層次聚類演算法的原理及python實現
-
層次聚類(Hierarchical Clustering)是一種聚類演算法,通過計算不同類別資料點間的相似度來建立一棵有層次的巢狀聚類樹。在聚類樹中,不同類別的原始資料點是樹的最低層,樹的頂層是一個聚類的根節點。
-
聚類樹的建立方法:自下而上的合併,自上而下的分裂。(這裡介紹第一種)
1.2 層次聚類的合併演算法
層次聚類的合併演算法通過計算兩類資料點間的相似性,對所有資料點中最為相似的兩個資料點進行組合,並反覆迭代這一過程。簡單的說層次聚類的合併演算法是通過計算每一個類別的資料點與所有資料點之間的距離來確定它們之間的相似性,距離越小,相似度越高。並將距離最近的兩個資料點或類別進行組合,生成聚類樹。合併過程如下:
- 我們可以獲得一個
的距離矩陣 X,其中
表示
和
的距離,稱為資料點與資料點之間的距離。記每一個數據點為
將距離最小的資料點進行合併,得到一個組合資料點,記為 G
- 資料點與組合資料點之間的距離: 當計算G 和
的距離時,需要計算
- 組合資料點與組合資料點之間的距離:主要有Single Linkage,Complete Linkage和Average Linkage 三種。這三種演算法介紹如下,摘自:
Single Linkage
Single Linkage的計算方法是將兩個組合資料點中距離最近的兩個資料點間的距離作為這兩個組合資料點的距離。這種方法容易受到極端值的影響。兩個很相似的組合資料點可能由於其中的某個極端的資料點距離較近而組合在一起。
Complete Linkage
Complete Linkage的計算方法與Single Linkage相反,將兩個組合資料點中距離最遠的兩個資料點間的距離作為這兩個組合資料點的距離。Complete Linkage的問題也與Single Linkage相反,兩個不相似的組合資料點可能由於其中的極端值距離較遠而無法組合在一起。
Average Linkage
Average Linkage的計算方法是計算兩個組合資料點中的每個資料點與其他所有資料點的距離。將所有距離的均值作為兩個組合資料點間的距離。這種方法計算量比較大,但結果比前兩種方法更合理。
二、Python實現
可以直接使用 scipy.cluster.hierarchy.linkage !!!
如下程式碼實現的是將一組數進行層次聚類。
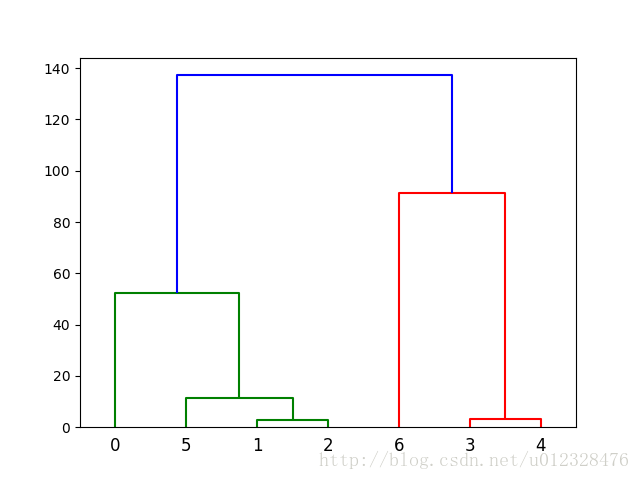
# -*- coding: utf-8 -*- import numpy as np from scipy.cluster.hierarchy import dendrogram, linkage, fcluster from matplotlib import pyplot as plt def hierarchy_cluster(data, method='average', threshold=5.0): '''層次聚類 Arguments: data [[0, float, ...], [float, 0, ...]] -- 文件 i 和文件 j 的距離 Keyword Arguments: method {str} -- [linkage的方式: single、complete、average、centroid、median、ward] (default: {'average'}) threshold {float} -- 聚類簇之間的距離 Return: cluster_number int -- 聚類個數 cluster [[idx1, idx2,..], [idx3]] -- 每一類下的索引 ''' data = np.array(data) Z = linkage(data, method=method) cluster_assignments = fcluster(Z, threshold, criterion='distance') print type(cluster_assignments) num_clusters = cluster_assignments.max() indices = get_cluster_indices(cluster_assignments) return num_clusters, indices def get_cluster_indices(cluster_assignments): '''對映每一類至原資料索引 Arguments: cluster_assignments 層次聚類後的結果 Returns: [[idx1, idx2,..], [idx3]] -- 每一類下的索引 ''' n = cluster_assignments.max() indices = [] for cluster_number in range(1, n + 1): indices.append(np.where(cluster_assignments == cluster_number)[0]) return indices if __name__ == '__main__': arr = [[0., 21.6, 22.6, 63.9, 65.1, 17.7, 99.2], [21.6, 0., 1., 42.3, 43.5, 3.9, 77.6], [22.6, 1., 0, 41.3, 42.5, 4.9, 76.6], [63.9, 42.3, 41.3, 0., 1.2, 46.2, 35.3], [65.1, 43.5, 42.5, 1.2, 0., 47.4, 34.1], [17.7, 3.9, 4.9, 46.2, 47.4, 0, 81.5], [99.2, 77.6, 76.6, 35.3, 34.1, 81.5, 0.]] arr = np.array(arr) r, c = arr.shape for i in xrange(r): for j in xrange(i, c): if arr[i][j] != arr[j][i]: arr[i][j] = arr[j][i] for i in xrange(r): for j in xrange(i, c): if arr[i][j] != arr[j][i]: print(arr[i][j], arr[j][i]) num_clusters, indices = hierarchy_cluster(arr) print "%d clusters" % num_clusters for k, ind in enumerate(indices): print "cluster", k + 1, "is", ind ## 執行結果 5 clusters cluster 1 is [1 2] cluster 2 is [5] cluster 3 is [0] cluster 4 is [3 4] cluster 5 is [6]
上述結果視覺化: