
學習筆記2018.1.9
阿新 • • 發佈:2018-12-30
Beautiful Soup庫解析器 解析器 使用方法 條件 bs4的HTML解析器: BeautifulSoup(mk,’html.parser’) 安裝bs4庫 lxml的HTML解析器: BeautifulSoup(mk,’lxml’) pip install lxml lxml的XML解析器: BeautifulSoup(mk,’xml’) pip install lxml html5lib的解析器: BeautifulSoup(mk,’html5lib’) pip install html5lib Beautiful Soup類的基本元素: Tag 標籤,最基本的資訊組織單元,分別用<>和</>標明開頭和結尾 Name 標籤的名字,<p>...</p>的名字是’p’,格式:<tag>.name Attributes 標籤的屬性,字典形式組織,格式:<tag>.attrs NavigableString 標籤內非屬性字串,<>...</>中字串,格式:<tag>.string Comment 標籤內字串的註釋部分,一種特殊的Comment型別

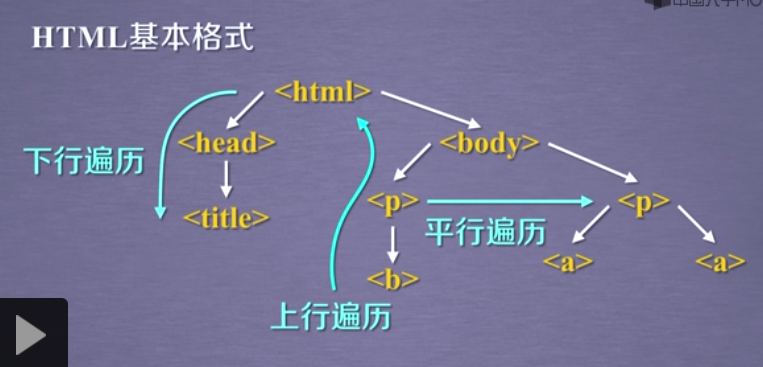
標籤樹的下行遍歷 .contents 子結點的列表,將<tag>所有兒子節點存入列表 .children 子結點的迭代型別,與.coontents類似,用於迴圈遍歷兒子節點 .descendants 子孫節點的迭代型別,包含所有子孫節點,用於迴圈遍歷 標籤樹的上行遍歷 .parent 節點的父親標籤 .parents 節點先輩標籤的迭代型別,用於迴圈遍歷先輩節點 標籤樹的平行遍歷 .next_sibling 返回按照HTML文字順序的下一個平行節點標籤 .previous_sibling 返回按照HTML文字順序的上一個平行節點標籤 .next_siblings 迭代型別,返回按照HTML文字順序的後續所有平行節點標籤 .previous_sibling 迭代型別,返回按照HTML文字順序的前續所有平行節點標籤 平行遍歷需要發生在同一個父點下的各節點間 .prettify()為HTML文字<>及其內容增加更加’\n’ .prettify()可用於標籤,方法:<tag>.prettify() bs4庫將任何HTML輸入都變成utf-8編碼 HTML:Hyper Text Markup Language <>.find_all(name,attrs,recursive,string,**kwargs) name:對標籤名稱的檢索字串 attrs:對標籤屬性值的檢索字串,可標註屬性檢索 recursive:是否對子孫全部檢索,預設True string:<>...</>中字串區域的檢索字串 <tag>(..) 等價於 <tag>.find_all(..) Soup(..) 等價於 soup.find_all(..) <>.find() 搜尋且只返回一個結果,同.find_all()引數 <>.find_parents()在先輩節點中搜索,返回列表型別,同.find_all()引數 <>.find_parent()在先輩節點中返回一個結果,同.find()引數 <>.find_next_siblings()在後續平行節點中搜索,返回列表型別,同.find_all()引數 <>.find_next_sibling()在後續平行節點中返回一個結果,同.find()引數 <>.find_previous_siblings()在前續平行節點中搜索,返回列表型別,同.find_all()引數 <>.find_previous_sibling()在前續平行節點中返回一個結果,同.find()引數

中文對齊問題的原因:
當中文字元寬度不夠時,採用西文字元填充;中西文字元佔用寬度不同。
解決方法:
採用中文字元的空格填充chr(12288)此後跟著步驟做了一個爬取資訊的爬蟲
複習去了= =