
白話經典算法系列之五 歸併排序的實現(講的真好)
歸併排序是建立在歸併操作上的一種有效的排序演算法。該演算法是採用分治法(Divide and Conquer)的一個非常典型的應用。
首先考慮下如何將將二個有序數列合併。這個非常簡單,只要從比較二個數列的第一個數,誰小就先取誰,取了後就在對應數列中刪除這個數。然後再進行比較,如果有數列為空,那直接將另一個數列的資料依次取出即可。
- //將有序陣列a[]和b[]合併到c[]中
- void MemeryArray(int a[], int n, int b[], int m, int c[])
- {
- int i, j, k;
- i = j = k = 0;
-
while(i < n && j < m)
- {
- if (a[i] < b[j])
- c[k++] = a[i++];
- else
- c[k++] = b[j++];
- }
- while (i < n)
- c[k++] = a[i++];
- while (j < m)
- c[k++] = b[j++];
- }
可以看出合併有序數列的效率是比較高的,可以達到O(n)。
解決了上面的合併有序數列問題,再來看歸併排序,其的基本思路就是將陣列分成二組A,B,如果這二組組內的資料都是有序的,那麼就可以很方便的將這二組資料進行排序。如何讓這二組組內資料有序了?
可以將A,B組各自再分成二組。依次類推,當分出來的小組只有一個數據時,可以認為這個小組組內已經達到了有序,然後再合併相鄰的二個小組就可以了。這樣通過先遞歸的分解數列,再合並數列就完成了歸併排序。
- //將有二個有序數列a[first...mid]和a[mid...last]合併。
- void mergearray(int a[], int first, int mid, int last, int temp[])
- {
- int i = first, j = mid + 1;
- int m = mid, n = last;
- int k = 0;
-
while(i <= m && j <= n)
- {
- if (a[i] <= a[j])
- temp[k++] = a[i++];
- else
- temp[k++] = a[j++];
- }
- while (i <= m)
- temp[k++] = a[i++];
- while (j <= n)
- temp[k++] = a[j++];
- for (i = 0; i < k; i++)
- a[first + i] = temp[i];
- }
- void mergesort(int a[], int first, int last, int temp[])
- {
- if (first < last)
- {
- int mid = (first + last) / 2;
- mergesort(a, first, mid, temp); //左邊有序
- mergesort(a, mid + 1, last, temp); //右邊有序
- mergearray(a, first, mid, last, temp); //再將二個有序數列合併
- }
- }
- bool MergeSort(int a[], int n)
- {
- int *p = newint[n];
- if (p == NULL)
- returnfalse;
- mergesort(a, 0, n - 1, p);
- delete[] p;
- returntrue;
- }
歸併排序的效率是比較高的,設數列長為N,將數列分開成小數列一共要logN步,每步都是一個合併有序數列的過程,時間複雜度可以記為O(N),故一共為O(N*logN)。因為歸併排序每次都是在相鄰的資料中進行操作,所以歸併排序在O(N*logN)的幾種排序方法(快速排序,歸併排序,希爾排序,堆排序)也是效率比較高的。
在本人電腦上對氣泡排序,直接插入排序,歸併排序及直接使用系統的qsort()進行比較(均在Release版本下)
對20000個隨機資料進行測試:
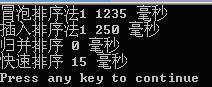
對50000個隨機資料進行測試:
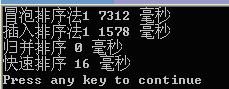
再對200000個隨機資料進行測試:
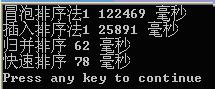
注:有的書上是在mergearray()合併有序數列時分配臨時陣列,但是過多的new操作會非常費時。因此作了下小小的變化。只在MergeSort()中new一個臨時陣列。後面的操作都共用這一個臨時陣列