
使用IDEA進行Spark開發(二)-第一個scala程式
阿新 • • 發佈:2018-12-25
上面一篇文章博主已經給大家演示好了如何去配置一個本機的scala開發環境,現在我們就一起去寫我們的第一個spark開發的scala程式吧!
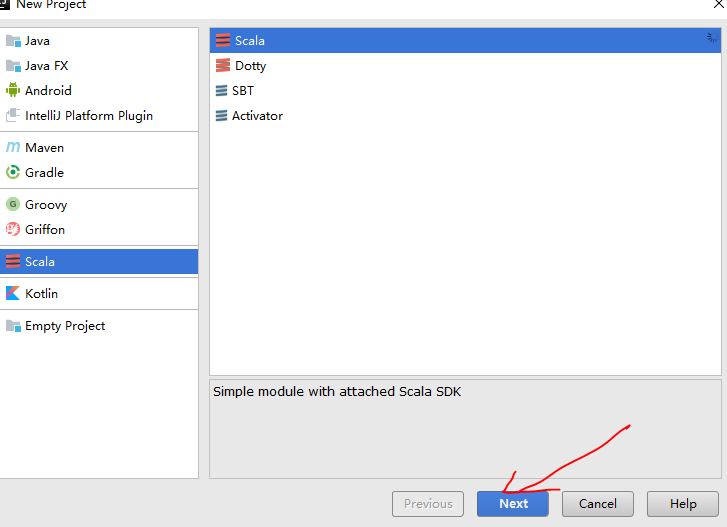
- 開啟IDEA,選擇建立一個新的工程檔案。
- 點選scala,建立一個scala工程
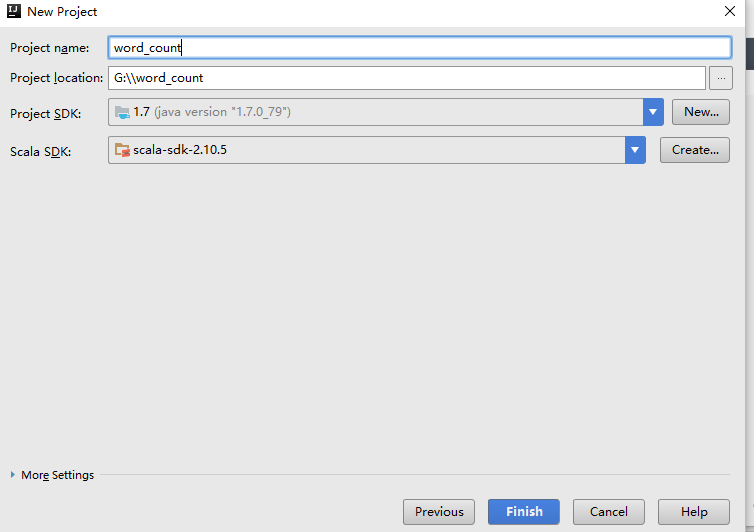
- 輸入我們程式名稱——word_count,我們要寫一個詞頻統計程式。
JDK選擇1.7
scala選擇我們下載安裝好的scala環境目錄,這裡是2.10.5
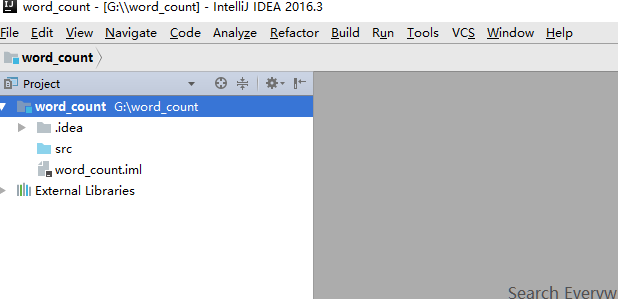
點選完成,即可進入程式介面
- 匯入scala與spark配置
新建兩個包,main與count
便於整理自己的程式碼結構 - 匯入scala包與spark包
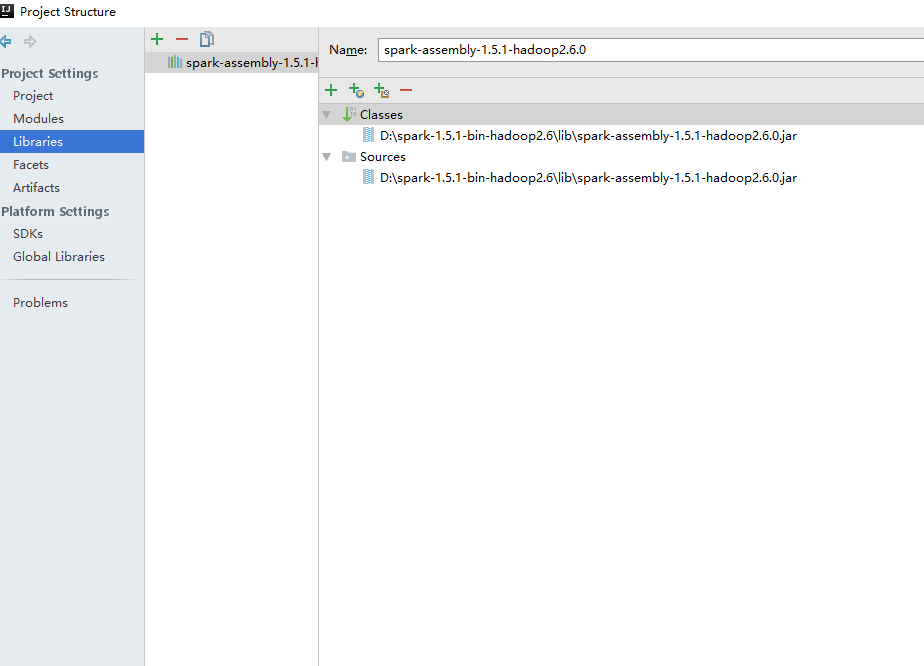
右鍵進入Module setting介面或直接按快捷鍵F4
進入librarys
點選JAVA,然後找到spark路徑spark-1.5.1-bin-hadoop2.6\lib\spark-assembly-1.5.1-hadoop2.6.0.jar
匯入jar包。
然後進入global library
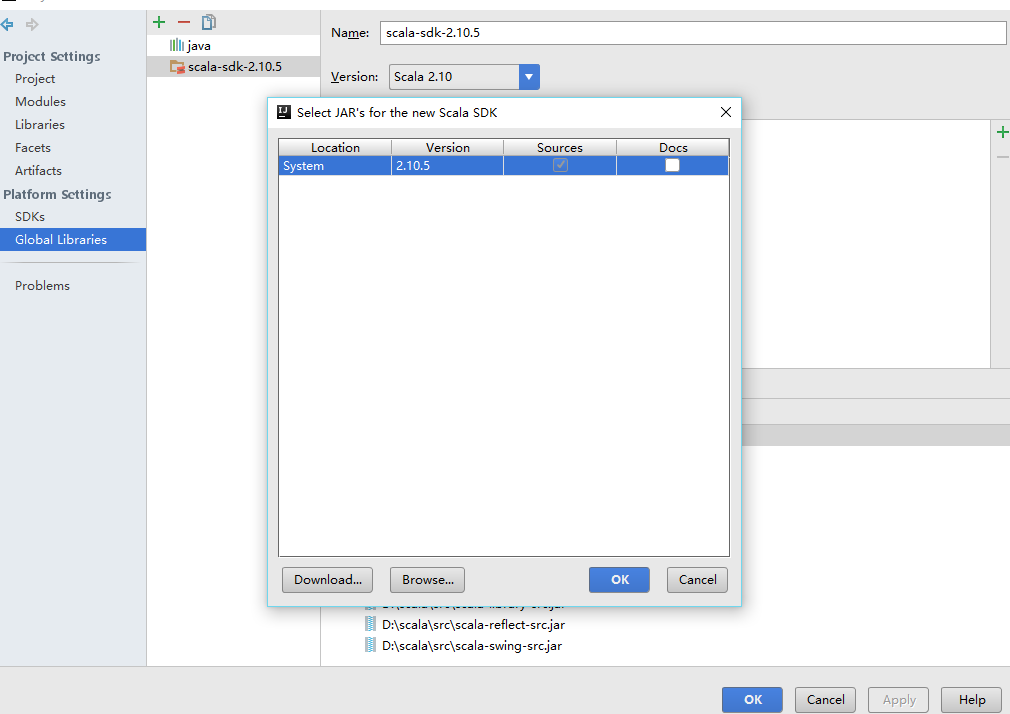
點選scala,匯入scala 2.10.5.
- 新建scala檔案,編寫scala程式
- 編寫詞頻統計程式
程式如下:

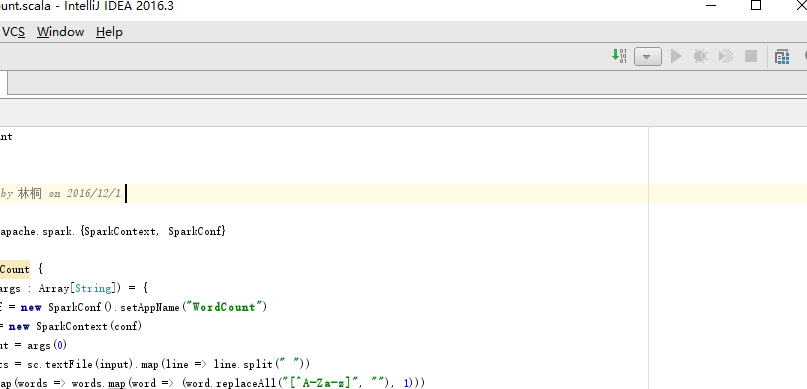
package com.exercise
import org.apache.spark.{SparkContext, SparkConf}
/**
1. Created by flet on 2016/7/7.
*/
object WordCount 8.執行scala程式
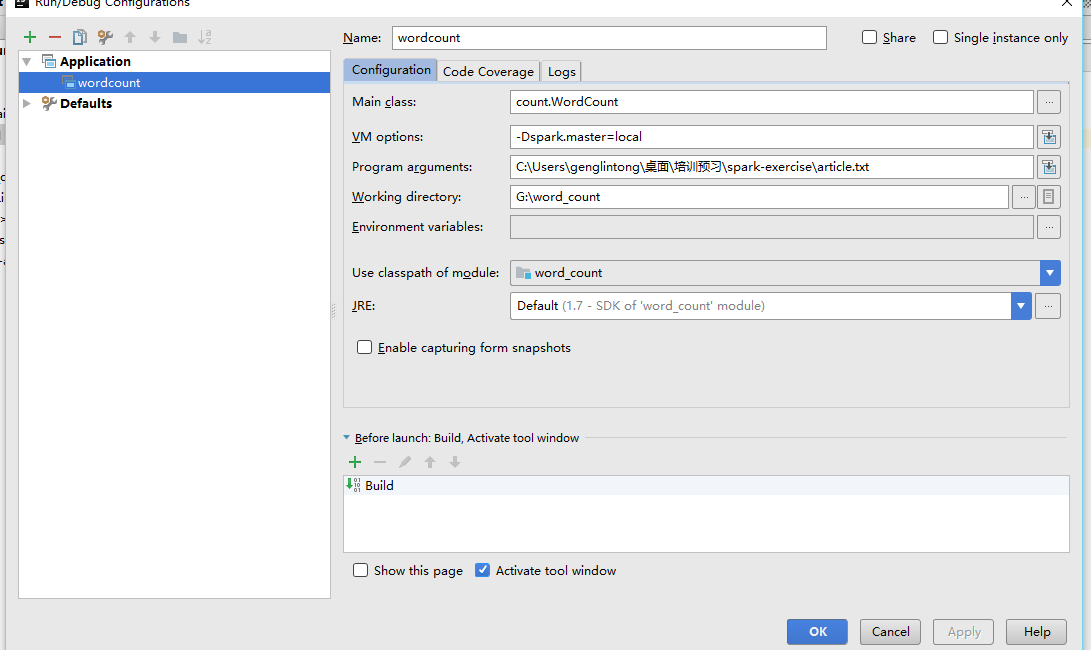
指定檔案路徑
點選右上角,設定路徑
按上面的加號,新增application
填寫如下
9.檢視結果
點選執行wordcount
等待一會就會看到控制檯輸出一些流資訊與結果。
如下圖:
到這裡,我們的第一個spark開發的scala程式就結束了,我們成功的統計了一篇文章的詞頻,並且輸出在控制檯裡。
大家有沒有感覺到大資料的神奇之處呢?
如果大家有什麼問題可以和博主討論,其實博主也是剛剛接觸這一方面。
文章的最好放一張原始資料的圖片。
