
用 Prometheus 來監控你的 Kubernetes 叢集_Kubernetes中文社群
本文是才雲科技(CaiCloud)5月6日沙龍“Kubernetes Meetup 中國 2017”才雲的首席架構師唐鵬程的演講實錄。

大家下午好,我是才雲科技的唐鵬程,今天演講的題目是《Monitoring Kubernetes cluster with prometheus》,我知道在坐很多人已經在實際應用 Kubernetes 了,並且在各個業務部門的應用容器化之後,已經可以在 K8S 裡面正常執行。在正常執行之後,公司內部就需要一些運維團隊對整個系統的應用進行相關維護。一旦出現問題可以進行相應的操作,而這時候我們就需要一個監控系統。

我們來思考一下為什麼需要這樣一款監控系統,首先運維人員不可能一直盯著機器,你需要監控面板告訴你係統的執行狀態,比如說我這個K8 叢集裡面每個節點 CPU 的利用率,或者我的應用上 API 呼叫的延遲是多少?這些都可以從監控圖很輕鬆得到。
當機器或者應用出問題的時候,監控系統會為我們提供方向。比如我們突然從監控圖上看到 Web 服務的 API 呼叫響應延遲變高了,又或者我們看到這個應用執行的這個節點 CPU 佔用率很高,那就可以有一個大膽的猜測,是不是 CPU 數量不夠,這樣我們就能有大方向的指導,雖然不一定完全正確。
當然,監控系統雖然給我們提供了監控圖,運維人員在實際應用過程中也不可能每天盯著這個圖。那我們就需要監控系統會提供一些報警的功能,比如機器 CPU 過高,可以給我們的運維人員傳送提示資訊。

那這樣的監控系統需要提供什麼東西呢?他首先需要定義一個數據結構,我們知道這些機器或者應用的監控資料沒有統一的格式,比如應用直接會打出來一些日誌,又或者有一些輸出監控資料的介面,那監控系統就需要提供一些統一的資料模型,這也是資料監控的基礎。
我們既然有這麼多的監控資料,那監控系統就需要定位一個統一的收集方式,怎麼來收集這些監控資料。然後要考慮怎麼存這些資料是最高效的,最後當我拿到了這些資料之後,我們需要用這些資料繪製監控圖,那這個時候監控系統還是要提供一個查詢的介面。這是我認為監控系統需要定義的一些東西。

回到我們今天的主題,我們知道目前市面上有很多監控元件,但今天我們將重點介紹 Prometheus 。它最早是借鑑了 Google 的 Borgmon 系統,完全是開源的,也是CNCF 下繼 K8S 之後第二個專案。它們的開發人員都是原 Google 的 SRE,通過 HTTP 的方式來做資料收集,對其最深遠的應該是其被設計成一個 self sustained 的系統,也就是說它是完全獨立的系統,不需要外部依賴。
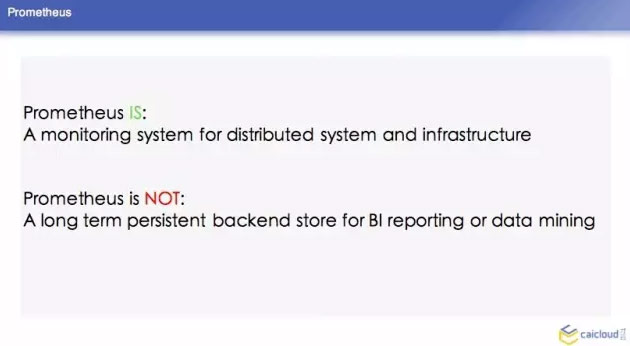
介紹完 Prometheus 的背景,我們可以看到這裡有兩點 Prometheus 的概述:首先,Prometheus 是一個監控系統,它可以監控你的基礎設施。如果你想把它作為一個後期大資料分析或者 BI 報告的 backend,Prometheus 不是你的第一選擇。我剛才也說到了,它是獨立的一個系統,它自己的儲存都是存在本地,沒有考慮用一些外部儲存來持久化這些資料,所以它不是持久的資料庫。它只可以儲存一週或者幾周的資料,方便你去做一個監控。
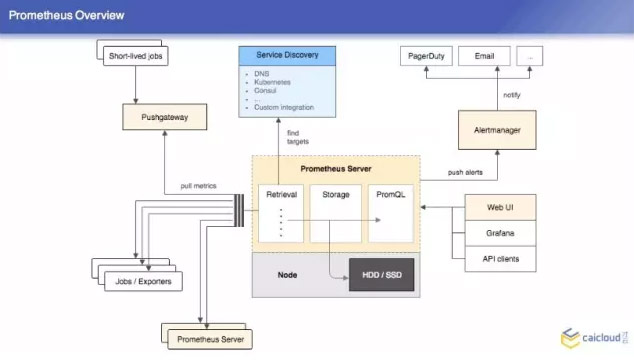
那我們在討論一個系統的時候,不可避免要看它的架構圖,Prometheus 的架構圖非常簡單,這裡面有三塊東西,首先是 Retrieval,這個裡面定義的是什麼?我這個 Prometheus 的伺服器在哪裡拉取資料,也可以從其他的 Prometheus 的伺服器拉取資料。
我們可能有很多會跑一些執行,然後就退出了,在這個 short lived jobs 裡面,他就是在這個拉完之後執行到下面,這裡面都是一些靜態定義的拉取目標, Prometheus 還可以支援動態的,比如說 DNS 等,這一塊是 Retrieval,然後第二塊是 Storage,當然也有一些外掛儲存的方式,這都是我們在做監控的環節下不需要的。最後就是 promQL,通過這個可以直接查詢。
右上角就是做報警的,它跟 Prometheus 是分開的兩個專案,比如說我這個機器的 CPU 超過兩個核之後要報警,Prometheus 就週期檢驗這些規則,這個就對 Prometheus 發過來的東西進行聚合押禁,這也是一個架構圖,比較簡單。

我們可以看一下這個 Prometheus 的資料格式是什麼樣的,也非常簡單,非常容易理解。你這個 metric,後面是 label,然後你可以用這種 label 選到你想要的持續資料。底下是 Prometheus 做的一些查詢,這個是他的一個數據的結構。
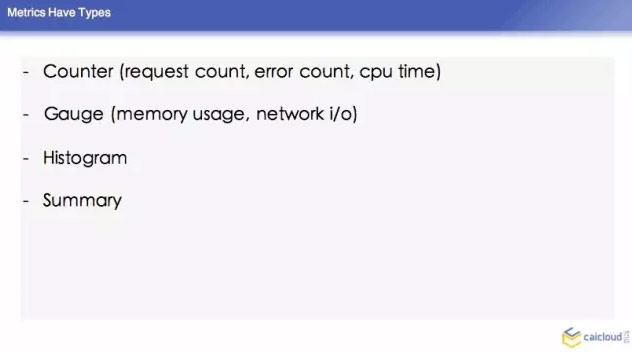
然後這個裡面,它裡面的 counter,有 error count,還有 CPU time,對於這些又會增又會減的,有一個叫 Gauge 的型別,下面兩種是比較複雜的一些指標,histogram 就是柱狀圖,還有 summary,這兩個不做介紹了。我們可能平時要算這個,可能要通過這兩個指標來做。


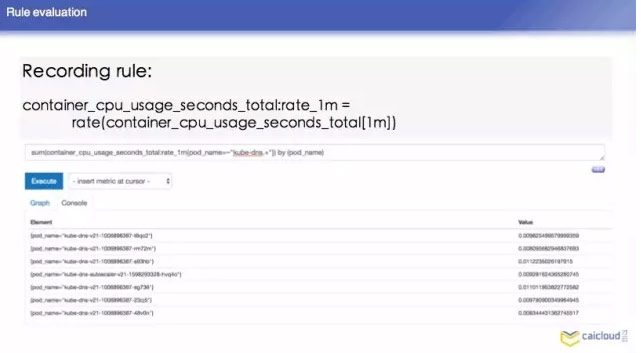
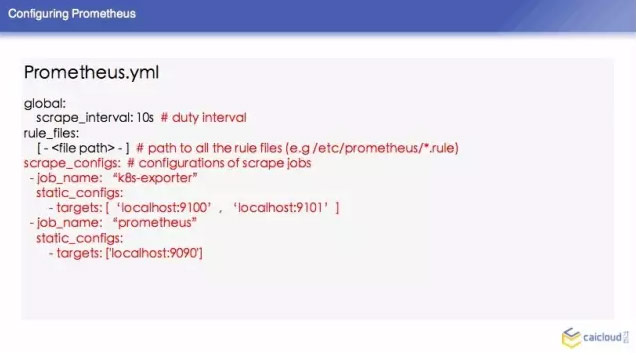
Prometheus 怎麼樣來配置,由於時間關係,我簡單列了一些常見的。然後這個 surape interval 10 秒,可以根據某個規則發出來,還有 recording rule,你這個程式每在CPU執行一段時間,就把這次執行在 CPU 的時間加在 CPU time 上面。這個東西怎麼算?他需要對 CPU suage 上面進行計算,需要做一個運算,這個查詢比較慢,我們可以寫這樣一個表示式,把這個指標複製給另外一個指標,查詢的時候,就可以直接查這個指標得到 CPU 的使用量。這個也是每隔一段時間做一些檢驗的,下面有一些例子。
再下面就是告訴 Prometheus 要去哪裡拉資料,然後他定義的 Targets 是 local host 9100 和 local host 9101,那麼我們可以想像一下在這個 K8S 環節中,我們 K8S 是非常動態的環節,我們不可能把所有的東西都寫在靜態的配置檔案裡面,那下面講一下 Prometheus 怎麼跟 K8S 做一個結合的。

這裡舉了一個例子,我們知道 K8S 每個節點都有進行整合。然後他會通過一個路徑把容器的指標暴露出去,這個時候我們在 Prometheus 裡面怎麼配呢?這是一個名詞,我現在告訴 Prometheus 我的 Jobmame,用的 Kubernetes nodes,Prometheus 知道它要去 K8S 裡面去知道 nodes,然後暴露地址去拉取資料。
下面這個 relabel config 呢,對這些標籤進行操作,這個操作是因為我們 K8S 裡面可以打上很多標籤,我們可以知道查詢的時候,知道其他的一些指標,它是在哪臺機器。




我們剛才通過一個例子給大家講了一下怎麼拉取容器的指標,那這個 K8S 系統裡面運行了其他的資料怎麼辦?這些東西的指標怎麼辦呢?這個 Prometheus 有一個概念叫 Databases,通過第三方系統服務暴露了一些指標,Prometheus 它不懂,把這些指標轉換成 Prometheus 可以理解的資料格式,然後從路徑去暴露出來。這底下有一個連結,這個連結有已經實現的東西。

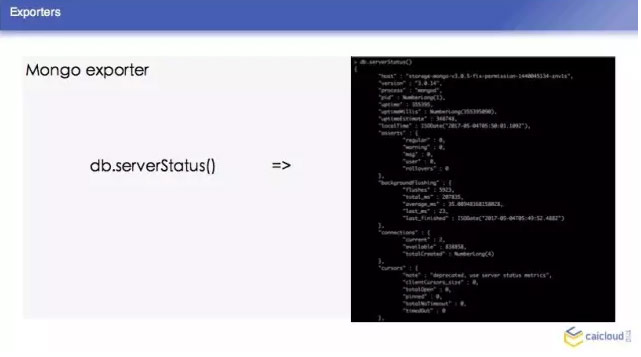
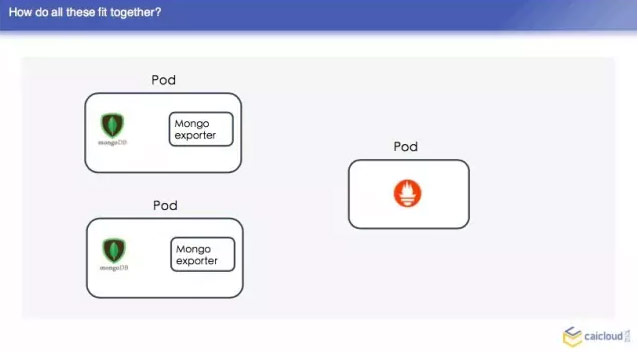
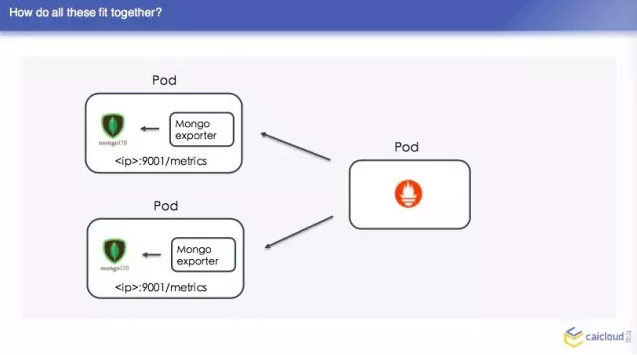
我們這裡再去舉一個 Mongo exporter 的例子,我們首先知道 Mongo exporter 的 db.server Status,部署一個 Mongo,我可以配置我的 Mongo 在哪裡,然後就知道在哪裡取這個資料,然後從什麼地方把資料暴露給 Prometheus,讓 Prometheus 來採。最後把這樣一個 Mongo 取到的資料轉換為 Prometheus 能夠理解的格式。
在整個的資料中,我們 Prometheus 不屬於 pod 的,現在 Prometheus 的 pod,他先去另一個地方有多少個 pod,找到之後然後找 Mongo exporter的pod,這個 pod 裡面跑了兩個容器,一個是 Mongo,一個是 exparter,把這些監控資料暴露出來,然後這個 Prometheus 直接去兩個地方取了,這樣就可以得到兩個監控資料了,我們去查詢頁面也可以查到。
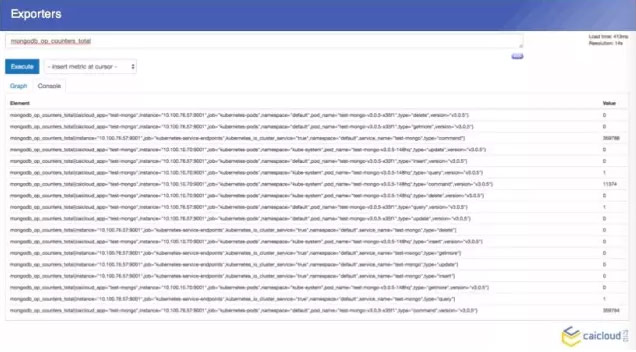
然後我們把這些東西部署出來之後,可能有人又要問了,我們這個服務,即使我們內部監控資料量特別大,這裡有一個從 Brian Brazil 他在部落格寫的一個數據,單個的 Prometheus 資料可以輕鬆出來幾百萬的時間序列。單個的 Prometheus 還是比較輕鬆出來的。當我們超過了這個資料,我們需要考慮一些其他的方案了。

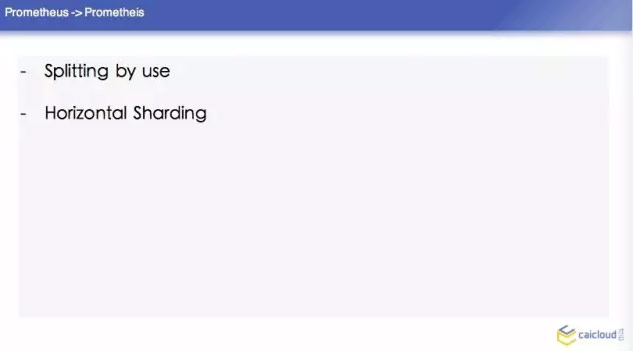
這裡順便提一個冷知識,就是 Prometheus 是古希臘裡面的人物。第一種是 splitting by use,然後這個單獨去建這個叢集,單個的 Prometheus 去查詢,這是最簡單的方案。比如你分擔一部分資料也沒有辦法做怎麼辦呢?就是 Horizontal Shardding,這裡分了三個 Prom,每個 Prom 分一個 Prometheus 去採,這樣去做一個彙總。
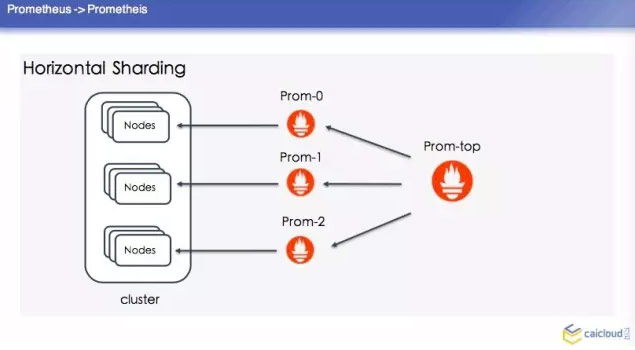
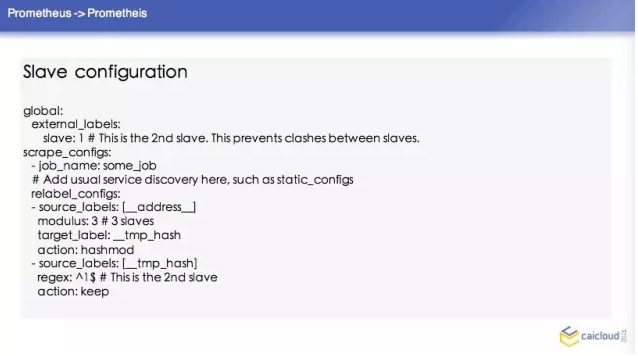
如果這樣去配置的話,這個 Prometheus 的叢集怎麼寫呢?這裡也舉了一個例子,首先這三個 Prometheus 的配置,他們的配置都基本差不多。比如說這個 slave,他這個輸出的資料我都給打一個 slave:1,我告訴這個 Prometheus 他要採哪些資料,這裡是怎麼寫的?他這裡是按照 source labels 做了一個操作。然後再對這個進行操作,如果匹配了1,那我的 action 就是 keep。

那他這個 Top level configuration 怎麼去配置呢?他要在 federate 去採,然後他去採所有的 slave level 地址的持續資料,這個我們的樹狀結構的 Prometheus 就配置完了。
我們知道對於一個監控系統來說,系統掛了,還是希望在監控系統看到一些東西,那 Prometheus 的 HA 系統非常簡單,你用同樣的資料跑兩個 Prometheus。這裡又有人會有問題了,當我們去討論一個分散式的儲存的時候,我們沒辦法討論他的理論。
我們在 Consistenc 和 Availability 和 Partition Tolerance當中選兩個,監控資料是海量的,如果你丟幾個資料點是沒有關係的。說到這一塊,我今天分享的內容已經基本結束了,最後給大家總結一下。

我們在選取一個監控系統的時候,還是更多要根據我們內部的實際情況,比如說我們對這個監控資料、大資料處理完全沒有需求的時候,我們完全沒有必要給 Prometheus 外掛一些資料。
一旦你分散式的資料庫出了問題,你的監控系統也用不了,我們在選的時候還是要根據實際情況。如果我們內部的需求就是要做這樣一個數據分析,監控資料對我們來說都是非常有價值的,我們要把這些資料存一年、兩年,我們就要付出一些代價。
我今天的分享就到此結束,謝謝大家!