
《深入理解mybatis原理(三)》 MyBatis的一級快取實現詳解 及使用注意事項
0.寫在前面
MyBatis是一個簡單,小巧但功能非常強大的ORM開源框架,它的功能強大也體現在它的快取機制上。MyBatis提供了一級快取、二級快取 這兩個快取機制,能夠很好地處理和維護快取,以提高系統的效能。本文的目的則是向讀者詳細介紹MyBatis的一級快取,深入原始碼,解析MyBatis一級快取的實現原理,並且針對一級快取的特點提出了在實際使用過程中應該注意的事項。
1. 什麼是一級快取? 為什麼使用一級快取?
每當我們使用MyBatis開啟一次和資料庫的會話,MyBatis會創建出一個SqlSession物件表示一次資料庫會話。
在對資料庫的一次會話中,我們有可能會反覆地執行完全相同的查詢語句,如果不採取一些措施的話,每一次查詢都會查詢一次資料庫,而我們在極短的時間內做了完全相同的查詢,那麼它們的結果極有可能完全相同,由於查詢一次資料庫的代價很大,這有可能造成很大的資源浪費。
為了解決這一問題,減少資源的浪費,MyBatis會在表示會話的SqlSession
物件中建立一個簡單的快取,將每次查詢到的結果結果快取起來,當下次查詢的時候,如果判斷先前有個完全一樣的查詢,會直接從快取中直接將結果取出,返回給使用者,不需要再進行一次資料庫查詢了。如下圖所示,MyBatis會在一次會話的表示----一個SqlSession物件中建立一個本地快取(local cache),對於每一次查詢,都會嘗試根據查詢的條件去本地快取中查詢是否在快取中,如果在快取中,就直接從快取中取出,然後返回給使用者;否則,從資料庫讀取資料,將查詢結果存入快取並返回給使用者。
對於會話(Session)級別的資料快取,我們稱之為一級資料快取,簡稱一級快取。
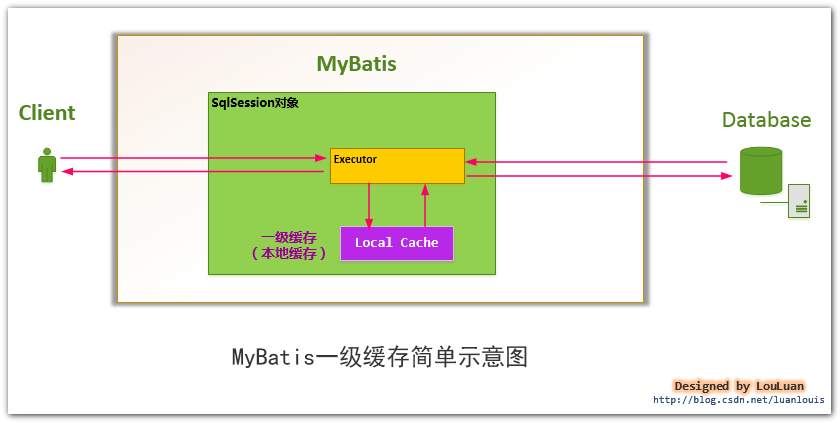
2. MyBatis中的一級快取是怎樣組織的?(即SqlSession中的快取是怎樣組織的?)
由於MyBatis使用SqlSession物件表示一次資料庫的會話,那麼,對於會話級別的一級快取也應該是在SqlSession中控制的。
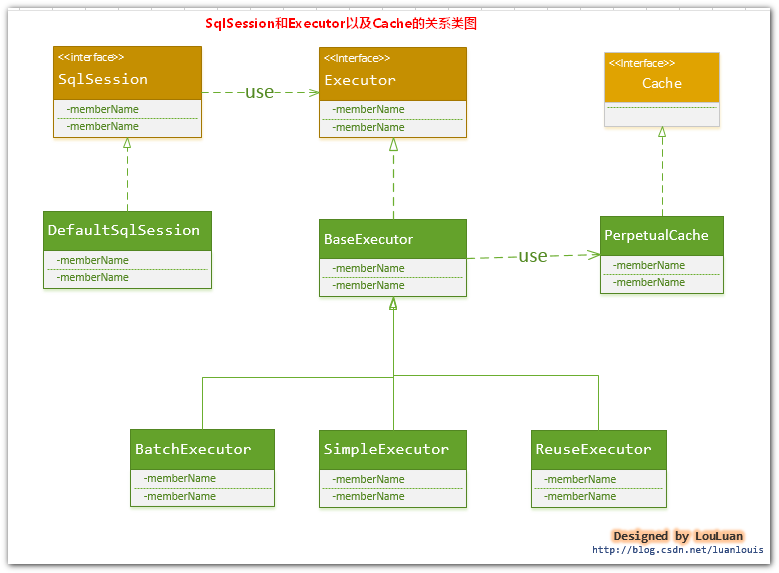
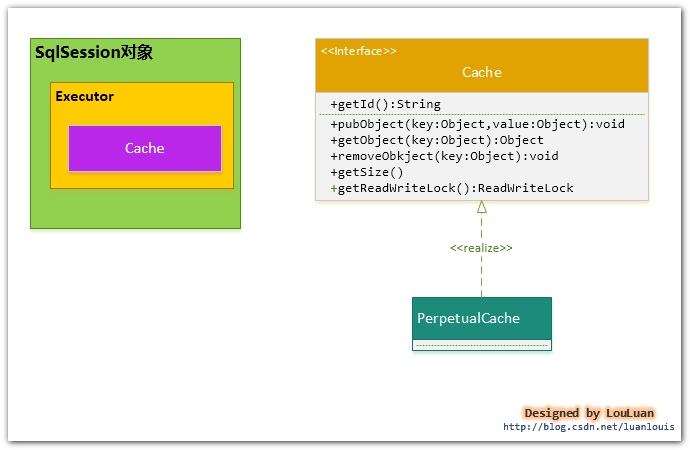
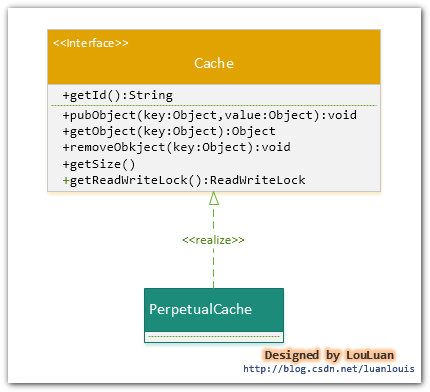
實際上, MyBatis只是一個MyBatis對外的介面,SqlSession將它的工作交給了Executor執行器這個角色來完成,負責完成對資料庫的各種操作。當建立了一個SqlSession物件時,MyBatis會為這個SqlSession物件建立一個新的Executor執行器,而快取資訊就被維護在這個Executor執行器中,MyBatis將快取和對快取相關的操作封裝成了Cache介面中。SqlSession、Executor、Cache之間的關係如下列類圖所示:
如上述的類圖所示,Executor介面的實現類BaseExecutor中擁有一個Cache介面的實現類PerpetualCache,則對於BaseExecutor物件而言,它將使用PerpetualCache物件維護快取。
綜上,SqlSession物件、Executor物件、Cache物件之間的關係如下圖所示:
由於Session級別的一級快取實際上就是使用PerpetualCache維護的,那麼PerpetualCache是怎樣實現的呢?
PerpetualCache實現原理其實很簡單,其內部就是通過一個簡單的HashMap<k,v> 來實現的,沒有其他的任何限制。如下是PerpetualCache的實現程式碼:
[java] view plain copy print?
- package org.apache.ibatis.cache.impl;
- import java.util.HashMap;
- import java.util.Map;
- import java.util.concurrent.locks.ReadWriteLock;
- import org.apache.ibatis.cache.Cache;
- import org.apache.ibatis.cache.CacheException;
- /**
- * 使用簡單的HashMap來維護快取
- * @author Clinton Begin
- */
- publicclass PerpetualCache implements Cache {
- private String id;
- private Map<Object, Object> cache = new HashMap<Object, Object>();
- public PerpetualCache(String id) {
- this.id = id;
- }
- public String getId() {
- return id;
- }
- publicint getSize() {
- return cache.size();
- }
- publicvoid putObject(Object key, Object value) {
- cache.put(key, value);
- }
- public Object getObject(Object key) {
- return cache.get(key);
- }
- public Object removeObject(Object key) {
- return cache.remove(key);
- }
- publicvoid clear() {
- cache.clear();
- }
- public ReadWriteLock getReadWriteLock() {
- returnnull;
- }
- publicboolean equals(Object o) {
- if (getId() == null) thrownew CacheException("Cache instances require an ID.");
- if (this == o) returntrue;
- if (!(o instanceof Cache)) returnfalse;
- Cache otherCache = (Cache) o;
- return getId().equals(otherCache.getId());
- }
- publicint hashCode() {
- if (getId() == null) thrownew CacheException("Cache instances require an ID.");
- return getId().hashCode();
- }
- }
package org.apache.ibatis.cache.impl; import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.ReadWriteLock; import org.apache.ibatis.cache.Cache; import org.apache.ibatis.cache.CacheException; /** * 使用簡單的HashMap來維護快取 * @author Clinton Begin */ public class PerpetualCache implements Cache { private String id; private Map<Object, Object> cache = new HashMap<Object, Object>(); public PerpetualCache(String id) { this.id = id; } public String getId() { return id; } public int getSize() { return cache.size(); } public void putObject(Object key, Object value) { cache.put(key, value); } public Object getObject(Object key) { return cache.get(key); } public Object removeObject(Object key) { return cache.remove(key); } public void clear() { cache.clear(); } public ReadWriteLock getReadWriteLock() { return null; } public boolean equals(Object o) { if (getId() == null) throw new CacheException("Cache instances require an ID."); if (this == o) return true; if (!(o instanceof Cache)) return false; Cache otherCache = (Cache) o; return getId().equals(otherCache.getId()); } public int hashCode() { if (getId() == null) throw new CacheException("Cache instances require an ID."); return getId().hashCode(); } }
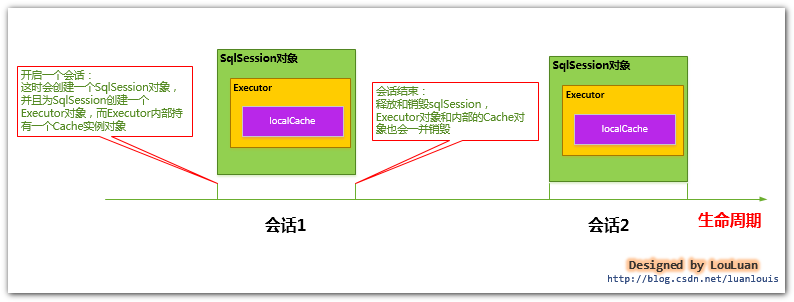
3.一級快取的生命週期有多長?
a. MyBatis在開啟一個數據庫會話時,會 建立一個新的SqlSession物件,SqlSession物件中會有一個新的Executor物件,Executor物件中持有一個新的PerpetualCache物件;當會話結束時,SqlSession物件及其內部的Executor物件還有PerpetualCache物件也一併釋放掉。
b. 如果SqlSession呼叫了close()方法,會釋放掉一級快取PerpetualCache物件,一級快取將不可用;
c. 如果SqlSession呼叫了clearCache(),會清空PerpetualCache物件中的資料,但是該物件仍可使用;
d.SqlSession中執行了任何一個update操作(update()、delete()、insert()) ,都會清空PerpetualCache物件的資料,但是該物件可以繼續使用;
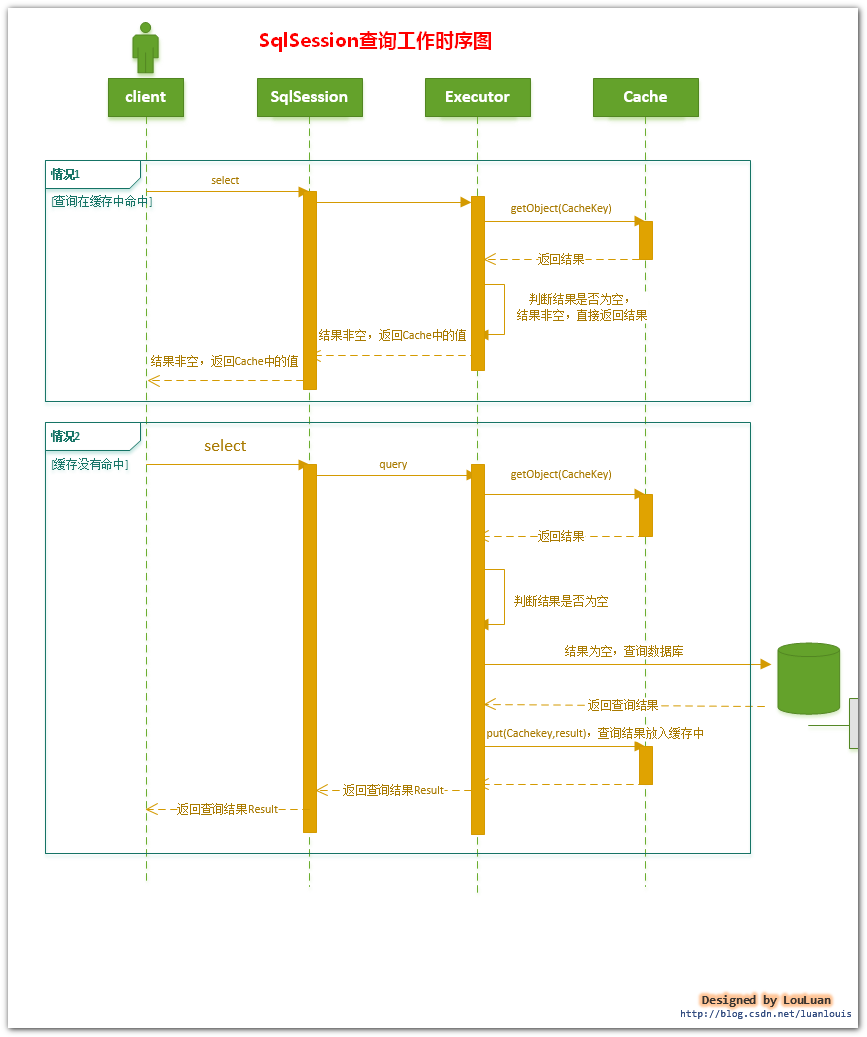
4. SqlSession 一級快取的工作流程:
1.對於某個查詢,根據statementId,params,rowBounds來構建一個key值,根據這個key值去快取Cache中取出對應的key值儲存的快取結果;
2. 判斷從Cache中根據特定的key值取的資料資料是否為空,即是否命中;
3. 如果命中,則直接將快取結果返回;
4. 如果沒命中:
4.1 去資料庫中查詢資料,得到查詢結果;
4.2 將key和查詢到的結果分別作為key,value對儲存到Cache中;
4.3. 將查詢結果返回;
5. 結束。[關於上述工作過程中 key值的構建,我們將在第下一節中重點探討,這也是MyBatis快取機制中非常重要的一個概念。]
5. Cache介面的設計以及CacheKey的定義(非常重要)
如下圖所示,MyBatis定義了一個org.apache.ibatis.cache.Cache介面作為其Cache提供者的SPI(Service Provider Interface) ,所有的MyBatis內部的Cache快取,都應該實現這一介面。MyBatis定義了一個PerpetualCache實現類實現了Cache介面,實際上,在SqlSession物件裡的Executor 物件內維護的Cache型別例項物件,就是PerpetualCache子類建立的。
(MyBatis內部還有很多Cache介面的實現,一級快取只會涉及到這一個PerpetualCache子類,Cache的其他實現將會放到二級快取中介紹)。
我們知道,Cache最核心的實現其實就是一個Map,將本次查詢使用的特徵值作為key,將查詢結果作為value儲存到Map中。
現在最核心的問題出現了:怎樣來確定一次查詢的特徵值?
換句話說就是:怎樣判斷某兩次查詢是完全相同的查詢?
也可以這樣說:如何確定Cache中的key值?
MyBatis認為,對於兩次查詢,如果以下條件都完全一樣,那麼就認為它們是完全相同的兩次查詢:
1. 傳入的 statementId
2. 查詢時要求的結果集中的結果範圍 (結果的範圍通過rowBounds.offset和rowBounds.limit表示);
3. 這次查詢所產生的最終要傳遞給JDBC Java.sql.Preparedstatement的Sql語句字串(boundSql.getSql())
4. 傳遞給java.sql.Statement要設定的引數值
現在分別解釋上述四個條件:
1. 傳入的statementId,對於MyBatis而言,你要使用它,必須需要一個statementId,它代表著你將執行什麼樣的Sql;
2. MyBatis自身提供的分頁功能是通過RowBounds來實現的,它通過rowBounds.offset和rowBounds.limit來過濾查詢出來的結果集,這種分頁功能是基於查詢結果的再過濾,而不是進行資料庫的物理分頁;
由於MyBatis底層還是依賴於JDBC實現的,那麼,對於兩次完全一模一樣的查詢,MyBatis要保證對於底層JDBC而言,也是完全一致的查詢才行。而對於JDBC而言,兩次查詢,只要傳入給JDBC的SQL語句完全一致,傳入的引數也完全一致,就認為是兩次查詢是完全一致的。
上述的第3個條件正是要求保證傳遞給JDBC的SQL語句完全一致;第4條則是保證傳遞給JDBC的引數也完全一致;
3、4講的有可能比較含糊,舉一個例子:
[html] view plain copy print?
- <selectid="selectByCritiera"parameterType="java.util.Map"resultMap="BaseResultMap">
- select employee_id,first_name,last_name,email,salary
- from louis.employees
- where employee_id = #{employeeId}
- and first_name= #{firstName}
- and last_name = #{lastName}
- and email = #{email}
- </select>
如果使用上述的"selectByCritiera"進行查詢,那麼,MyBatis會將上述的SQL中的#{}都替換成 ? 如下: [sql] view plain copy print?<select id="selectByCritiera" parameterType="java.util.Map" resultMap="BaseResultMap"> select employee_id,first_name,last_name,email,salary from louis.employees where employee_id = #{employeeId} and first_name= #{firstName} and last_name = #{lastName} and email = #{email} </select>
- select employee_id,first_name,last_name,email,salary
- from louis.employees
- where employee_id = ?
- and first_name= ?
- and last_name = ?
- and email = ?
MyBatis最終會使用上述的SQL字串建立JDBC的java.sql.PreparedStatement物件,對於這個PreparedStatement物件,還需要對它設定引數,呼叫setXXX()來完成設值,第4條的條件,就是要求對設定JDBC的PreparedStatement的引數值也要完全一致。select employee_id,first_name,last_name,email,salary from louis.employees where employee_id = ? and first_name= ? and last_name = ? and email = ?即3、4兩條MyBatis最本質的要求就是:
呼叫JDBC的時候,傳入的SQL語句要完全相同,傳遞給JDBC的引數值也要完全相同。
綜上所述,CacheKey由以下條件決定:
statementId + rowBounds + 傳遞給JDBC的SQL + 傳遞給JDBC的引數值
一級快取的效能分析
我將從兩個 一級快取的特性來討論SqlSession的一級快取效能問題:
1.MyBatis對會話(Session)級別的一級快取設計的比較簡單,就簡單地使用了HashMap來維護,並沒有對HashMap的容量和大小進行限制。
讀者有可能就覺得不妥了:如果我一直使用某一個SqlSession物件查詢資料,這樣會不會導致HashMap太大,而導致 java.lang.OutOfMemoryError錯誤啊? 讀者這麼考慮也不無道理,不過MyBatis的確是這樣設計的。
相關推薦
《深入理解mybatis原理(三)》 MyBatis的一級快取實現詳解 及使用注意事項
0.寫在前面 MyBatis是一個簡單,小巧但功能非常強大的ORM開源框架,它的功能強大也體現在它的快取機制上。MyBatis提供了一級快取、二級快取 這兩個快取機制,能夠很好地處理和維護快取,以提高系統的效能。本文的目的則是向讀者詳細介紹MyBatis的一級快取,深入原始碼,解析MyBa
MyBatis 的一級快取實現詳解及使用注意事項
轉自:https://blog.csdn.net/chenyao1994/article/details/79233725 0.寫在前面 MyBatis是一個簡單,小巧但功能非常強大的ORM開源框架,它的功能強大也體現在它的快取機制上。MyBatis提供了一級快取、二級快取 這兩個快取機制,
MyBatis的一級快取實現詳解 及使用注意事項
0.寫在前面 MyBatis是一個簡單,小巧但功能非常強大的ORM開源框架,它的功能強大也體現在它的快取機制上。MyBatis提供了一級快取、二級快取 這兩個快取機制,能夠很好地處理和維護快取,以提高系統的效能。本文的目的則是向讀者詳細介紹MyBati
《深入理解mybatis原理6》 MyBatis的一級緩存實現詳解 及使用註意事項
net 特征值 session 成了 bool common 周期 當下 csdn 《深入理解mybatis原理》 MyBatis的一級緩存實現詳解 及使用註意事項 0.寫在前面 MyBatis是一個簡單,小巧但功能非常強大的ORM開源框架,它的功能強大也體現在它的
深入理解 Tomcat(三)Tomcat 底層實現原理
轉載自:https://blog.csdn.net/qq_38182963/article/details/78660777 又是一個週末,這篇文章將從一個簡單的例子來理解tomcat的底層設計; 本文將介紹 Java Web 伺服器是如何執行的, W
三:深入理解Nginx的模組化 (結合原始碼詳解)
盜用前面用到的流程圖 第二步實際上是呼叫 ngx_add_inherited_sockets() //檔名: Nginx.c int ngx_cdecl main(int argc,
三、mysql登錄詳解及版本號查詢
ppa l數據庫 server gpo 方法 win sql查詢 spa nbsp 1.用window+r,輸入cmd,用mysql -uuser -ppassword登錄時出現‘mysql’不是有效的內部命令? 答:這是因為沒有配置My
nginx學習三 nginx配置項解析詳解及程式碼實現
nginx配置項解析詳解及程式碼實現 0回顧 在上一節,用nginx簡單實現了一個hello world程式:當我們在瀏覽器中輸入lochost/hello ,瀏覽器就返回:hello world。為什麼會這樣呢,簡單一點說就是當我們請求訪問hello這個服務,ngi
《深入理解mybatis原理》 MyBatis快取機制的設計與實現
本文主要講解MyBatis非常棒的快取機制的設計原理,給讀者們介紹一下MyBatis的快取機制的輪廓,然後會分別針對快取機制中的方方面面展開討論。 MyBatis將資料快取設計成兩級結構,分為一級快取、二級快取: &nb
《深入理解mybatis原理》 MyBatis的二級快取的設計原理
MyBatis的二級快取是Application級別的快取,它可以提高對資料庫查詢的效率,以提高應用的效能。本文將全面分析MyBatis的二級快取的設計原理。 1.MyBatis的快取機制整體設計以及二級快取的工作模式
《深入理解mybatis原理》 Mybatis初始化機制詳解 侵立刪
對於任何框架而言,在使用前都要進行一系列的初始化,MyBatis也不例外。本章將通過以下幾點詳細介紹MyBatis的初始化過程。 1.MyBatis的初始化做了什麼 2. MyBatis基於XML配置檔案建立Configuration物件的過程 &nb
淺談Mybatis中session的一級快取的實現原理
最近由於受工作中業務需要和現有工程中dao層非orm思想的影響,覺得在有些業務場景下,並不一定非要去使用ORM框架,畢竟寫大量的實體類也是一件麻煩的事,於是著手編寫一個非ORM框架。初步完成後,底層的session並沒能像mybatis那樣能支援session的一級快取
《深入理解mybatis原理》 Mybatis資料來源與連線池
對於ORM框架而言,資料來源的組織是一個非常重要的一部分,這直接影響到框架的效能問題。本文將通過對MyBatis框架的資料來源結構進行詳盡的分析,並且深入解析MyBatis的連線池。 本文首先會講述MyBatis的資料來源的分類,然後會介紹資料來源是如何載入
《深入理解mybatis原理》 MyBatis的架構設計以及例項分析
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQ
《深入理解mybatis原理》 MyBatis的架構設計以及例項分析
MyBatis是目前非常流行的ORM框架,它的功能很強大,然而其實現卻比較簡單、優雅。本文主要講述MyBatis的架構設計思路,並且討論MyBatis的幾個核心部件,然後結合一個select查詢例項,深入程式碼,來探究MyBatis的實現。 一、MyBati
MyBatis (五)一級快取和二級快取的區別
什麼叫快取將資料存放在程式記憶體中,用於減輕資料查詢的壓力,提升讀取資料的速度,提高效能。一級快取■ 兩個級別SqlSession級別的快取,實現在同一個會話中資料的共享Statement級別的快取,可以理解為快取只對當前執行的這一個Statement有效,執行完後就會清空快
MyBatis 延遲載入,一級快取(sqlsession級別)、二級快取(mapper級別)設定
什麼是延遲載入 resultMap中的association和collection標籤具有延遲載入的功能。 延遲載入的意思是說,在關聯查詢時,利用延遲載入,先載入主資訊。使用關聯資訊時再去載入關聯資訊。 設定延遲載入
MyBatis如何禁用掉一級快取。
一級快取:同一個sqlsession裡面存在,快取用map儲存。 key:sqlsession.hashcode+statementId+sql value:查詢出來的物件。 二級快取:不同sqlsession之間共享查詢結果集。 1、 在配置檔案Sql
MyBatis 一級快取、二級快取全詳解(一)
目錄 MyBatis 一級快取、二級快取全詳解(一) 什麼是快取 什麼是MyBatis中的快取 MyBatis 中的一級快取 初探一級快取 探究一級快取是如何失效的
mybatis原始碼學習:一級快取和二級快取分析
[toc] 前文傳送門:[mybatis原始碼學習:從SqlSessionFactory到代理物件的生成](https://www.cnblogs.com/summerday152/p/12773121.html) # 零、一級快取和二級快取的流程 > 以這裡的查詢語句為例。 ## 一級快取總結 -