
網易雲音樂推薦系統簡單實現系列(1)
筆者最近面試到了網易新聞推薦部門,考了一點推薦系統的知識,算是被虐慘了。於是乎自己怒補了一些知識。記錄一點關於推薦系統的知識和實現。
音樂推薦系統,這裡的簡單指的是資料量級才2萬條,之後會詳細解釋。
1. 推薦系統工程師人才成長RoadMap

2. 1. 資料的獲取
任何的機器學習演算法解決問題,首先就是要考慮的是資料,資料從何而來?
對於網易雲音樂這樣的企業而言,使用者的收藏和播放資料是可以直接獲得的,我們找一個取巧的方式,包含使用者音樂興趣資訊,同時又可以獲取的資料是什麼?
對的,是熱門歌單資訊,以及歌單內歌曲的詳細資訊。
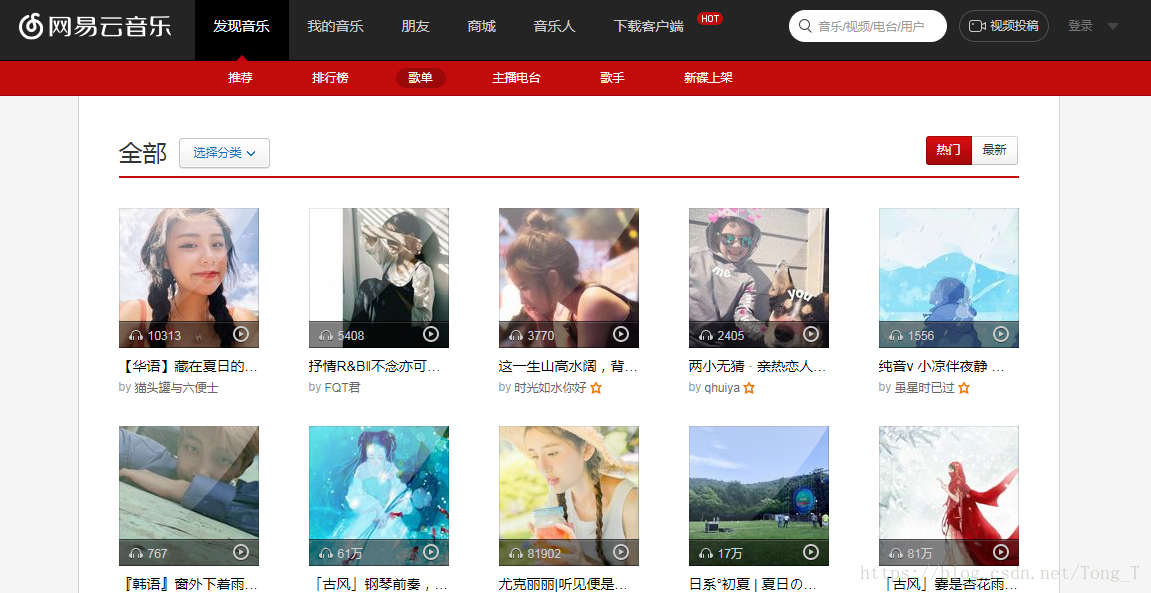
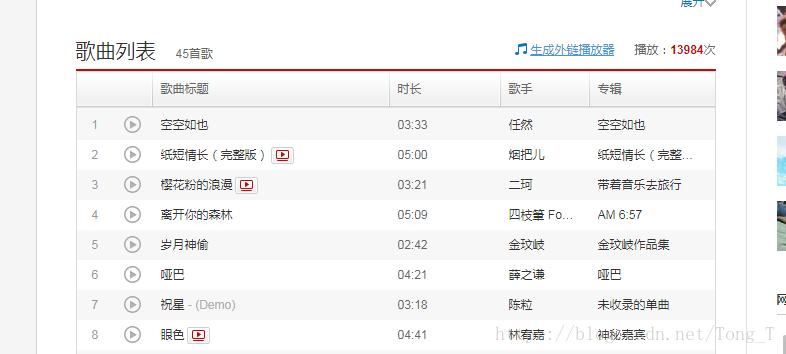
3. 資料爬蟲指令碼
程式碼說明:
1. 網易雲音樂網路爬蟲由於加了資料包傳動態引數的反爬措施。拿到歌單資料包的難度很大。一大神破解了傳參動態密碼,程式碼中AES演算法。
2. 但是不知道為什麼這個python2.7版下指令碼只能爬取每個歌單裡面的10首歌,由於這個原因,導致我們的推薦系統原始資料量級驟然降低。筆者試了很久,也沒有辦法。望大家給點建議。不管怎樣,資料量小,那咱們就簡單實現就好。
3. 一共1921個歌單(json檔案),每個歌單裡面包含10首歌,所以咱們後面建模的資料量實際只有2W左右的例項。
# -*- coding:utf-8 -*-
"""
爬蟲爬取網易雲音樂歌單的資料包儲存成json檔案
python2.7環境
""" 4. 特徵工程和資料預處理,提取我這次做推薦系統有用的特徵資訊。
在原始的1291個json檔案裡面包含非常多的資訊(風格,歌手,歌曲播放次數,歌曲時長,歌曲發行時間),其實大家思考後一定會想到如何使用它們進一步完善推薦系統。我這裡依舊使用最基礎的音樂資訊,我們認為同一個歌單中的歌曲,有比較高的相似性,
其中 歌單資料=>推薦系統格式資料,主流的python推薦系統框架,支援的最基本資料格式為movielens dataset,其評分資料格式為 user item rating timestamp,為了簡單,我們也把資料處理成這個格式。
# -*- coding:utf-8-*-
"""
對網易雲所有歌單爬蟲的json檔案進行資料預處理成csv檔案
python3.6環境
"""
from __future__ import (absolute_import, division, print_function, unicode_literals)
import json
def parse_playlist_item():
"""
:return: 解析成userid itemid rating timestamp行格式
"""
file = open("neteasy_playlist_recommend_data.csv", 'a', encoding='utf8')
for i in range(1, 1292):
with open("neteasy_playlist_data/{0}.json".format(i), 'r', encoding='UTF-8') as load_f:
load_dict = json.load(load_f)
try:
for item in load_dict['playlist']['tracks']:
# playlist id # song id # score # datetime
line_result = [load_dict['playlist']['id'], item['id'], item['pop'], item['publishTime']]
for k, v in enumerate(line_result):
if k == len(line_result) - 1:
file.write(str(v))
else:
file.write(str(v) + ',')
file.write('\n')
except Exception:
print(i)
continue
file.close()
def parse_playlist_id_to_name():
file = open("neteasy_playlist_id_to_name_data.csv", 'a', encoding='utf8')
for i in range(1, 1292):
with open("neteasy_playlist_data/{0}.json".format(i), 'r', encoding='UTF-8') as load_f:
load_dict = json.load(load_f)
try:
line_result = [load_dict['playlist']['id'], load_dict['playlist']['name']]
for k, v in enumerate(line_result):
if k == len(line_result) - 1:
file.write(str(v))
else:
file.write(str(v) + ',')
file.write('\n')
except Exception:
print(i)
continue
file.close()
def parse_song_id_to_name():
file = open("neteasy_song_id_to_name_data.csv", 'a', encoding='utf8')
for i in range(1, 1292):
with open("neteasy_playlist_data/{0}.json".format(i), 'r', encoding='UTF-8') as load_f:
load_dict = json.load(load_f)
try:
for item in load_dict['playlist']['tracks']:
# playlist id # song id # score # datetime
line_result = [item['id'], item['name'] + '-' + item['ar'][0]['name']]
for k, v in enumerate(line_result):
if k == len(line_result) - 1:
file.write(str(v))
else:
file.write(str(v) + ',')
file.write('\n')
except Exception:
print(i)
continue
file.close()
# parse_playlist_item()
# parse_playlist_id_to_name()
# parse_song_id_to_name()5. 資料說明
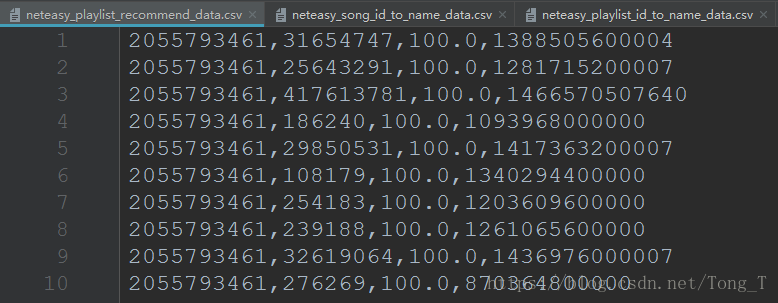
我們需要儲存 歌單id=>歌單名 和 歌曲id=>歌曲名 的資訊後期備用。
歌曲id=>歌曲名:
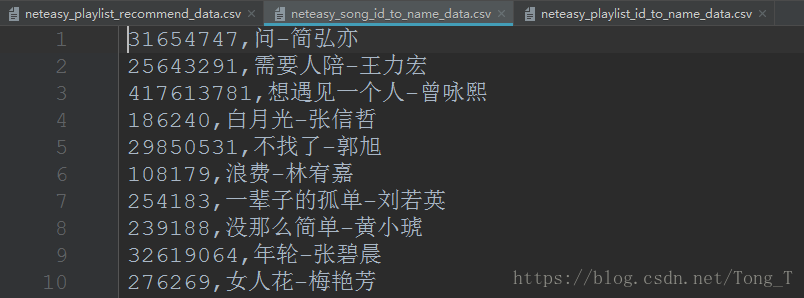
歌單id=>歌單名:
6. 推薦系統常見的工程化做法
project = offline modelling + online prediction
1)offline
python指令碼語言
2)online
效率至上 C++/Java
原則:能離線預先算好的,都離線算好,最優的形式:線上是一個K-V字典
1.針對使用者推薦 網易雲音樂(每日30首歌/7首歌)
2.針對歌曲 在你聽某首歌的時候,找“相似歌曲”
7. Surprise推薦庫簡單介紹
在推薦系統的建模過程中,我們將用到python庫 Surprise(Simple Python RecommendatIon System Engine),是scikit系列中的一個(很多同學用過scikit-learn和scikit-image等庫)。
8. 網易雲音樂歌單推薦
利用surprise推薦庫中KNN協同過濾演算法進行已有資料的建模,並且推薦相似的歌單預測
# -*- coding:utf-8-*-
"""
利用surprise推薦庫 KNN協同過濾演算法推薦網易雲歌單
python2.7環境
"""
from __future__ import (absolute_import, division, print_function, unicode_literals)
import os
import csv
from surprise import KNNBaseline, Reader, KNNBasic, KNNWithMeans,evaluate
from surprise import Dataset
def recommend_model():
file_path = os.path.expanduser('neteasy_playlist_recommend_data.csv')
# 指定檔案格式
reader = Reader(line_format='user item rating timestamp', sep=',')
# 從檔案讀取資料
music_data = Dataset.load_from_file(file_path, reader=reader)
# 計算歌曲和歌曲之間的相似度
train_set = music_data.build_full_trainset()
print('開始使用協同過濾演算法訓練推薦模型...')
algo = KNNBasic()
algo.fit(train_set)
return algo
def playlist_data_preprocessing():
csv_reader = csv.reader(open('neteasy_playlist_id_to_name_data.csv'))
id_name_dic = {}
name_id_dic = {}
for row in csv_reader:
id_name_dic[row[0]] = row[1]
name_id_dic[row[1]] = row[0]
return id_name_dic, name_id_dic
def song_data_preprocessing():
csv_reader = csv.reader(open('neteasy_song_id_to_name_data.csv'))
id_name_dic = {}
name_id_dic = {}
for row in csv_reader:
id_name_dic[row[0]] = row[1]
name_id_dic[row[1]] = row[0]
return id_name_dic, name_id_dic
def playlist_recommend_main():
print("載入歌單id到歌單名的字典對映...")
print("載入歌單名到歌單id的字典對映...")
id_name_dic, name_id_dic = playlist_data_preprocessing()
print("字典對映成功...")
print('構建資料集...')
algo = recommend_model()
print('模型訓練結束...')
current_playlist_id = id_name_dic.keys()[200]
print('當前的歌單id:' + current_playlist_id)
current_playlist_name = id_name_dic[current_playlist_id]
print('當前的歌單名字:' + current_playlist_name)
playlist_inner_id = algo.trainset.to_inner_uid(current_playlist_id)
print('當前的歌單內部id:' + str(playlist_inner_id))
playlist_neighbors = algo.get_neighbors(playlist_inner_id, k=10)
playlist_neighbors_id = (algo.trainset.to_raw_uid(inner_id) for inner_id in playlist_neighbors)
# 把歌曲id轉成歌曲名字
playlist_neighbors_name = (id_name_dic[playlist_id] for playlist_id in playlist_neighbors_id)
print("和歌單<", current_playlist_name, '> 最接近的10個歌單為:\n')
for playlist_name in playlist_neighbors_name:
print(playlist_name, name_id_dic[playlist_name])
playlist_recommend_main()
# "E:\ProgramingSoftware\PyCharm Community Edition 2016.2.3\Anaconda2\python2.exe" C:/Users/Administrator/Desktop/部落格素材/recommend_system_learning/recommend_main.py
# 載入歌單id到歌單名的字典對映...
# 載入歌單名到歌單id的字典對映...
# 字典對映成功...
# 構建資料集...
# 開始使用協同過濾演算法訓練推薦模型...
# Computing the msd similarity matrix...
# Done computing similarity matrix.
# 模型訓練結束...
# 當前的歌單id:2056644233
# 當前的歌單名字:暖陽微醺◎來碗甜度100%的糖水吧
# 當前的歌單內部id:444
# 和歌單< 暖陽微醺◎來碗甜度100%的糖水吧 > 最接近的10個歌單為:
#
# 2018全年抖腿指南,老鐵你怕了嗎? 2050704516
# 2018歐美最新流行單曲推薦【持續更新】 2042762698
# 「女毒電子」●酒心巧克力般的甜蜜圈套 2023282769
# 『 2018優質新歌電音推送 』 2000367772
# 那些為電音畫龍點睛的驚豔女Vocals 2081768956
# 女嗓篇 |不可以這麼俏皮清新 我會喜歡你的 2098623867
# 「柔美唱腔」時光不敵粉嫩少女心 2093450772
# 「節奏甜食」次點甜醹發酵的牛奶草莓 2069080336
# 03.23 ✘ 歐美熱浪新歌 ‖ 周更向 2151684623
# 開門呀 小可愛送溫暖 2151816466
#
# Process finished with exit code 0協同過濾模型的評估驗證方法:
file_path = os.path.expanduser('neteasy_playlist_recommend_data.csv')
# 指定檔案格式
reader = Reader(line_format='user item rating timestamp', sep=',')
# 從檔案讀取資料
music_data = Dataset.load_from_file(file_path, reader=reader)
# 分成5折
music_data.split(n_folds=5)
algo = KNNBasic()
perf = evaluate(algo, music_data, measures=['RMSE', 'MAE'])
print(perf)
"""
Evaluating RMSE, MAE of algorithm KNNBasic.
------------
Fold 1
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 85.4426
MAE: 82.4766
------------
Fold 2
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 85.2970
MAE: 82.0756
------------
Fold 3
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 85.2267
MAE: 82.0697
------------
Fold 4
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 85.3390
MAE: 82.1538
------------
Fold 5
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 86.0862
MAE: 83.2907
------------
------------
Mean RMSE: 85.4783
Mean MAE : 82.4133
------------
------------
defaultdict(<type 'list'>, {u'mae': [82.476559473072456, 82.075552111584656, 82.069740410693527, 82.153816350251844, 83.29069767441861], u'rmse': [85.442585928330303, 85.29704915378538, 85.22667089592963, 85.339041675515148, 86.086152088447705]})
"""