
spark原始碼分析之ShuffleExternalSorter
概述
ShuffleExternalSorter是專門用於sort-based shuffle的external sorter。
傳入的record會被追加到data page。當所有的record都已經插入該sorter時,或者當前執行緒的shuffle memory已經到達閾值時,會使用ShuffleInMemorySorter來根據record的partition id將record排序。排序後的record然後會被寫入一個輸出檔案(或者多個檔案,如果我們已經spill),輸出檔案的格式,與最終SortShuffleSorter寫入的輸出檔案的格式是一致的。SortShuffleSorter會將每個輸出partition的record寫入一個序列化的、壓縮的流,可以通過一個解壓縮的、反序列化的流讀取。
與org.apache.spark.util.collection.ExternalSorter不同,這個sorter不會合並spill file。相反,合併操作交給了UnsafeShuffleWriter執行,UnsafeShuffleWriter會使用專門的合併方法來避免額外的序列化和反序列化。
原始碼分析
成員變數
ShuffleExternalSorter有以下幾個比較重要的成員變數:
- allocatedPages是用來儲存待排序的record的page(MemoryBlock)連結串列。當發生spill後,連結串列中page就會被釋放;
- spills是將排序後的record寫入磁碟檔案作為spill file後,這些spill file的元資料資訊。
- inMemSorter是用來根據record的partition id將record排序的ShuffleInMemorySorter。
- currentPage,page連結串列中用於儲存待排序的record的當前page。一個page會儲存多個record,record通過追加的方式新增到page。
- pageCursor,record追加到當前page時,當前page的可用空間的起始地址(或下標)。
/** * Memory pages that hold the records being sorted. The pages in this list are freed when * spilling, although in principle we could recycle these pages across spills (on the other hand, * this might not be necessary if we maintained a pool of re-usable pages in the TaskMemoryManager * itself). */ //用page連結串列儲存待排序的record。當發生spill時,連結串列中的page會被釋放,雖然原則上我們可以在整個spill期間 //迴圈利用這些page(另一方面,這可能是不必要的如果我們在TaskMemoryManager中儲存了一個可重複使用的page pool) private final LinkedList<MemoryBlock> allocatedPages = new LinkedList<>(); private final LinkedList<SpillInfo> spills = new LinkedList<>(); // These variables are reset after spilling: //spill之後會重置這些變數 @Nullable private ShuffleInMemorySorter inMemSorter; @Nullable private MemoryBlock currentPage = null; private long pageCursor = -1;
其中,inMemsorter的初始化如下:
它會從sparkConf中獲取配置資訊判斷是否使用RadixSort對record進行排序,預設為true。
this.inMemSorter = new ShuffleInMemorySorter(
this, initialSize, conf.getBoolean("spark.shuffle.sort.useRadixSort", true));insertRecord方法
插入一條record到shuffle external sorter。即追加一條record到當前page。record在當前page中的儲存格式為:
record length | (k, v)
同時它也會插入一條record到ShuffleInMemorySorter,在inMemorySorter中儲存record的編碼地址和partitionId。record在inMemorySorter的儲存格式為:
partitionId | pageNumber | offset in page
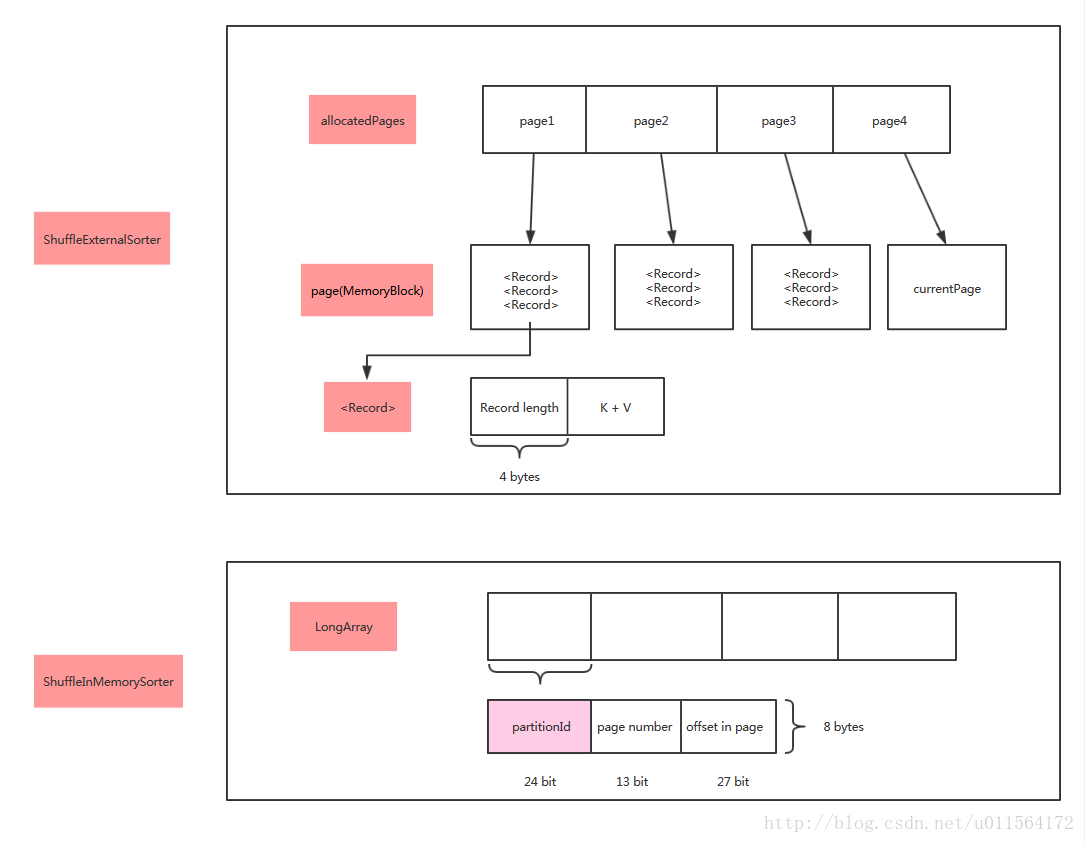
| ShuffleExternalSorter | 使用MemoryBlock儲存資料,每條記錄包括長度資訊和K-V Pair |
| ShuffleInMemorySorter | 使用long陣列儲存每條記錄對應的位置資訊(page number + offset),以及其對應的PartitionId,共8 bytes |
/**
* Write a record to the shuffle sorter.
*/
/*
@param recordBase 儲存一個record的(k, v)鍵值對的位元組陣列
@param recordOffset 位元組陣列型別中第一個元素相對陣列的偏移
@param length 該位元組陣列的大小
@partitionId 該record對應的partitionId
*/
public void insertRecord(Object recordBase, long recordOffset, int length, int partitionId)
throws IOException {
// for tests
assert(inMemSorter != null);
if (inMemSorter.numRecords() >= numElementsForSpillThreshold) {
logger.info("Spilling data because number of spilledRecords crossed the threshold " +
numElementsForSpillThreshold);
spill();
}
growPointerArrayIfNecessary();
// Need 4 bytes to store the record length.
final int required = length + 4;
//判斷是否需要分配新的page,如果當前page的剩餘可用空間大於required個位元組,則不需要
acquireNewPageIfNecessary(required);
assert(currentPage != null);
final Object base = currentPage.getBaseObject();
//將record所在的當前page和在其page中的相對偏移,組裝成編碼地址
final long recordAddress = taskMemoryManager.encodePageNumberAndOffset(currentPage, pageCursor);
//在當前page中儲存record的長度
Platform.putInt(base, pageCursor, length);
//record的長度為int型別,所以pageCursor加4
pageCursor += 4;
//在當前page中儲存record的(k,v)鍵值對
Platform.copyMemory(recordBase, recordOffset, base, pageCursor, length);
pageCursor += length;
//插入一條record到inMemSorter,在inMemSorter儲存record的編碼地址和partitionId
inMemSorter.insertRecord(recordAddress, partitionId);
}closeAndGetSpills方法
將record進行排序並寫入到磁碟檔案中。完成後釋放相關記憶體。
/**
* Close the sorter, causing any buffered data to be sorted and written out to disk.
*
* @return metadata for the spill files written by this sorter. If no records were ever inserted
* into this sorter, then this will return an empty array.
* @throws IOException
*/
public SpillInfo[] closeAndGetSpills() throws IOException {
if (inMemSorter != null) {
// Do not count the final file towards the spill count.
writeSortedFile(true);
freeMemory();
inMemSorter.free();
inMemSorter = null;
}
return spills.toArray(new SpillInfo[spills.size()]);
}writeSortedFile方法
將記憶體中的record進行排序,然後將排序後的record寫入一個磁碟檔案。
該方法實現如下:
1、呼叫inMemsorter的getSortedIterator方法對record進行排序,返回排序完成後的record pointer的迭代器。以使用RadixSort為例,內部會呼叫RadixSort.sort方法執行真實的排序。
2、建立一個spill file檔案,以及建立一個SpillInfo用以儲存該spill file的元資料資訊。
3、建立一個DiskBlockObjectWriter用於寫該spill file。
4、record pointer迭代器迭代record pointer,對record pointer進行解碼,然後將record寫入spill file:
- 呼叫TaskMemoryManager#getPage方法將record的編碼地址——recordPointer解碼為record的所在page的baseObject。如果是堆內記憶體分配,返回值是long array的引用;如果是堆外記憶體分配,返回值為null。
- 呼叫TaskMemoryManager#getOffsetInPage方法將record的編碼地址——recordPointer解碼為record相對所在page的偏移。該偏移是unsafe雙註冊定址模式下的offset,如果是堆內記憶體分配,返回值是long array陣列型別中元素相對陣列的偏移;如果是堆外記憶體分配,返回值是記憶體塊的絕對地址。
- 呼叫platform的getInt方法,其底層呼叫unsafe.getInt(Object o, long offset)方法,從給定物件的給定offset處獲取一個int型別欄位值(int型別確定了要獲取的位元組數為4)。前面說過,record在插入page時首先儲存的是record length, 所以這裡返回record的長度。
- 獲取record的(k, v)鍵值對相對於所在page的偏移。
- 將record的(k, v)鍵值對儲存到writeBuffer。
- 將writeBuffer寫入到spill file
5、將writer關閉,將本次spill file的元資料資訊-spillInfo新增到spills。
/**
* Sorts the in-memory records and writes the sorted records to an on-disk file.
* This method does not free the sort data structures.
*
* @param isLastFile if true, this indicates that we're writing the final output file and that the
* bytes written should be counted towards shuffle spill metrics rather than
* shuffle write metrics.
*/
private void writeSortedFile(boolean isLastFile) {
final ShuffleWriteMetrics writeMetricsToUse;
if (isLastFile) {
// We're writing the final non-spill file, so we _do_ want to count this as shuffle bytes.
writeMetricsToUse = writeMetrics;
} else {
// We're spilling, so bytes written should be counted towards spill rather than write.
// Create a dummy WriteMetrics object to absorb these metrics, since we don't want to count
// them towards shuffle bytes written.
writeMetricsToUse = new ShuffleWriteMetrics();
}
// This call performs the actual sort.
//該呼叫對record進行排序,返回排序好的record的pointer的迭代器
//以使用RadixSort為例,內部會呼叫RadixSort.sort方法執行真實的排序
final ShuffleInMemorySorter.ShuffleSorterIterator sortedRecords =
inMemSorter.getSortedIterator();
// Small writes to DiskBlockObjectWriter will be fairly inefficient. Since there doesn't seem to
// be an API to directly transfer bytes from managed memory to the disk writer, we buffer
// data through a byte array. This array does not need to be large enough to hold a single
// record;
//對DiskBlockObjectWriter執行很小的寫操作是相當低效率的,既然沒有API可以直接將位元組從記憶體轉移到disk Writer,
//那我們可以通過一個byte array來作為資料緩衝區。這個byte array不需要大到足以容納一個record
final byte[] writeBuffer = new byte[diskWriteBufferSize];
// Because this output will be read during shuffle, its compression codec must be controlled by
// spark.shuffle.compress instead of spark.shuffle.spill.compress, so we need to use
// createTempShuffleBlock here; see SPARK-3426 for more details.
final Tuple2<TempShuffleBlockId, File> spilledFileInfo =
blockManager.diskBlockManager().createTempShuffleBlock();
//建立一個臨時的spill file檔案
final File file = spilledFileInfo._2();
final TempShuffleBlockId blockId = spilledFileInfo._1();
//建立該spill file的元資料資訊
final SpillInfo spillInfo = new SpillInfo(numPartitions, file, blockId);
// Unfortunately, we need a serializer instance in order to construct a DiskBlockObjectWriter.
// Our write path doesn't actually use this serializer (since we end up calling the `write()`
// OutputStream methods), but DiskBlockObjectWriter still calls some methods on it. To work
// around this, we pass a dummy no-op serializer.
final SerializerInstance ser = DummySerializerInstance.INSTANCE;
//建立一個DiskBlockObjectWriter用於寫該spill file
final DiskBlockObjectWriter writer =
blockManager.getDiskWriter(blockId, file, ser, fileBufferSizeBytes, writeMetricsToUse);
int currentPartition = -1;
//排序後的record pointer迭代器迭代record
while (sortedRecords.hasNext()) {
sortedRecords.loadNext();
final int partition = sortedRecords.packedRecordPointer.getPartitionId();
assert (partition >= currentPartition);
if (partition != currentPartition) {
// Switch to the new partition
if (currentPartition != -1) {
final FileSegment fileSegment = writer.commitAndGet();
spillInfo.partitionLengths[currentPartition] = fileSegment.length();
}
currentPartition = partition;
}
//獲取本次迭代的record pointer
final long recordPointer = sortedRecords.packedRecordPointer.getRecordPointer();
//將record的編碼地址解碼為record的所在page的baseObject
final Object recordPage = taskMemoryManager.getPage(recordPointer);
//將record的編碼地址解碼為record相對於所在page的偏移
final long recordOffsetInPage = taskMemoryManager.getOffsetInPage(recordPointer);
//底層呼叫unsafe.getInt(Object o, long offset)方法,從給定物件的給定offset處獲取一個欄位值
//前面說過,record在插入page時首先儲存的是record length, 所以這裡返回record的長度。
int dataRemaining = Platform.getInt(recordPage, recordOffsetInPage);
//獲取record的(k, v)鍵值對相對於所在page的偏移
long recordReadPosition = recordOffsetInPage + 4; // skip over record length
while (dataRemaining > 0) {
final int toTransfer = Math.min(diskWriteBufferSize, dataRemaining);
//將record的(k, v)鍵值對儲存到writeBuffer
Platform.copyMemory(
recordPage, recordReadPosition, writeBuffer, Platform.BYTE_ARRAY_OFFSET, toTransfer);
//將writeBuffer寫入到spill file
writer.write(writeBuffer, 0, toTransfer);
recordReadPosition += toTransfer;
dataRemaining -= toTransfer;
}
writer.recordWritten();
}
final FileSegment committedSegment = writer.commitAndGet();
writer.close();
// If `writeSortedFile()` was called from `closeAndGetSpills()` and no records were inserted,
// then the file might be empty. Note that it might be better to avoid calling
// writeSortedFile() in that case.
if (currentPartition != -1) {
spillInfo.partitionLengths[currentPartition] = committedSegment.length();
spills.add(spillInfo);
}
if (!isLastFile) { // i.e. this is a spill file
// The current semantics of `shuffleRecordsWritten` seem to be that it's updated when records
// are written to disk, not when they enter the shuffle sorting code. DiskBlockObjectWriter
// relies on its `recordWritten()` method being called in order to trigger periodic updates to
// `shuffleBytesWritten`. If we were to remove the `recordWritten()` call and increment that
// counter at a higher-level, then the in-progress metrics for records written and bytes
// written would get out of sync.
//
// When writing the last file, we pass `writeMetrics` directly to the DiskBlockObjectWriter;
// in all other cases, we pass in a dummy write metrics to capture metrics, then copy those
// metrics to the true write metrics here. The reason for performing this copying is so that
// we can avoid reporting spilled bytes as shuffle write bytes.
//
// Note that we intentionally ignore the value of `writeMetricsToUse.shuffleWriteTime()`.
// Consistent with ExternalSorter, we do not count this IO towards shuffle write time.
// This means that this IO time is not accounted for anywhere; SPARK-3577 will fix this.
writeMetrics.incRecordsWritten(writeMetricsToUse.recordsWritten());
taskContext.taskMetrics().incDiskBytesSpilled(writeMetricsToUse.bytesWritten());
}
}freeMemory方法
釋放用來儲存待排序的record的page連結串列——allocatedPages;
重置currentPage、pageCursor這些狀態變數;
private long freeMemory() {
updatePeakMemoryUsed();
long memoryFreed = 0;
for (MemoryBlock block : allocatedPages) {
memoryFreed += block.size();
freePage(block);
}
allocatedPages.clear();
currentPage = null;
pageCursor = 0;
return memoryFreed;
}