機器學習 - 整合方法(Bagging VS. Boosting 以及隨機森林、AdaBoost)
機器學習 - 整合方法(Bagging VS. Boosting 以及隨機森林)
-
整合方法
整合(Ensemble)方法就是針對同一任務,將多個或多種分類器進行融合,從而提高整體模型的泛化能力。
對於一個複雜任務,將多個模型進行適當地綜合所得出的判斷,通常要比任何一個單獨模型的判讀好。也就是我們常說的“三個臭皮匠,頂過諸葛亮”。
不過對於組合分類器必須滿足兩點:
(1) 基模型之間應該是相互獨立的
(2) 基模型應好於隨機猜測模型整合方法目前分為兩種:Bagging 與 Boosting,下面分別介紹。
-
Bagging
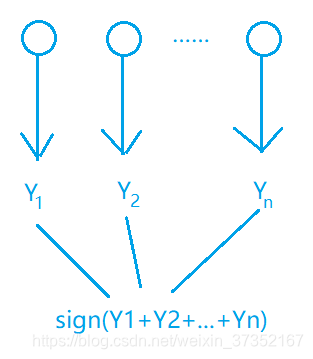
Bagging(Bootstrap aggregating),又稱裝袋演算法,它提供了一種非常直接的整合學習演算法,即通過從完整資料集中抽取不同的子集餵給各個模型進行訓練,最後將所有模型整合在一起,對被預測樣本進行投票決定其所屬類別。
-
Bagging 分類:
(1) 如果抽取的資料子集是從完整資料集抽取出的隨機子集中再次抽取(先從完整資料集中抽取子集 A,再從子集 A 中抽取子集 B 作為訓練集),成稱為 Pasting
(2) 如果從完整資料集抽取的子集是有放回的(每次抽取都是從相同的完整資料集中選取),稱為 Boostrap
(3) 如果抽取的資料集是特徵的子集(n 個特徵中挑出一部分特徵,而樣本數量與完整資料集相等),稱為隨機子空間 (Random Sub Spaces)
(4) 如果同時對樣本和特徵都做抽取子集,稱為隨機補丁 (Random Patches)
其中對於 Boostrap,最終完成樣本抽樣後有 36.8% 的資料未被抽到。計算方法:
假設共有 n 個樣本,每個樣本不被抽到的概率為 ,
抽取 n 次都不被抽到的概率為 ,當 時,
根據重要極限 ,
求得:
-
Bagging 的預測:
(1) 對於分類任務,使用簡單投票法,即每個分類器一票進行投票(也可以進行概率平均);
(2) 對於迴歸任務,採用簡單平均獲取最終結果,即取所有分類器的平均值;
在 Bagging 方法中,所有的模型具有相同的權重,即 “完全民主決策”。
-
-
Boosting
提升(Boosting)方法,是通過改變訓練樣本的權重,學習多個模型,並將這些模型進行線性組合,從而提高效能。
-
兩個定義
“強可學習”:對於一個任務,若存在一個多項式的學習演算法能夠學習它,且正確率很高,則稱此學習演算法為強可學習(Strongly Learnable)
“若可學習”:對於一個任務,若存在一個多項式的學習演算法能夠學習它,但正確率僅比隨機猜測好,則稱此學習演算法為弱可學習(Weakly Learnable)
對於這兩個概念,後來證明,弱可學習與強可學習是等價的。如此,問題就轉換成了:若一發現“弱學習演算法”,那麼能否將它提升為“強學習演算法”。
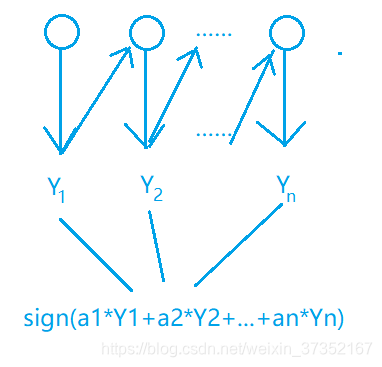
提升方法就是從弱學習演算法出發,反覆學習,得到一系列弱模型(基模型),然後組合這些弱模型構成一個強模型。
-
兩個問題
(1) 每一輪如何修改訓練資料的權值(概率分佈)
答:提高上一輪預測錯誤的樣本的權值,降低上一輪預測正確的樣本的權值,如此,預測錯誤的樣本會得到更大的關注。
(2) 如何將弱模型組合成一個強模型
答:使用加權多數表決。加大錯誤率小的弱模型的權值,減小錯誤率高的弱模型的權值,以此修改它們表決中產生的影響。
Boosting 中,每個模型的權重不一樣。
-
-
Bagging VS. Boosting
專案 Bagging Boosting 方法 ① 訓練只使用部分資料、特徵;②多個模型多數表決 ①訓練基模型,而後學習上一輪的錯誤;② 多個模型線性加權 流程 見圖 - Bagging 流程 見圖 - Boosting 流程 偏 / 方差 主要降低方差,防止過擬合 主要降低偏差,提高準確度 適用範圍 高噪聲 低噪聲 權重 所有訓練資料權重相同,所有基模型權重相同 訓練資料權重不同,每個基模型權重不同 串 / 並行 並行(同時訓練多個基模型) 序列(依賴上一輪模型結果) 例 Random Forest GBDT