
獲取Keras模型中間層輸出
使用Keras可以比較方便地搭建一些深度學習網路,獲取中間層輸出可以幫助理解它是如何執行的。這裡使用一個小型的Keras網路,對Caltech101資料集進行影象分類,並獲取中間層輸出結果,以及手工計算卷積層的輸出結果。
修正:表示當前是訓練模式還是測試模式的引數K.learning_phase()文中表述和使用有誤,在該函式說明中可以看到:
The learning phase flag is a bool tensor (0 = test, 1 = train),所以0是測試模式,1是訓練模式,部分網路結構下兩者有差別。
我使用的版本:
1. WIN7系統
2. Python 2.7.10.2
3. Keras 2.0.8
4. Theano 0.9.0
5. numpy 1.13.1
6. h5py 2.5.0
7. OpenCV 2.4.13
在ubuntu中也可執行,需要修改檔案路徑,並且如果在ubuntu中使用的後端是tensorflow,後面的kernel不需要翻轉。我的Keras設定中總是:"image_data_format": "channels_last"。
參考資料:
2. cs231n_2017_lecture5
從資料夾中提取影象資料的方式:
函式:
def eachFile(filepath): #將目錄內的檔名放入列表中 pathDir = os.listdir(filepath) out = [] for allDir in pathDir: child = allDir.decode('gbk') # .decode('gbk')是解決中文顯示亂碼問題 out.append(child) return out def get_data(data_name,train_left=0.0,train_right=0.7,train_all=0.7,resize=True,data_format=None,t=''): #從資料夾中獲取影象資料 file_name = os.path.join(pic_dir_out,data_name+t+'_'+str(train_left)+'_'+str(train_right)+'_'+str(Width)+"X"+str(Height)+".h5") print file_name if os.path.exists(file_name): #判斷之前是否有存到檔案中 f = h5py.File(file_name,'r') if t=='train': X_train = f['X_train'][:] y_train = f['y_train'][:] f.close() return (X_train, y_train) elif t=='test': X_test = f['X_test'][:] y_test = f['y_test'][:] f.close() return (X_test, y_test) else: return data_format = conv_utils.normalize_data_format(data_format) pic_dir_set = eachFile(pic_dir_data) X_train = [] y_train = [] X_test = [] y_test = [] label = 0 for pic_dir in pic_dir_set: print pic_dir_data+pic_dir if not os.path.isdir(os.path.join(pic_dir_data,pic_dir)): continue pic_set = eachFile(os.path.join(pic_dir_data,pic_dir)) pic_index = 0 train_count = int(len(pic_set)*train_all) train_l = int(len(pic_set)*train_left) train_r = int(len(pic_set)*train_right) for pic_name in pic_set: if not os.path.isfile(os.path.join(pic_dir_data,pic_dir,pic_name)): continue img = cv2.imread(os.path.join(pic_dir_data,pic_dir,pic_name)) if img is None: continue if (resize): img = cv2.resize(img,(Width,Height)) if (data_format == 'channels_last'): img = img.reshape(-1,Width,Height,3) elif (data_format == 'channels_first'): img = img.reshape(-1,Width,Height,3) img = img.transpose(0, 3, 1, 2) if (pic_index < train_count): if t=='train': if (pic_index >= train_l and pic_index < train_r): X_train.append(img) y_train.append(label) else: if t=='test': X_test.append(img) y_test.append(label) pic_index += 1 if len(pic_set) <> 0: label += 1 f = h5py.File(file_name,'w') if t=='train': X_train = np.concatenate(X_train,axis=0) y_train = np.array(y_train) f.create_dataset('X_train', data = X_train) f.create_dataset('y_train', data = y_train) f.close() return (X_train, y_train) elif t=='test': X_test = np.concatenate(X_test,axis=0) y_test = np.array(y_test) f.create_dataset('X_test', data = X_test) f.create_dataset('y_test', data = y_test) f.close() return (X_test, y_test) else: return
呼叫:
global Width, Height, pic_dir_out, pic_dir_data Width = 32 Height = 32 num_classes = 102 pic_dir_out = 'E:/pic_cnn/pic_out/' pic_dir_data = 'E:/pic_cnn/pic_dataset/Caltech101/' pic_dir_txt = 'E:/pic_cnn/txt/' (X_train, y_train) = get_data("Caltech101_color_data_",0.0,0.7,data_format='channels_last',t='train') (X_test, y_test) = get_data("Caltech101_color_data_",0.0,0.7,data_format='channels_last',t='test') X_train = X_train/255. X_test = X_test/255. print X_train.shape print X_test.shape y_train = np_utils.to_categorical(y_train, num_classes) y_test = np_utils.to_categorical(y_test, num_classes)
設計的小型卷積神經網路:
model = Sequential()
model.add(Convolution2D(
input_shape=(Width, Height, 3),
filters=8,
kernel_size=3,
strides=1,
padding='same',
data_format='channels_last',
))
model.add(Activation('relu'))
model.add(MaxPooling2D(
pool_size=2,
strides=2,
data_format='channels_last',
))
model.add(Flatten())
model.add(Dense(num_classes, activation='softmax'))
model.compile(optimizer=Adam(),
loss='categorical_crossentropy',
metrics=['accuracy'])
print('\nTraining ------------') #從檔案中提取引數,訓練後存在新的檔案中
cm = 0 #修改這個引數可以多次訓練
cm_str = '' if cm==0 else str(cm)
cm2_str = '' if (cm+1)==0 else str(cm+1)
if cm >= 1:
model.load_weights(os.path.join(pic_dir_out,'cnn_model_Caltech101_32f8_'+cm_str+'.h5'))
model.fit(X_train, y_train, epochs=10,batch_size=128,)
model.save_weights(os.path.join(pic_dir_out,'cnn_model_Caltech101_32f8_'+cm2_str+'.h5'))
提取卷積層輸出結果並儲存到檔案:
get_1_layer_output = K.function([model.layers[0].input, K.learning_phase()],
[model.layers[0].output])
pic_len = 1
p_32 = get_1_layer_output([X_train[0:pic_len], 0])[0] #獲取第一層的輸出
image_array = deprocess_image(p_32)
pic_mid = 'mid'
if not os.path.isdir(os.path.join(pic_dir_out,pic_mid)):
os.mkdir(os.path.join(pic_dir_out,pic_mid))
for n_p in xrange(pic_len):
if not os.path.isdir(os.path.join(pic_dir_out,pic_mid,str(n_p))):
os.mkdir(os.path.join(pic_dir_out,pic_mid,str(n_p)))
cv2.imwrite(os.path.join(pic_dir_out,pic_mid,str(n_p),'o_'+str(0)+'.jpg'),
cv2.resize(X_train[n_p]*255.,(512,512)))
for i in xrange(len(image_array)):
cv2.imwrite(os.path.join(pic_dir_out,pic_mid,str(n_p),'p_'+str(i)+'.jpg'),
cv2.resize(image_array[i,:,:,n_p],(512,512)))其中的deprocess_image函式將0到1的浮點數轉換到0-255的影象值:
def deprocess_image(x):
if K.image_data_format() == 'channels_first':
x = x.transpose(1, 2, 3, 0)
elif K.image_data_format() == 'channels_last':
x = x.transpose(3, 1, 2, 0)
x *= 255.
x = np.clip(x, 0, 255).astype('uint8')
return x其中的“K.learning_phase()”表示當前處於訓練狀態還是測試狀態,0為訓練,1為測試。例如當網路有Dropout層時,訓練和測試要採取不同的策略,修改該值可以得到想要的結果。
手工計算卷積層結果:(運算效率暫時不在考慮的範圍內,若在tensorflow下不需要翻轉核)
pic_len = 1
pic_array = X_train[0:pic_len] #擷取一部分訓練資料
weights = model.layers[0].get_weights() #獲取第一層的引數
filters = 8
channels = 3
conv_pic = np.zeros((pic_len,Width,Height,filters)) #產生的多幅卷積影象
border_pic = np.zeros((pic_len,Width+2,Height+2,channels)) #邊緣加一圈0後的影象
for n_p in xrange(pic_len):
border_pic[n_p] = cv2.copyMakeBorder(pic_array[n_p], 1,1,1,1, cv2.BORDER_CONSTANT,(0,0,0))
for n_filters in xrange(filters):
for n_channels in xrange(channels):
kernel = weights[0][:,:,n_channels,n_filters] #獲取卷積核
kernel = np.flipud(np.fliplr(kernel)) #左右翻轉後上下翻轉
for n_p in xrange(pic_len):
for i in range(1,Width+1):
for j in range(1,Height+1):
conv_pic[n_p,i-1,j-1,n_filters] += np.sum((border_pic[n_p,i-1:i+2,j-1:j+2,n_channels])*kernel)
conv_pic[:,:,:,n_filters] += weights[1][n_filters] #加上bias
image_array2 = deprocess_image(conv_pic)
pic_mid = 'mid'
for n_p in xrange(pic_len):
for i in xrange(len(image_array2)):
cv2.imwrite(os.path.join(pic_dir_out,pic_mid,str(n_p),'m_'+str(i)+'.jpg'),
cv2.resize(image_array2[i,:,:,n_p],(512,512)))
print ('difference: ',np.sum(image_array-image_array2))便於理解的手工計算方式:
filters = 8
channels = 3
one_pic = X_train[0]
weights = model.layers[0].get_weights()
one_pic = cv2.copyMakeBorder(one_pic, 1,1,1,1, cv2.BORDER_CONSTANT,(0,0,0))
conv_pic = np.zeros((Width,Height,filters))
for f in xrange(filters):
for i in range(1,Width+1):
for j in range(1,Height+1):
for c in xrange(channels):
kernel = weights[0][:,:,c,f]
kernel = np.flipud(np.fliplr(kernel))
conv_pic[i-1,j-1,f] += np.sum((one_pic[i-1:i+2,j-1:j+2,c])*kernel)
conv_pic[i-1,j-1,f] += weights[1][f]
conv_pic = conv_pic.reshape((-1,Width,Height,8))其中獲取到的weights[0]是引數矩陣,weights[1]是bias。其中的“kernel = np.flipud(np.fliplr(kernel))”的意思是將kernel左右翻轉後再上下翻轉,這樣計算出來的結果才與呼叫介面產生的結果相同。計算方式的來源如下(來自cs231n_2017_lecture5.pdf):
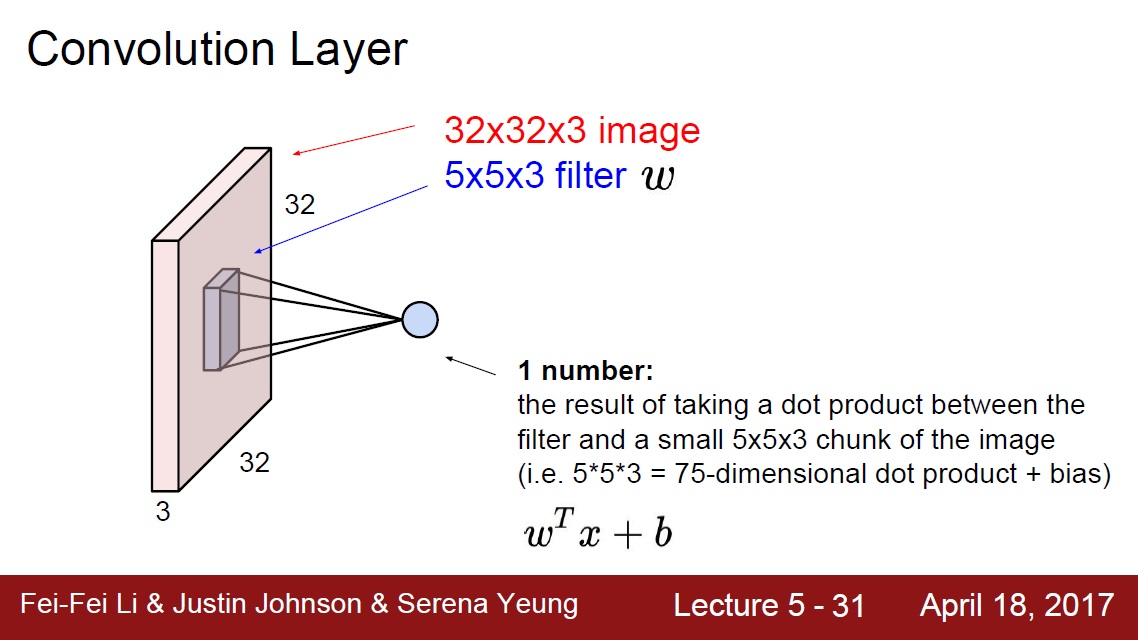
在這附近有幾張幫助理解卷積神經網路的圖(來自cs231n_2017_lecture5.pdf):

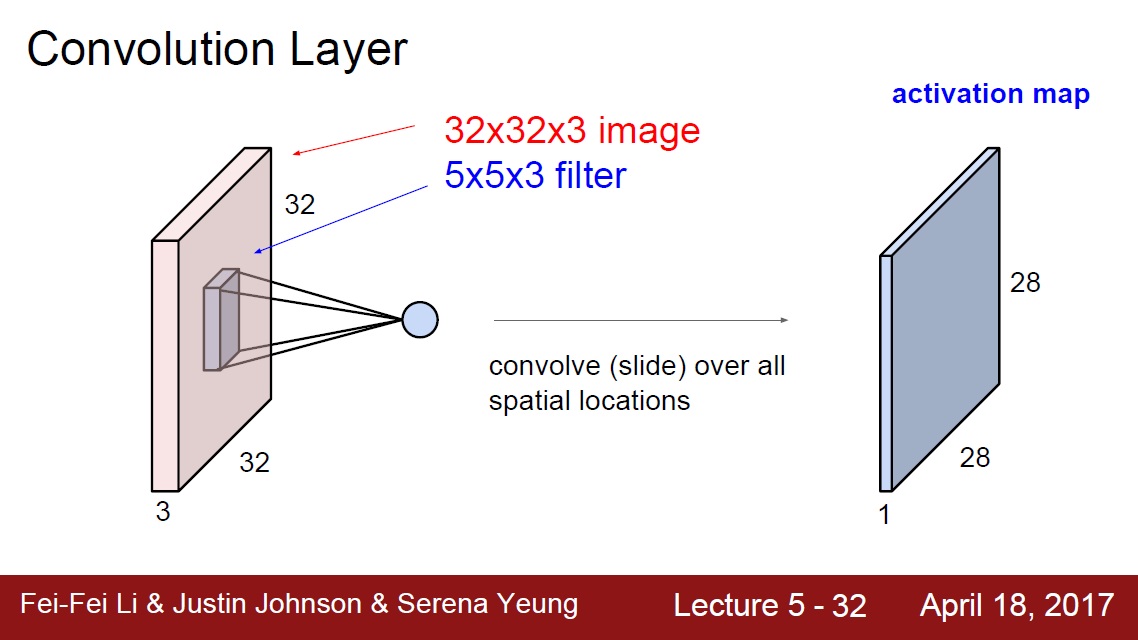
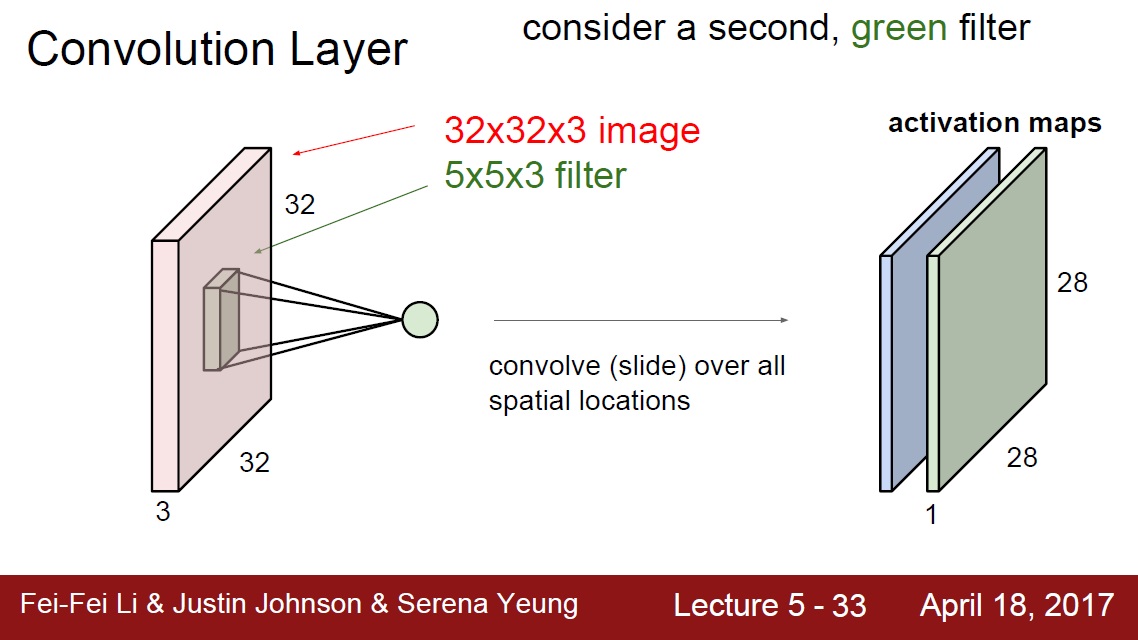
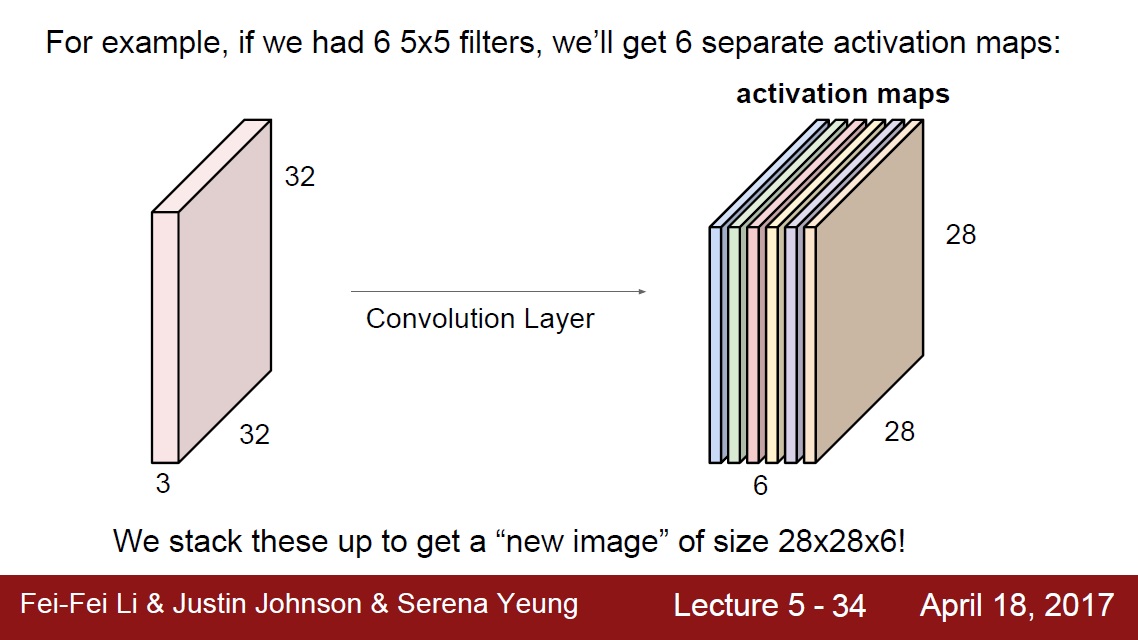
完整程式碼:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import os
import h5py
from keras.utils import np_utils, conv_utils
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D, Flatten, Dense, Activation
from keras.optimizers import Adam
from keras import backend as K
def get_name_list(filepath): #獲取各個類別的名字
pathDir = os.listdir(filepath)
out = []
for allDir in pathDir:
if os.path.isdir(os.path.join(filepath,allDir)):
child = allDir.decode('gbk') # .decode('gbk')是解決中文顯示亂碼問題
out.append(child)
return out
def eachFile(filepath): #將目錄內的檔名放入列表中
pathDir = os.listdir(filepath)
out = []
for allDir in pathDir:
child = allDir.decode('gbk') # .decode('gbk')是解決中文顯示亂碼問題
out.append(child)
return out
def get_data(data_name,train_left=0.0,train_right=0.7,train_all=0.7,resize=True,data_format=None,t=''): #從資料夾中獲取影象資料
file_name = os.path.join(pic_dir_out,data_name+t+'_'+str(train_left)+'_'+str(train_right)+'_'+str(Width)+"X"+str(Height)+".h5")
print file_name
if os.path.exists(file_name): #判斷之前是否有存到檔案中
f = h5py.File(file_name,'r')
if t=='train':
X_train = f['X_train'][:]
y_train = f['y_train'][:]
f.close()
return (X_train, y_train)
elif t=='test':
X_test = f['X_test'][:]
y_test = f['y_test'][:]
f.close()
return (X_test, y_test)
else:
return
data_format = conv_utils.normalize_data_format(data_format)
pic_dir_set = eachFile(pic_dir_data)
X_train = []
y_train = []
X_test = []
y_test = []
label = 0
for pic_dir in pic_dir_set:
print pic_dir_data+pic_dir
if not os.path.isdir(os.path.join(pic_dir_data,pic_dir)):
continue
pic_set = eachFile(os.path.join(pic_dir_data,pic_dir))
pic_index = 0
train_count = int(len(pic_set)*train_all)
train_l = int(len(pic_set)*train_left)
train_r = int(len(pic_set)*train_right)
for pic_name in pic_set:
if not os.path.isfile(os.path.join(pic_dir_data,pic_dir,pic_name)):
continue
img = cv2.imread(os.path.join(pic_dir_data,pic_dir,pic_name))
if img is None:
continue
if (resize):
img = cv2.resize(img,(Width,Height))
if (data_format == 'channels_last'):
img = img.reshape(-1,Width,Height,3)
elif (data_format == 'channels_first'):
img = img.reshape(-1,Width,Height,3)
img = img.transpose(0, 3, 1, 2)
if (pic_index < train_count):
if t=='train':
if (pic_index >= train_l and pic_index < train_r):
X_train.append(img)
y_train.append(label)
else:
if t=='test':
X_test.append(img)
y_test.append(label)
pic_index += 1
if len(pic_set) <> 0:
label += 1
f = h5py.File(file_name,'w')
if t=='train':
X_train = np.concatenate(X_train,axis=0)
y_train = np.array(y_train)
f.create_dataset('X_train', data = X_train)
f.create_dataset('y_train', data = y_train)
f.close()
return (X_train, y_train)
elif t=='test':
X_test = np.concatenate(X_test,axis=0)
y_test = np.array(y_test)
f.create_dataset('X_test', data = X_test)
f.create_dataset('y_test', data = y_test)
f.close()
return (X_test, y_test)
else:
return
def deprocess_image(x):
if K.image_data_format() == 'channels_first':
x = x.transpose(1, 2, 3, 0)
elif K.image_data_format() == 'channels_last':
x = x.transpose(3, 1, 2, 0)
x *= 255.
x = np.clip(x, 0, 255).astype('uint8')
return x
def main():
global Width, Height, pic_dir_out, pic_dir_data
Width = 32
Height = 32
num_classes = 102 #Caltech101為102 cifar10為10
pic_dir_out = 'E:/pic_cnn/pic_out/'
pic_dir_data = 'E:/pic_cnn/pic_dataset/Caltech101/'
pic_dir_txt = 'E:/pic_cnn/txt/'
(X_train, y_train) = get_data("Caltech101_color_data_",0.0,0.7,data_format='channels_last',t='train')
(X_test, y_test) = get_data("Caltech101_color_data_",0.0,0.7,data_format='channels_last',t='test')
X_train = X_train/255.
X_test = X_test/255.
print X_train.shape
print X_test.shape
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Convolution2D(
input_shape=(Width, Height, 3),
filters=8,
kernel_size=3,
strides=1,
padding='same',
data_format='channels_last',
))
model.add(Activation('relu'))
model.add(MaxPooling2D(
pool_size=2,
strides=2,
data_format='channels_last',
))
model.add(Flatten())
model.add(Dense(num_classes, activation='softmax'))
model.compile(optimizer=Adam(),
loss='categorical_crossentropy',
metrics=['accuracy'])
print('\nTraining ------------') #從檔案中提取引數,訓練後存在新的檔案中
cm = 0 #修改這個引數可以多次訓練
cm_str = '' if cm==0 else str(cm)
cm2_str = '' if (cm+1)==0 else str(cm+1)
if cm >= 1:
model.load_weights(os.path.join(pic_dir_out,'cnn_model_Caltech101_32f8_'+cm_str+'.h5'))
model.fit(X_train, y_train, epochs=10,batch_size=128,)
model.save_weights(os.path.join(pic_dir_out,'cnn_model_Caltech101_32f8_'+cm2_str+'.h5'))
get_1_layer_output = K.function([model.layers[0].input, K.learning_phase()],
[model.layers[0].output])
pic_len = 1
p_32 = get_1_layer_output([X_train[0:pic_len], 0])[0] #獲取第一層的輸出
image_array = deprocess_image(p_32)
pic_mid = 'mid'
if not os.path.isdir(os.path.join(pic_dir_out,pic_mid)):
os.mkdir(os.path.join(pic_dir_out,pic_mid))
for n_p in xrange(pic_len):
if not os.path.isdir(os.path.join(pic_dir_out,pic_mid,str(n_p))):
os.mkdir(os.path.join(pic_dir_out,pic_mid,str(n_p)))
cv2.imwrite(os.path.join(pic_dir_out,pic_mid,str(n_p),'o_'+str(0)+'.jpg'),
cv2.resize(X_train[n_p]*255.,(512,512)))
for i in xrange(len(image_array)):
cv2.imwrite(os.path.join(pic_dir_out,pic_mid,str(n_p),'p_'+str(i)+'.jpg'),
cv2.resize(image_array[i,:,:,n_p],(512,512)))
'''
filters = 8
channels = 3
one_pic = X_train[0]
weights = model.layers[0].get_weights()
one_pic = cv2.copyMakeBorder(one_pic, 1,1,1,1, cv2.BORDER_CONSTANT,(0,0,0))
conv_pic = np.zeros((Width,Height,filters))
for f in xrange(filters):
for i in range(1,Width+1):
for j in range(1,Height+1):
for c in xrange(channels):
kernel = weights[0][:,:,c,f]
kernel = np.flipud(np.fliplr(kernel))
conv_pic[i-1,j-1,f] += np.sum((one_pic[i-1:i+2,j-1:j+2,c])*kernel)
conv_pic[i-1,j-1,f] += weights[1][f]
conv_pic = conv_pic.reshape((-1,Width,Height,8))
'''
pic_len = 1
pic_array = X_train[0:pic_len] #擷取一部分訓練資料
weights = model.layers[0].get_weights() #獲取第一層的引數
filters = 8
channels = 3
conv_pic = np.zeros((pic_len,Width,Height,filters)) #產生的多幅卷積影象
border_pic = np.zeros((pic_len,Width+2,Height+2,channels)) #邊緣加一圈0後的影象
for n_p in xrange(pic_len):
border_pic[n_p] = cv2.copyMakeBorder(pic_array[n_p], 1,1,1,1, cv2.BORDER_CONSTANT,(0,0,0))
for n_filters in xrange(filters):
for n_channels in xrange(channels):
kernel = weights[0][:,:,n_channels,n_filters] #獲取卷積核
kernel = np.flipud(np.fliplr(kernel)) #左右翻轉後上下翻轉
for n_p in xrange(pic_len):
for i in range(1,Width+1):
for j in range(1,Height+1):
conv_pic[n_p,i-1,j-1,n_filters] += np.sum((border_pic[n_p,i-1:i+2,j-1:j+2,n_channels])*kernel)
conv_pic[:,:,:,n_filters] += weights[1][n_filters] #加上bias
image_array2 = deprocess_image(conv_pic)
pic_mid = 'mid'
for n_p in xrange(pic_len):
for i in xrange(len(image_array2)):
cv2.imwrite(os.path.join(pic_dir_out,pic_mid,str(n_p),'m_'+str(i)+'.jpg'),
cv2.resize(image_array2[i,:,:,n_p],(512,512)))
print ('difference: ',np.sum(image_array-image_array2))
if __name__ == '__main__':
main() | |
 |  |
 |  |
 |  |
 |  |