方向(梯度方向,)
- 選擇步長,更新引數
- 重複以上兩步直到滿足終止條件
我們首先定義一下損失函式Loss Function,如果我們使用常用的平方損失函式:
得到的函式影象如下左圖,非凸函式有許多區域性最小值,將會影響梯度下降尋找全域性最小值。
所以我們定義Lost Function為
Cost Function (衡量演算法在全部樣本上的表現) 為: