
Java常用訊息佇列原理介紹及效能對比
訊息佇列使用場景
為什麼會需要訊息佇列(MQ)?
解耦
在專案啟動之初來預測將來專案會碰到什麼需求,是極其困難的。訊息系統在處理過程中間插入了一個隱含的、基於資料的介面層,兩邊的處理過程都要實現這一介面。這允許你獨立的擴充套件或修改兩邊的處理過程,只要確保它們遵守同樣的介面約束。
冗餘
有些情況下,處理資料的過程會失敗。除非資料被持久化,否則將造成丟失。訊息佇列把資料進行持久化直到它們已經被完全處理,通過這一方式規避了資料丟失風險。許多訊息佇列所採用的”插入-獲取-刪除”正規化中,在把一個訊息從佇列中刪除之前,需要你的處理系統明確的指出該訊息已經被處理完畢,從而確保你的資料被安全的儲存直到你使用完畢。
擴充套件性
因為訊息佇列解耦了你的處理過程,所以增大訊息入隊和處理的頻率是很容易的,只要另外增加處理過程即可。不需要改變程式碼、不需要調節引數。擴充套件就像調大電力按鈕一樣簡單。
靈活性 & 峰值處理能力
在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量並不常見;如果為以能處理這類峰值訪問為標準來投入資源隨時待命無疑是巨大的浪費。使用訊息佇列能夠使關鍵元件頂住突發的訪問壓力,而不會因為突發的超負荷的請求而完全崩潰。
可恢復性
系統的一部分元件失效時,不會影響到整個系統。訊息佇列降低了程序間的耦合度,所以即使一個處理訊息的程序掛掉,加入佇列中的訊息仍然可以在系統恢復後被處理。
順序保證
在大多使用場景下,資料處理的順序都很重要。大部分訊息佇列本來就是排序的,並且能保證資料會按照特定的順序來處理。Kafka保證一個Partition內的訊息的有序性。
緩衝
在任何重要的系統中,都會有需要不同的處理時間的元素。例如,載入一張圖片比應用過濾器花費更少的時間。訊息佇列通過一個緩衝層來幫助任務最高效率的執行———寫入佇列的處理會盡可能的快速。該緩衝有助於控制和優化資料流經過系統的速度。
非同步通訊
很多時候,使用者不想也不需要立即處理訊息。訊息佇列提供了非同步處理機制,允許使用者把一個訊息放入佇列,但並不立即處理它。想向佇列中放入多少訊息就放多少,然後在需要的時候再去處理它們。
MQ常用的使用場景:
1. 程序間通訊和系統間的訊息通知,比如在分散式系統中。
2. 解耦,比如像我們公司有許多開發團隊,每個團隊負責業務的不同模組,各個開發團隊可以使用MQ來通訊。
3. 在一些高併發場景下,使用MQ的非同步特性。
訊息佇列和RPC對比
系統架構
RPC系統結構:
+----------+ +----------+
| Consumer | <=> | Provider |
+----------+ +----------+Consumer呼叫的Provider提供的服務。
Message Queue系統結構:
+--------+ +-------+ +----------+
| Sender | <=> | Queue | <=> | Receiver |
+--------+ +-------+ +----------+Sender傳送訊息給Queue;Receiver從Queue拿到訊息來處理。
功能特點
在架構上,RPC和Message Queue的差異點是,Message Queue有一箇中間結點Message Queue(broker),可以把訊息儲存。
訊息佇列的特點
- Message Queue把請求的壓力儲存一下,逐漸釋放出來,讓處理者按照自己的節奏來處理。
- Message Queue引入一下新的結點,讓系統的可靠性會受Message Queue結點的影響。
- Message Queue是非同步單向的訊息。傳送訊息設計成是不需要等待訊息處理的完成。
所以對於有同步返回需求,用Message Queue則變得麻煩了。
RPC的特點
- 同步呼叫,對於要等待返回結果/處理結果的場景,RPC是可以非常自然直覺的使用方式。RPC也可以是非同步呼叫。
- 由於等待結果,Consumer(Client)會有執行緒消耗。
如果以非同步RPC的方式使用,Consumer(Client)執行緒消耗可以去掉。但不能做到像訊息一樣暫存訊息/請求,壓力會直接傳導到服務Provider。
RPC適用場合說明
- 希望同步得到結果的場合,RPC合適。
- 希望使用簡單,則RPC;RPC操作基於介面,使用簡單,使用方式模擬本地呼叫。非同步的方式程式設計比較複雜。
- 不希望傳送端(RPC Consumer、Message Sender)受限於處理端(RPC Provider、Message Receiver)的速度時,使用Message Queue。
隨著業務增長,有的處理端處理量會成為瓶頸,會進行同步呼叫到非同步訊息的改造。這樣的改造實際上有調整業務的使用方式。
比如原來一個操作頁面提交後就下一個頁面會看到處理結果;改造後非同步訊息後,下一個頁面就會變成“操作已提交,完成後會得到通知”。
RPC不適用場合說明
RPC同步呼叫使用Message Queue來傳輸呼叫資訊。 上面分析可以知道,這樣的做法,傳送端是在等待,同時佔用一箇中間點的資源。變得複雜了,但沒有對等的收益。
對於返回值是void的呼叫,可以這樣做,因為實際上這個呼叫業務上往往不需要同步得到處理結果的,只要保證會處理即可。(RPC的方式可以保證呼叫返回即處理完成,使用訊息方式後這一點不能保證了。)
返回值是void的呼叫,使用訊息,效果上是把訊息的使用方式Wrap成了服務呼叫(服務呼叫使用方式成簡單,基於業務介面)。
常用的訊息佇列及使用場景
ActiveMQ
AcitveMQ是作為一種訊息儲存和分發元件,涉及到client與broker端資料互動的方方面面,它不僅要擔保訊息的儲存安全性,還要提供額外的手段來確保訊息的分發是可靠的。
ActiveMQ訊息傳送機制
Producer客戶端使用來發送訊息的, Consumer客戶端用來消費訊息;它們的協同中心就是ActiveMQ broker,broker也是讓producer和consumer呼叫過程解耦的工具,最終實現了非同步RPC/資料交換的功能。隨著ActiveMQ的不斷髮展,支援了越來越多的特性,也解決開發者在各種場景下使用ActiveMQ的需求。比如producer支援非同步呼叫;使用flow control機制讓broker協同consumer的消費速率;consumer端可以使用prefetchACK來最大化訊息消費的速率;提供”重發策略”等來提高訊息的安全性等。在此我們不詳細介紹。
一條訊息的生命週期如下:
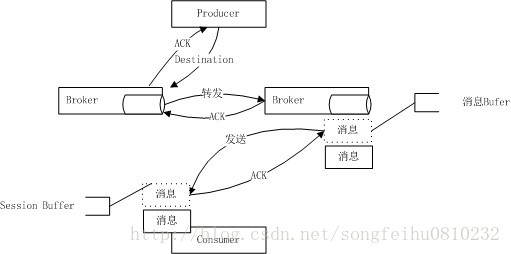
圖片中簡單的描述了一條訊息的生命週期,不過在不同的架構環境中,message的流動行可能更加複雜.將在稍後有關broker的架構中詳解..一條訊息從producer端發出之後,一旦被broker正確儲存,那麼它將會被consumer消費,然後ACK,broker端才會刪除;不過當訊息過期或者儲存裝置溢位時,也會終結它。
ActiveMQ的安裝
啟動後,activeMQ會佔用兩個埠,一個是負責接收發送訊息的tcp埠:61616,一個是基於web負責使用者介面化管理的埠:8161。這兩個埠可以在conf下面的xml中找到。http伺服器使用了jettry。這裡有個問題是啟動mq後,很長時間管理介面才可以顯示出來。可以使用netstat -an|find “61616”來測試ActiveMQ是否啟動。
Jms與ActiveMQ的結合
JMS是一個用於提供訊息服務的技術規範,它制定了在整個訊息服務提供過程中的所有資料結構和互動流程。而MQ則是訊息佇列服務,是面向訊息中介軟體(MOM)的最終實現,是真正的服務提供者;MQ的實現可以基於JMS,也可以基於其他規範或標準。目前選擇的最多的是ActiveMQ。
JMS支援兩種訊息傳遞模型:點對點(point-to-point,簡稱PTP)和釋出/訂閱(publish/subscribe,簡稱pub/sub)。這兩種訊息傳遞模型非常相似,但有以下區別:
- PTP訊息傳遞模型規定了一條訊息之恩能夠傳遞費一個接收方。
- Pub/sub訊息傳遞模型允許一條訊息傳遞給多個接收方
點對點模型
通過點對點的訊息傳遞模型,一個應用程式可以向另外一個應用程式傳送訊息。在此傳遞模型中,目標型別是佇列。訊息首先被傳送至佇列目標,然後從該佇列將訊息傳送至對此佇列進行監聽的某個消費者,如下圖:
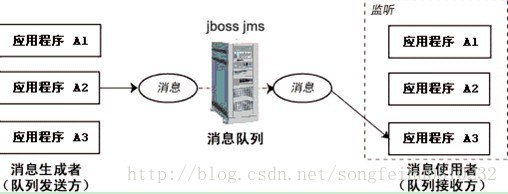
一個佇列可以關聯多個佇列傳送方和接收方,但一條訊息僅傳遞給一個接收方。如果多個接收方正在監聽佇列上的訊息,JMS Provider將根據“先來者優先”的原則確定由哪個價售房接受下一條訊息。如果沒有接收方在監聽佇列,訊息將保留在佇列中,直至接收方連線到佇列為止。這種訊息傳遞模型是傳統意義上的拉模型或輪詢模型。在此列模型中,訊息不時自動推動給客戶端的,而是要由客戶端從佇列中請求獲得。
點對點模型的程式碼(springboot+jms+activemq)實現如下:
@Service("queueproducer")
public class QueueProducer {
@Autowired // 也可以注入JmsTemplate,JmsMessagingTemplate對JmsTemplate進行了封裝
private JmsMessagingTemplate jmsMessagingTemplate;
// 傳送訊息,destination是傳送到的佇列,message是待發送的訊息
@Scheduled(fixedDelay=3000)//每3s執行1次
public void sendMessage(Destination destination, final String message){
jmsMessagingTemplate.convertAndSend(destination, message);
}
@JmsListener(destination="out.queue")
public void consumerMessage(String text){
System.out.println("從out.queue佇列收到的回覆報文為:"+text);
}
}Producer的實現
@Component
public class QueueConsumer2 {
// 使用JmsListener配置消費者監聽的佇列,其中text是接收到的訊息
@JmsListener(destination = "mytest.queue")
//SendTo 該註解的意思是將return回的值,再發送的"out.queue"佇列中
@SendTo("out.queue")
public String receiveQueue(String text) {
System.out.println("QueueConsumer2收到的報文為:"+text);
return "return message "+text;
}
}
Consumer的實現
@RunWith(SpringRunner.class)
@SpringBootTest
public class ActivemqQueueTests {
@Autowired
private QueueProducer producer;
@Test
public void contextLoads() throws InterruptedException {
Destination destination = new ActiveMQQueue("mytest.queue");
for(int i=0; i<10; i++){
producer.sendMessage(destination, "myname is Flytiger" + i);
}
}
}Test的實現
其中QueueConsumer2表明的是一個雙向佇列。
釋出/訂閱模型
通過釋出/訂閱訊息傳遞模型,應用程式能夠將一條訊息傳送到多個接收方。在此傳送模型中,目標型別是主題。訊息首先被傳送至主題目標,然後傳送至所有已訂閱此主題的或送消費者。如下圖:
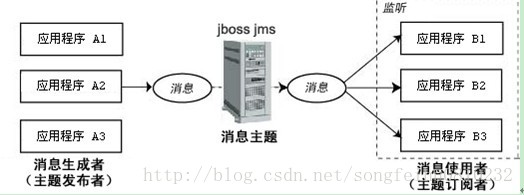
主題目標也支援長期訂閱。長期訂閱表示消費者已註冊了主題目標,但在訊息到達目標時該消費者可以處於非活動狀態。當消費者再次處於活動狀態時,將會接收該訊息。如果消費者均沒有註冊某個主題目標,該主題只保留註冊了長期訂閱的非活動消費者的訊息。與PTP訊息傳遞模型不同,pub/sub訊息傳遞模型允許多個主題訂閱者接收同一條訊息。JMS一直保留訊息,直至所有主題訂閱者都接收到訊息為止。pub/sub訊息傳遞模型基本上是一個推模型。在該模型中,訊息會自動廣播,消費者無須通過主動請求或輪詢主題的方法來獲得新的訊息。
上面兩種訊息傳遞模型裡,我們都需要定義訊息生產者和消費者,生產者把訊息傳送到JMS Provider的某個目標地址(Destination),訊息從該目標地址傳送至消費者。消費者可以同步或非同步接收訊息,一般而言,非同步訊息消費者的執行和伸縮性都優於同步訊息接收者,體現在:
1. 非同步訊息接收者建立的網路流量比較小。單向對東訊息,並使之通過管道進入訊息監聽器。管道操作支援將多條訊息聚合為一個網路呼叫。
2. 非同步訊息接收者使用執行緒比較少。非同步訊息接收者在不活動期間不使用執行緒。同步訊息接收者在接收呼叫期間內使用執行緒,結果執行緒可能會長時間保持空閒,尤其是如果該呼叫中指定了阻塞超時。
3. 對於伺服器上執行的應用程式程式碼,使用非同步訊息接收者幾乎總是最佳選擇,尤其是通過訊息驅動Bean。使用非同步訊息接收者可以防止應用程式程式碼在伺服器上執行阻塞操作。而阻塞操作會是伺服器端執行緒空閒,甚至會導致死鎖。阻塞操作使用所有執行緒時則發生死鎖。如果沒有空餘的執行緒可以處理阻塞操作自身解鎖所需的操作,這該操作永遠無法停止阻塞。
釋出/訂閱模型的程式碼(springboot+jms+activemq)實現如下:
@Service("topicproducer")
public class TopicProducer {
@Autowired // 也可以注入JmsTemplate,JmsMessagingTemplate對JmsTemplate進行了封裝
private JmsMessagingTemplate jmsMessagingTemplate;
// 傳送訊息,destination是傳送到的佇列,message是待發送的訊息
@Scheduled(fixedDelay=3000)//每3s執行1次
public void sendMessage(Destination destination, final String message){
jmsMessagingTemplate.convertAndSend(destination, message);
}
}Producer的實現
@Component
public class TopicConsumer2 {
// 使用JmsListener配置消費者監聽的佇列,其中text是接收到的訊息
@JmsListener(destination = "mytest.topic")
public void receiveTopic(String text) {
System.out.println("TopicConsumer2收到的topic報文為:"+text);
}
}Consumer的實現
@RunWith(SpringRunner.class)
@SpringBootTest
public class ActivemqTopicTests {
@Autowired
private TopicProducer producer;
@Test
public void contextLoads() throws InterruptedException {
Destination destination = new ActiveMQTopic("mytest.topic");
for(int i=0; i<3; i++){
producer.sendMessage(destination, "myname is TopicFlytiger" + i);
}
}
}Test的實現
Topic模式工作時,預設只能傳送和接收queue訊息,如果要傳送和接收topic訊息,需要加入:
spring.jms.pub-sub-domain=trueQueue與Topic的比較
JMS Queue執行load balancer語義
一條訊息僅能被一個consumer收到。如果在message傳送的時候沒有可用的consumer,那麼它講被儲存一直到能處理該message的consumer可用。如果一個consumer收到一條message後卻不響應它,那麼這條訊息將被轉到另外一個consumer那兒。一個Queue可以有很多consumer,並且在多個可用的consumer中負載均衡。Topic實現publish和subscribe語義
一條訊息被publish時,他將傳送給所有感興趣的訂閱者,所以零到多個subscriber將接收到訊息的一個拷貝。但是在訊息代理接收到訊息時,只有啟用訂閱的subscriber能夠獲得訊息的一個拷貝。分別對應兩種訊息模式
Point-to-Point(點對點),Publisher/Subscriber Model(釋出/訂閱者)
其中在Publicher/Subscriber模式下又有Nondurable subscription(非持久化訂閱)和durable subscription(持久化訂閱)兩種訊息處理方式。
ActiveMQ優缺點
優點:是一個快速的開源訊息元件(框架),支援叢集,同等網路,自動檢測,TCP,SSL,廣播,持久化,XA,和J2EE1.4容器無縫結合,並且支援輕量級容器和大多數跨語言客戶端上的Java虛擬機器。訊息非同步接受,減少軟體多系統整合的耦合度。訊息可靠接收,確保訊息在中介軟體可靠儲存,多個訊息也可以組成原子事務。
缺點:ActiveMQ預設的配置效能偏低,需要優化配置,但是配置檔案複雜,ActiveMQ本身不提供管理工具;示例程式碼少;主頁上的文件看上去比較全面,但是缺乏一種有效的組織方式,文件只有片段,使用者很難由淺入深進行了解,二、文件整體的專業性太強。在研究階段可以通過查maillist、看Javadoc、分析原始碼來了解。
RabbitMQ
簡介
需要注意的是:
多個消費者可以訂閱同一個Queue,這時Queue中的訊息會被平均分攤給多個消費者進行處理,而不是每個消費者都收到所有的訊息並處理。這種分發方式叫做round-robin(迴圈的方式)。
當publisher將訊息發給queue的過程中,publisher會指明routing key。Direct模式中,Direct Exchange 根據 Routing Key 進行精確匹配,只有對應的 Message Queue 會接受到訊息。Topic模式中Exchange會根據routing key和bindkey進行模式匹配,決定將訊息傳送到哪個queue中。
有一個疑問:當有多個consumer時,rabbitmq會平均分攤給這些consumer;沒辦法把同一個message發給不同的consumer嗎?
我之前的猜想是,當有多個consumer使用topic模式訂閱訊息時,所有的訊息它們都會收到;但如果是direct模式,只有一個consumer會收到訊息。(理解錯誤,topic和direct只是publisher用來選擇發到不同的queue,不是consumer接收訊息。一個佇列一個訊息只能傳送給一個消費者,不然消費者的ack也會有很多,RabbitMQ Server也不好處理)
RabbitMQ的訊息確認
預設情況下,如果Message 已經被某個Consumer正確的接收到了,那麼該Message就會被從queue中移除。當然也可以讓同一個Message傳送到很多的Consumer。
如果一個queue沒被任何的Consumer Subscribe(訂閱),那麼,如果這個queue有資料到達,那麼這個資料會被cache,不會被丟棄。當有Consumer時,這個資料會被立即傳送到這個Consumer,這個資料被Consumer正確收到時,這個資料就被從queue中刪除。
那麼什麼是正確收到呢?通過ack。每個Message都要被acknowledged(確認,ack)。我們可以顯示的在程式中去ack,也可以自動的ack。如果有資料沒有被ack,那麼:
RabbitMQ Server會把這個資訊傳送到下一個Consumer。而且ack的機制可以起到限流的作用(Benefitto throttling):在Consumer處理完成資料後傳送ack,甚至在額外的延時後傳送ack,將有效的balance Consumer的load。
RabbitMQ高可用方案
RabbitMQ有以下幾種叢集模式:
普通模式(預設)
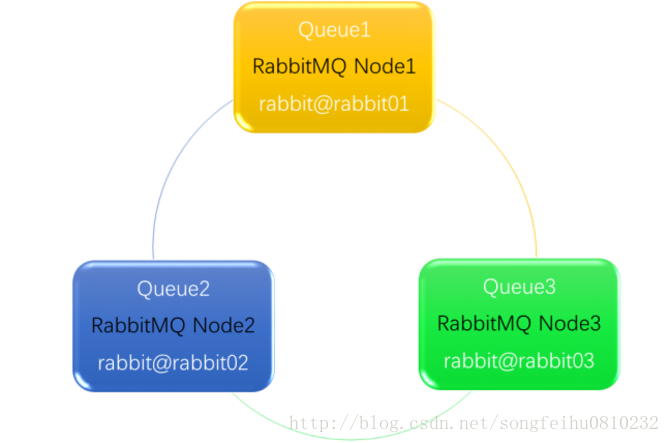
上圖是由3個節點(Node1,Node2,Node3)組成的RabbitMQ普通叢集環境,Exchange A的元資料資訊在所有節點上是一致的;而Queue的完整資訊只有在建立它的節點上,各個節點僅有相同的元資料,即佇列結構。
當producer傳送訊息到Node1節點的Queue1中後,consumer從Node3節點拉取時,RabbitMQ會臨時在Node1、Node3間進行訊息傳輸,把Node1中的訊息實體取出並經過Node3傳送給consumer。
該模式存在一個問題:當Node1節點發生故障後,Node3節點無法取到Node1節點中還未被消費的訊息實體。如果訊息沒做持久化,那麼訊息將永久性丟失;如果做了持久化,那麼只有等Node1節點故障恢復後,訊息才能被其他節點消費。
對於publish,客戶端任意連線叢集的一個節點,轉發給建立queue的節點儲存訊息的所有資訊;
對於consumer,客戶端任意連線叢集中的一個節點,如果資料不在該節點中,則從儲存該訊息data的節點拉取。可見當儲存有queue內容的節點失效後,只要等待該節點恢復後,queue中存在的訊息才可以獲取消費的到。
顯然增加叢集的節點,可以提高整個叢集的吞吐量,但是在高可用方面要稍微差一些
至於為什麼只在一個節點儲存queue?
官方認為,如果之前一個節點的訊息佇列容量是1GB,那現在如果有三個節點,至少要增加2GB;同時rabbitmq的訊息儲存在磁碟上,如果每個訊息在所有的節點活動的話,會大大增加網路和磁碟的負載,降低了叢集的效能。
映象模式
它是在普通模式的基礎上,把需要的佇列做成映象佇列,存在於多個節點來實現高可用(HA)。該模式解決了上述問題,Broker會主動地將訊息實體在各映象節點間同步,在consumer取資料時無需臨時拉取。
該模式帶來的副作用也很明顯,除了降低系統性能外,如果映象佇列數量過多,加之大量的訊息進入,叢集內部的網路頻寬將會被大量消耗。通常地,對可靠性要求較高的場景建議採用映象模式。
在實現機制上,mirror queue內部實現了一套選舉演算法,有一個master和多個slave,queue中的訊息以master為主,
對於publish,可以選擇任意一個節點進行連線,rabbitmq內部若該節點不是master,則轉發給master,master向其他slave節點發送該訊息,後進行訊息本地化處理,並組播複製訊息到其他節點儲存,
對於consumer,可以選擇任意一個節點進行連線,消費的請求會轉發給master,為保證訊息的可靠性,consumer需要進行ack確認,master收到ack後,才會刪除訊息,ack訊息會同步(預設非同步)到其他各個節點,進行slave節點刪除訊息。
若master節點失效,則mirror queue會自動選舉出一個節點(slave中訊息佇列最長者)作為master,作為訊息消費的基準參考;在這種情況下可能存在ack訊息未同步到所有節點的情況(預設非同步),若slave節點失效,mirror queue叢集中其他節點的狀態無需改變。
其他模式
當然還有其他的方式,比如active/passive和shovel,主備方式(active,passive)只有一個節點處於服務狀態,可以結合pacemaker和ARBD,shovel簡單從一個broker的一個佇列中消費訊息,且轉發該訊息到另一個broker的交換機。 這兩種方式用的比較少,這裡就不做介紹了。
RabbitMQ功能測試
本次測試依然是RabbitMQ+springboot,首先需要application.properties
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest這裡的埠是5672,,15672時管理端的埠。
pom要新增依賴:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>Direct模型
Sender的實現:
@Component
public class Sender {
@Autowired
private RabbitTemplate rabbitTemplate;
public void send(String msg) {
this.rabbitTemplate.convertAndSend("tiger", msg);
}
}
Listener和listener2的實現均如下:
@Configuration
@RabbitListener(queues = "tiger")
public class Listener {
private static final Logger LOGGER = LoggerFactory.getLogger(Listener.class);
@Bean
public Queue fooQueue() {
return new Queue("tiger");
}
@RabbitHandler
public void process(@Payload String foo) {
LOGGER.info("Listener: " + foo);
}
}此時多次傳送訊息時,listener和listener2會按順序分別收到訊息。Listener收到的訊息如下:
com.example.rabbitmq.Listener : Listener: this is a test
com.example.rabbitmq.Listener2 : Listener2: this is a test
com.example.rabbitmq.Listener : Listener: this is a test
com.example.rabbitmq.Listener2 : Listener2: this is a test
com.example.rabbitmq.Listener : Listener: this is a test
com.example.rabbitmq.Listener2 : Listener2: this is a test
com.example.rabbitmq.Listener : Listener: this is a test
com.example.rabbitmq.Listener2 : Listener2: this is a testTopic模型
Sender的實現:
@Component
public class SenderTopic {
@Autowired
private RabbitTemplate rabbitTemplate;
/*queue的key,用於和routing key 根據binding模式匹配*/
@Bean(name="message")
public Queue queueMessage() {
return new Queue("topic.message");
}
@Bean(name="messages")
public Queue queueMessages() {
return new Queue("topic.messages");
}
@Bean
public TopicExchange exchange() {
return new TopicExchange("exchange");
}
/*設定binding key,此時所有傳送到這個exchange的訊息,
exchange都會根據routing key將訊息與@Qualifier定義的queue進行匹配*/
@Bean
Binding bindingExchangeMessage(@Qualifier("message") Queue queueMessage, TopicExchange exchange) {
return BindingBuilder.bind(queueMessage).to(exchange).with("topic.message");
}
@Bean
Binding bindingExchangeMessages(@Qualifier("messages") Queue queueMessages, TopicExchange exchange) {
return BindingBuilder.bind(queueMessages).to(exchange).with("topic.#");//*表示一個詞,#表示零個或多個詞
}
public void send(String routingKey, String msg) {
this.rabbitTemplate.convertAndSend("exchange",routingKey, msg);
}
}Listener的實現如下:
@Configuration
@RabbitListener(queues = "topic.message")//監聽器監聽指定的Queue
public class ListenerTopic {
private static final Logger LOGGER = LoggerFactory.getLogger(ListenerTopic.class);
@RabbitHandler
public void process(@Payload String foo) {
LOGGER.info("Listener: " + foo);
}
}listener2的實現如下
@Configuration
@RabbitListener(queues = "topic.messages")
public class ListenerTopic2 {
private static final Logger LOGGER = LoggerFactory.getLogger(ListenerTopic2.class);
@RabbitHandler
public void process(@Payload String foo) {
LOGGER.info("Listener2: " + foo);
}
}傳送topic.message會匹配到topic.#和topic.message 兩個Receiver都可以收到訊息,傳送topic.messages(或者top、topic等)只有topic.#可以匹配所有隻有Receiver2監聽到訊息。
Fanout模型
@Configuration
public class SenderFanout {
@Autowired
private RabbitTemplate rabbitTemplate;
/*queue的key,用於和routing key 根據binding模式匹配*/
@Bean(name="Amessage")
public Queue AMessage() {
return new Queue("fanout.A");
}
@Bean(name="Bmessage")
public Queue BMessage() {
return new Queue("fanout.B");
}
@Bean
FanoutExchange fanoutExchange() {
return new FanoutExchange("fanoutExchange");//配置廣播路由器
}
@Bean
Binding bindingExchangeA(@Qualifier("Amessage") Queue AMessage,FanoutExchange fanoutExchange) {
return BindingBuilder.bind(AMessage).to(fanoutExchange);
}
@Bean
Binding bindingExchangeB(@Qualifier("Bmessage") Queue BMessage, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(BMessage).to(fanoutExchange);
}
public void send(String msg) {
this.rabbitTemplate.convertAndSend("fanoutExchange","", msg);
}
}
@Configuration
@RabbitListener(queues = "fanout.A")//監聽器監聽指定的Queue
public class ListenerFanout {
private static final Logger LOGGER = LoggerFactory.getLogger(ListenerFanout.class);
@RabbitHandler
public void process(@Payload String foo) {
LOGGER.info("Listener: " + foo);
}
}Fanout模式下,所有繫結fanout交換機的佇列,都能收到訊息。
Kafka
Kafka簡介
Kafka是一種分散式的,基於釋出/訂閱的訊息系統。主要設計目標如下:
- 以時間複雜度為O(1)的方式提供訊息持久化能力,即使對TB級以上資料也能保證常數時間複雜度的訪問效能。
- 高吞吐率。即使在非常廉價的商用機器上也能做到單機支援每秒100K條以上訊息的傳輸。
- 支援Kafka Server間的訊息分割槽,及分散式消費,同時保證每個Partition內的訊息順序傳輸。
- 同時支援離線資料處理和實時資料處理。
- Scale out:支援線上水平擴充套件。
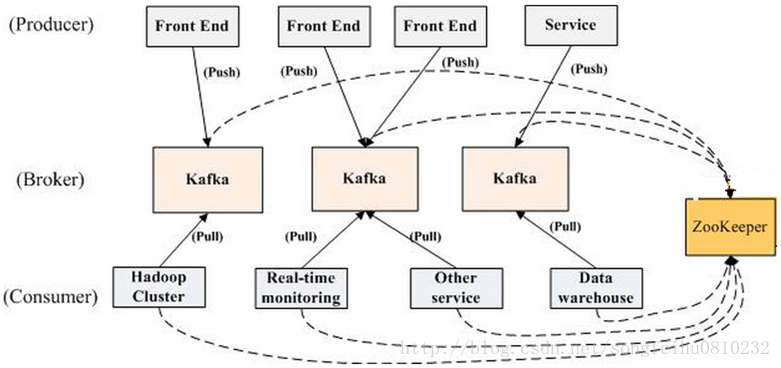
如上圖所示,一個典型的Kafka叢集中包含若干Producer(可以是web前端產生的Page View,或者是伺服器日誌,系統CPU、Memory等),若干broker(Kafka支援水平擴充套件,一般broker數量越多,叢集吞吐率越高),若干Consumer Group,以及一個Zookeeper叢集。Kafka通過Zookeeper管理叢集配置,選舉leader,以及在Consumer Group發生變化時進行rebalance。Producer使用push模式將訊息釋出到broker,Consumer使用pull模式從broker訂閱並消費訊息。
Kafka代理
與其它訊息系統不同,Kafka代理是無狀態的。這意味著消費者必須維護已消費的狀態資訊。這些資訊由消費者自己維護,代理完全不管。這種設計非常微妙,它本身包含了創新。
- 從代理刪除訊息變得很棘手,因為代理並不知道消費者是否已經使用了該訊息。Kafka創新性地解決了這個問題,它將一個簡單的基於時間的SLA應用於保留策略。當訊息在代理中超過一定時間後,將會被自動刪除。
- 這種創新設計有很大的好處,消費者可以故意倒回到老的偏移量再次消費資料。這違反了佇列的常見約定,但被證明是許多消費者的基本特徵。
MQ效能對比及選型
MQ效能對比

從社群活躍度
按照目前網路上的資料,RabbitMQ 、activeM 、ZeroMQ 三者中,綜合來看,RabbitMQ 是首選。
持久化訊息比較
ZeroMq 不支援,ActiveMq 和RabbitMq 都支援。持久化訊息主要是指我們機器在不可抗力因素等情況下宕機了,訊息不會丟失的機制。
綜合技術實現
可靠性、靈活的路由、叢集、事務、高可用的佇列、訊息排序、問題追蹤、視覺化管理工具、外掛系統等等。
RabbitMq / Kafka 最好,ActiveMq 次之,ZeroMq 最差。當然ZeroMq 也可以做到,不過自己必須手動寫程式碼實現,程式碼量不小。尤其是可靠性中的:永續性、投遞確認、釋出者證實和高可用性。
高併發
毋庸置疑,RabbitMQ 最高,原因是它的實現語言是天生具備高併發高可用的erlang 語言。
比較關注的比較, RabbitMQ 和 Kafka
RabbitMq 比Kafka 成熟,在可用性上,穩定性上,可靠性上, RabbitMq 勝於 Kafka (理論上)。RabbitMQ使用ProtoBuf序列化訊息。極大的方便了Consumer的資料高效處理,與XML相比,ProtoBuf有以下優勢:
1.簡單
2.size小了3-10倍
3.速度快了20-100倍
4.易於程式設計
5.減少了語義的歧義.
ProtoBuf具有速度和空間的優勢,使得它現在應用非常廣泛。
另外,Kafka 的定位主要在日誌等方面, 因為Kafka 設計的初衷就是處理日誌的,可以看做是一個日誌(訊息)系統一個重要元件,針對性很強,所以 如果業務方面還是建議選擇 RabbitMq 。
還有就是,Kafka 的效能(吞吐量、TPS )比RabbitMq 要高出來很多。
選型最後總結:
如果我們系統中已經有選擇 Kafka,或者 RabbitMq,並且完全可以滿足現在的業務,建議就不用重複去增加和造輪子。
可以在 Kafka 和 RabbitMq 中選擇一個適合自己團隊和業務的,這個才是最重要的。但是毋庸置疑現階段,綜合考慮沒有第三選擇。