
揭祕阿里小蜜:基於檢索模型和生成模型相結合的聊天引擎
面向 open domain 的聊天機器人無論在學術界還是工業界都是個有挑戰的課題,目前有兩種典型的方法:一是基於檢索的模型,二是基於 Seq2Seq 的生成式模型。前者回復答案可控但無法處理長尾問題,後者則難以保證一致性和合理性。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @britin。本文結合檢索模型和生成模型各自的優勢,提出了一種新的融合模型 — AliMe Chat。
阿里小蜜首先採用檢索模型從 QA 知識庫中找出候選答案集合,然後利用帶注意力的 Seq2Seq 模型對候選答案進行排序,如果第一候選的得分超過某個閾值,則作為最終答案輸出,否則利用生成模型生成答案。
關於作者:Britin,中科院物理學碩士,研究方向為自然語言處理和計算機視覺。
■ 論文 | AliMe Chat: A Sequence to Sequence and Rerank based Chatbot Engine
■ 連結 | https://www.paperweekly.site/papers/1302
■ 作者 | britin
論文動機
目前商用的 Chatbot 正在大量興起,這種可以自然語言對話的方式來幫助使用者解答問題比傳統死板的使用者介面要更友好。通常 Chatbot 包括兩個部分:IR 模組和生成模組。針對使用者的問題,IR 模組從 QA 知識庫中檢索到對應的答案,生成模組再用預訓練好的 Seq2Seq 模型生成最終的答案。
但是已有的系統面臨的問題是,對於一些長問句或複雜問句往往無法在 QA 知識庫中檢索到匹配的條目,並且生成模組也經常生成不匹配或無意義的答案。
本文給出的方法將 IR 和生成模組聚合在一起,用一個 Seq2Seq 模型來對搜尋結果做評估,從而達到優化的效果。
模型介紹
整個方案如圖所示:

首先利用 IR 模型從知識庫中檢索到 k 個候選 QA 對,再利用 rerank 模型的打分機制計算出每個候選答案和問題的匹配程度。如果得分最高的那個大於預設好的閾值,就將其當作答案,如果小於閾值,就用生成模型生成答案。
整個系統是從單詞層面上去分析的。
1. QA知識庫
本文從線上的真人使用者服務 log 裡提取問答對作為 QA 知識庫。過濾掉不包含相關關鍵詞的 QA,最後得到 9164834 個問答對。
2. IR模組
利用倒排索引的方法將每個單詞隱射到包含這個單詞的一組問句中,並且對這些單詞的同義詞也做了索引,然後利用 BM25 演算法來計算搜尋到的問句和輸入問句的相似度,取最相似問句的答案。
3. 生成模型
生成模型是一個 attentive seq2seq 的結構,如圖所示:
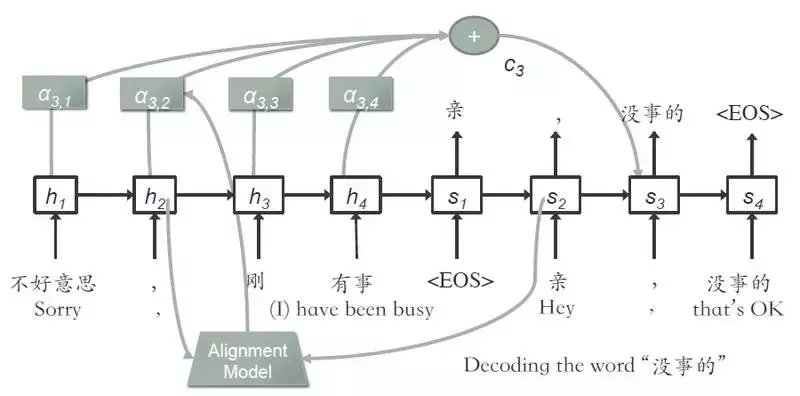
採用了一個 GRU,由 question 生成 answer,計算生成單詞的概率:
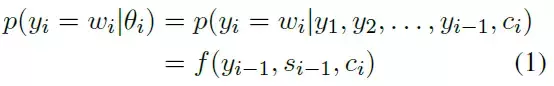
其中加了 context 向量,他是由圖中的 α 求得的,α 表示的是當前步的輸入單詞,和上一步的生成單詞之間的匹配度,用了一個 alignment 模型計算。
要注意,對於各個 QA 長度不等的情況,採用了 bucketing 和 padding 機制。另外用了 softmax 來隨機取樣詞彙表中的單詞,而不使用整個詞彙表,從而加速了訓練過程。還是用了 beam search decoder,每次維護 top-k 個輸出,來取代一次一個輸出的貪心搜尋。
4. rerank 模組
使用的模型和上面是一樣的,根據輸入問題來為候選答案打分,使用平均概率作為評分函式:

實驗結果
本文對結果做了詳細的評估,首先評估了 rerank 模組平均概率的結果。然後分別對 IR,生成,IR+rerank,IR+rerank+ 生成這些不同組合的系統做了效能評測。並對該系統和 baseline 的 Chatbot 做了線上 A/B 測試。最後比較了這個系統和已經上市的 Chatbot 之間的差別。
不同 rerank 模型的效果:

不同模組組合的結果:

和 baseline 對比的結果:

文章評價
本文給出了一種 attentive Seq2Seq 的模型來結合 IR 和生成模組,從而對原結果進行 rerank 優化。阿里已經把這個投入了阿里小蜜的商用。
總的系統還是比較簡單的,符合商用的需求。但由於函式設計過於簡單,不排除是靠資料堆起來的系統,畢竟阿里有大量的真實使用者資料,所以演算法價值層面比較一般,沒有合適的資料恐怕很難達到預期的效果。