
自制爬蟲,爬取分類總閱讀量,總評論量。全部文章閱讀量和,以及評論量和。但是發現數據不對
阿新 • • 發佈:2018-12-31
def tt(a,name):
global ss
global cc
sum = 0
com = 0
pages = 10
x = 1
nn = []
mm = []
其中global,很重要。沒有這個global會報錯誤!!
全部程式碼:
import requests import re ss = 0 cc = 0 empty = [] def tt(a,name): global ss global cc sum = 0 com = 0 pages = 10 x = 1 nn = [] mm = [] base_url = "https://blog.csdn.net/weixin_42859280/article/category/" print('\n-------------------------'+name+'-------------------------') print('-------------------------下面是原創的-------------------------\n') for x in range(pages): w = 0 r = requests.get(base_url+str(a)+'/'+str(x+1)+'?t=1&orderby=ViewCount') titles = re.findall(r'<span class="article-type type-.*?">\n.*?</span>\n(.*?)</a>', r.content.decode(), re.MULTILINE) visits = re.findall( r'<span class="read-num">閱讀數:(.*?)</span>', r.content.decode()) mm = re.findall( r'<span class="read-num">評論數:(.*?)</span>', r.content.decode()) nn = [int(x) for x in visits] #將閱讀數轉換為數字 nn = nn[1:] mm = mm[1:] n = 1 for x, y, z in zip(titles, nn,mm): ff = open(name+'.txt','a') if n%10 == 0: ff.write(titles[w]+' 閱讀數:'+str(nn[w])+' 評論數:'+mm[w]+' \n\n') else: ff.write(titles[w]+' 閱讀數:'+str(nn[w])+' 評論數:'+mm[w]+' \n') ff.close() n += 1 #if int(nn[w]) > 1000: #if int(mm[w]) > 0: print(titles[w]+' \t\t閱讀數:'+str(nn[w])+' \t\t評論數:'+mm[w]) sum += int(nn[w]) com += int(mm[w]) w+=1 print('\n-------------------------下面是轉載的------------------------') ff = open(name+'.txt','a') ff.write(' \n\n 下面就是轉載的!\n\n') ff.close() pages = 11 x = 1 nn = [] mm = [] for x in range(pages): w = 0 r = requests.get(base_url+str(a)+'/'+str(x+1)+'?t=2&orderby=ViewCount') titles = re.findall(r'<span class="article-type type-.*?">\n.*?</span>\n(.*?)</a>', r.content.decode(), re.MULTILINE) visits = re.findall( r'<span class="read-num">閱讀數:(.*?)</span>', r.content.decode()) mm = re.findall( r'<span class="read-num">評論數:(.*?)</span>', r.content.decode()) nn = [int(x) for x in visits] #將閱讀數轉換為數字 nn = nn[1:] mm = mm[1:] n = 1 for x, y, z in zip(titles, nn,mm): ff = open(name+'.txt','a') if n%10 == 0: ff.write(titles[w]+' 閱讀數:'+str(nn[w])+' 評論數:'+mm[w]+' \n\n') else: ff.write(titles[w]+' 閱讀數:'+str(nn[w])+' 評論數:'+mm[w]+' \n') ff.close() n += 1 #if int(nn[w]) > 1000: #if int(mm[w]) > 0: print(titles[w]+' \t閱讀數:'+str(nn[w])+' \t評論數:'+mm[w]) sum += int(nn[w]) com += int(mm[w]) w+=1 ss += int(sum) cc += int(com) print("總閱讀量:"+str(sum)+" 總評論量:"+str(com)) ww = name+" 總閱讀量:"+str(sum)+" 總評論量:"+str(com) empty.append(ww) ff = open(name+'.txt','a') ff.write(' \n 總閱讀量:'+str(sum)) ff.write(' 總評論量:'+str(com)) ff.close() tt(8100910,'基礎啦') tt(8125178,'轉載啦,方便找! ') tt(8128370,'基石一般的東西!') tt(8128378,' 自己找的一點CMD命令!嘻嘻~ ') tt(8251895,' Linux CENTOS') tt(8252351,'網路交換機與路由器 ') tt(8252355,' Windows ') tt(8252363,'計算機網路') tt(8252366,' Linux ') tt(8276398,' 看起來比較牛X的一些小玩意 ') tt(8292701,'小米開啟Fn ') tt(8300944,' python '+'.txt') tt(8309287,' 網路空間安全學習筆記') tt(8460562,'Python語言及其應用學習! ') tt(8493893,' ACM爭取每日一oj! ') tt(8518453,'C,C++語言程式設計基礎知識!') tt(8529012,'演算法問題 ') print("全部文章總閱讀量:"+str(ss)+" 全部文章總評論量:"+str(cc)) for i in empty: print(i)
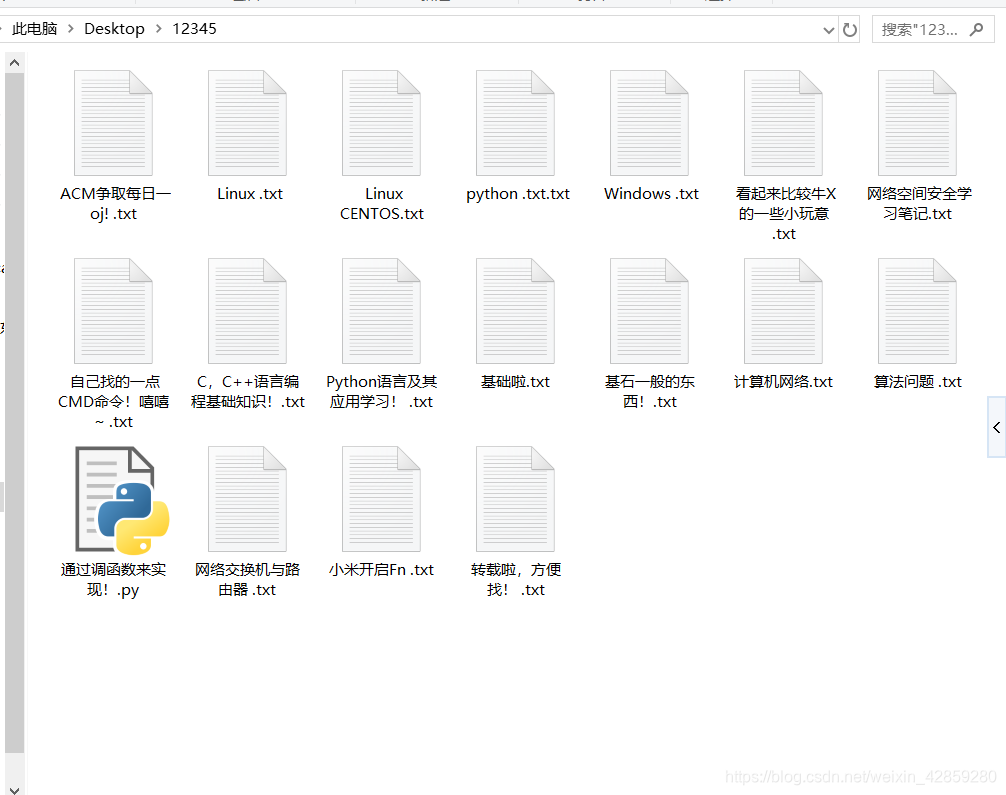
執行後文件截圖:
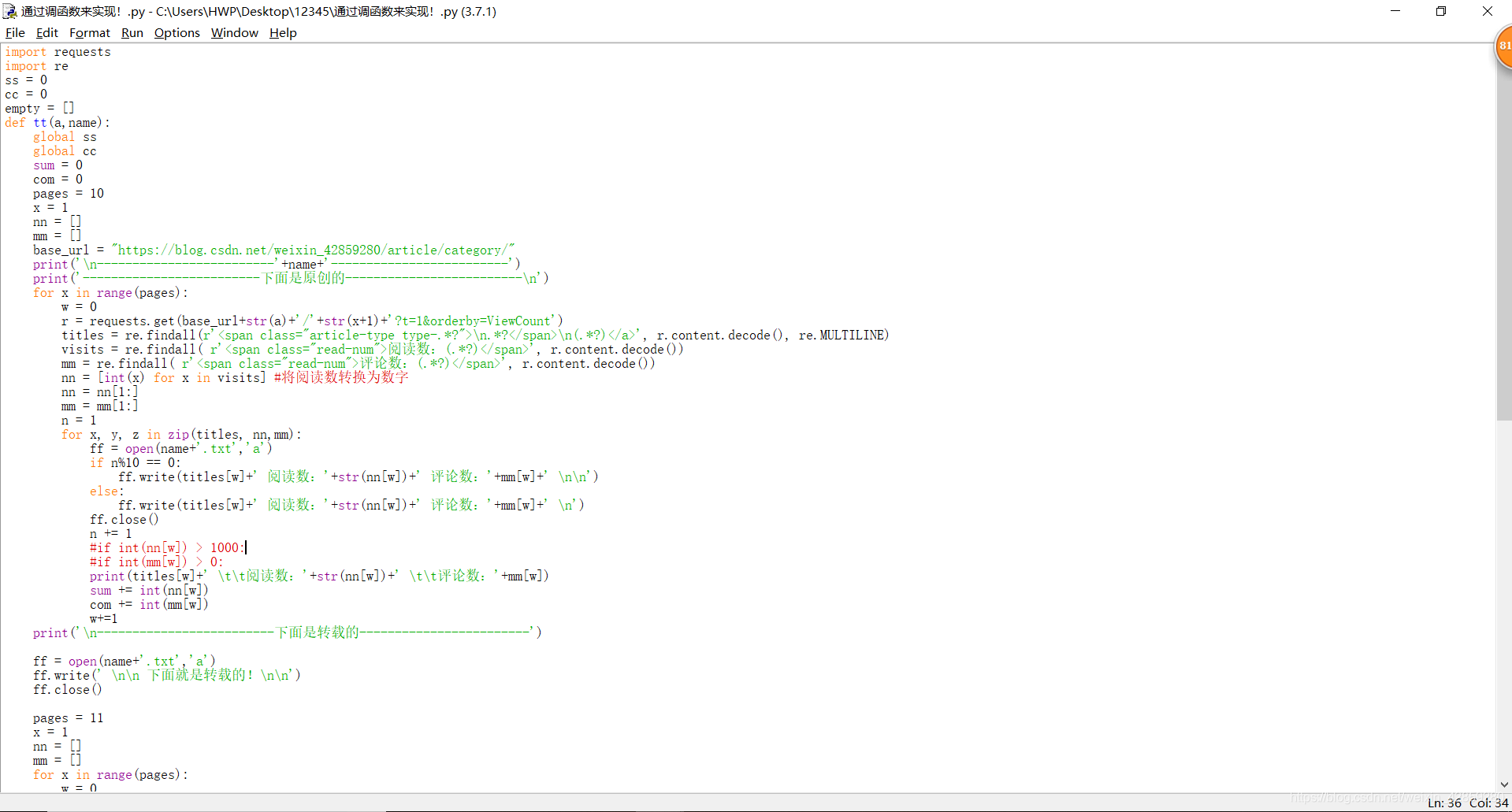
程式碼截圖:
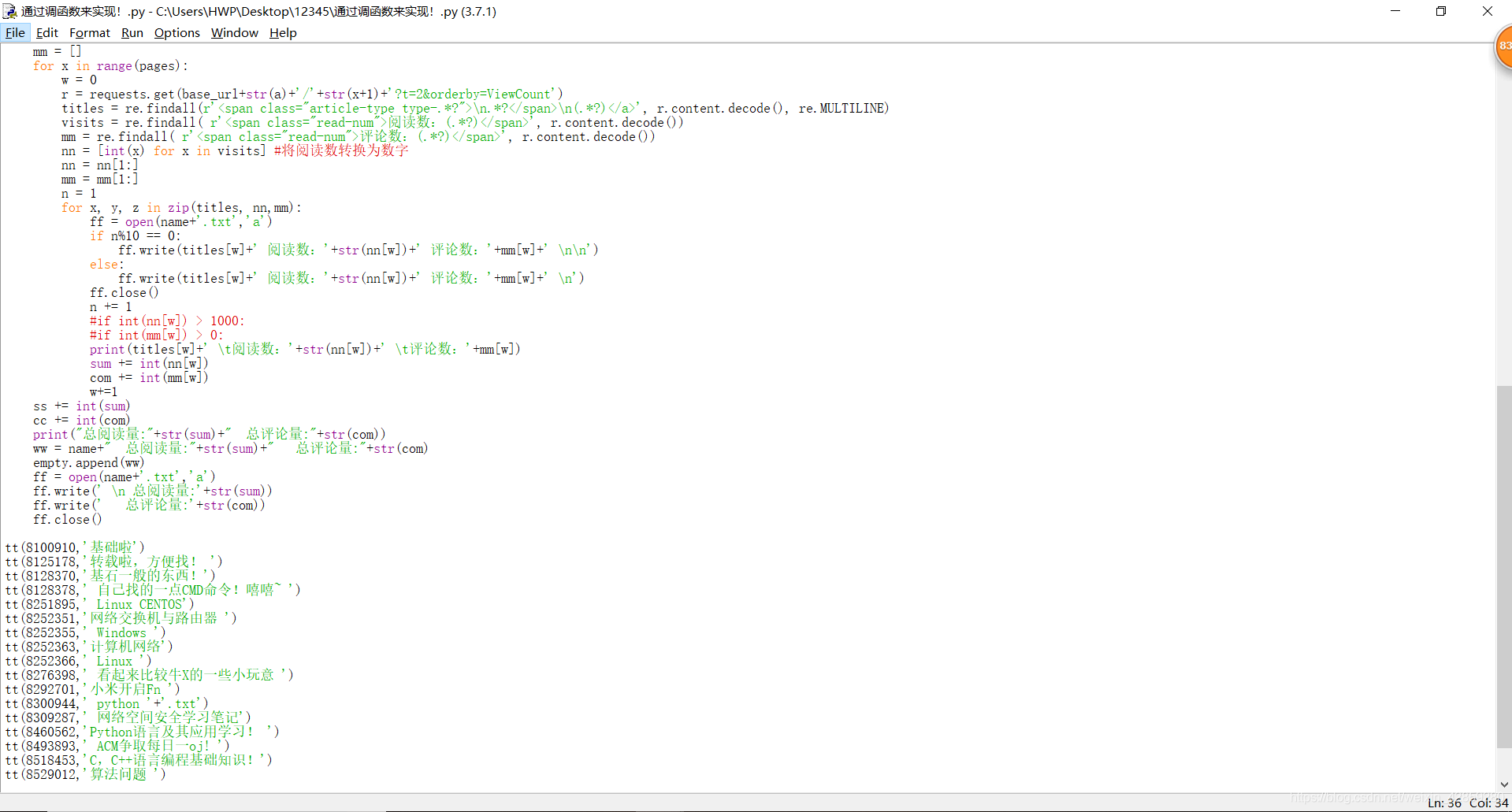
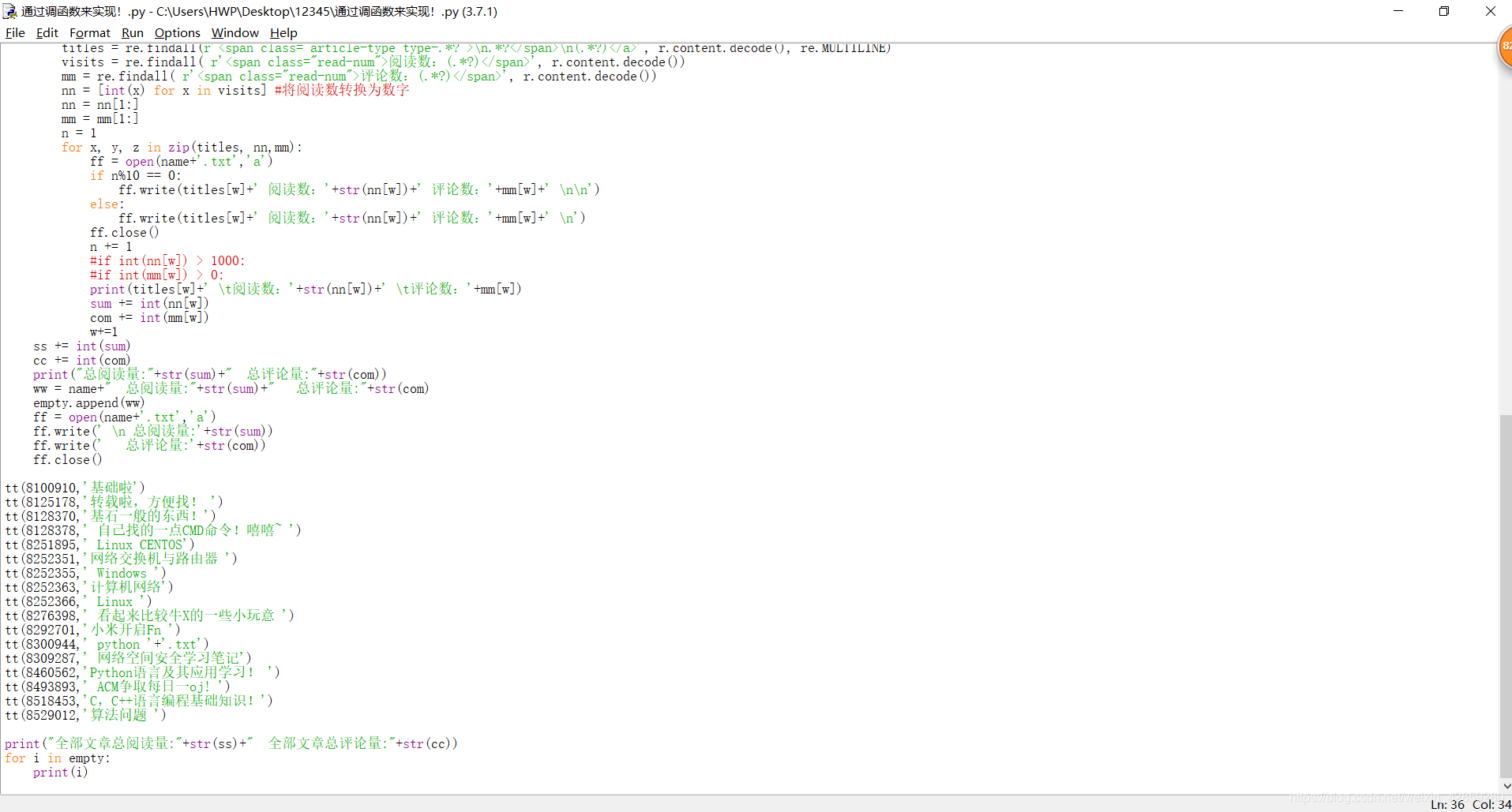
最後:
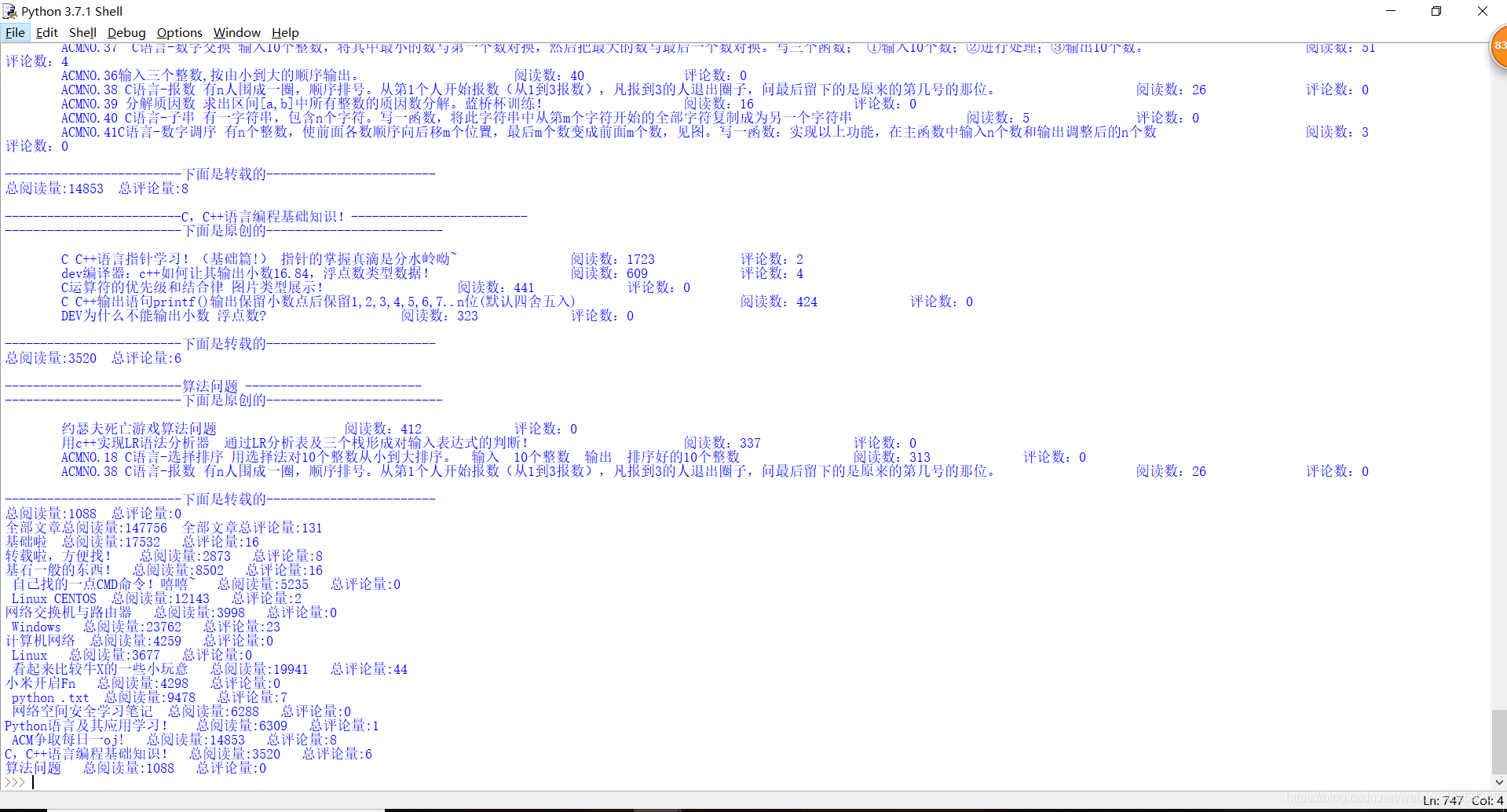
留著以後用·
不過,具體實現過程沒有寫。
想學的話,給我留言。
我教你呀~