Flink之二 Flink安裝及入門案例
Flink 安裝(叢集模式):
1:下載安裝flink的安裝包,注意hadoop的版本相容問題

2:解壓安裝包,進入conf配置檔案目錄下,主要配置檔案為flink-conf.yaml和slaves,配置flink-conf.yaml解析如下:
2.1 基本配置
jobmanager.rpc.address: localhost1 --jobManager 的IP地址
jobmanager.rpc.port: 6123 --jobManager 的埠,預設為6123
jobmanager.heap.mb --jobManager 的JVM heap大小
taskmanager.heap.mb --taskManager的jvm heap大小設定
taskmanager.numberOfTaskSlots --taskManager中taskSlots個數,最好設定成work節點的CPU個數相等
parallelism.default --平行計算數
fs.default-scheme --檔案系統來源
fs.hdfs.hadoopconf: --hdfs置檔案路徑
jobmanager.web.port -- jobmanager的頁面監控埠
2.2 記憶體管理配置
Flink預設上分配taskmanager.heap.mb配置值得70%留它管理,記憶體的管理讓flinK批量處理效果很高;並且flink不會出現OutMemoryException的問題,因為flink知道預留多少記憶體來執行程式;如果flink執行的程式所需要的記憶體超過了它所管理的記憶體,Flink就可以利用磁碟;總而言之,flink的記憶體管理提高了魯棒性和系統的速度;下面就介紹管理記憶體的配置檔案:
taskmanager.memory.fraction --管理記憶體的百分比,預設0.7
taskmanager.memory.size --taskManager 具體管理記憶體的大小;此配置重寫taskmanager.memory.fraction的配置
taskmanager.memory.segment-size --記憶體管理器所使用的記憶體緩衝區的大小和網路堆疊位元組
taskmanager.memory.preallocate --taskmanager是否啟動時管理所有的記憶體
2.3 slaves 中配置節點機器的ip或主機名
3:啟動flink

4:進入web監控頁面
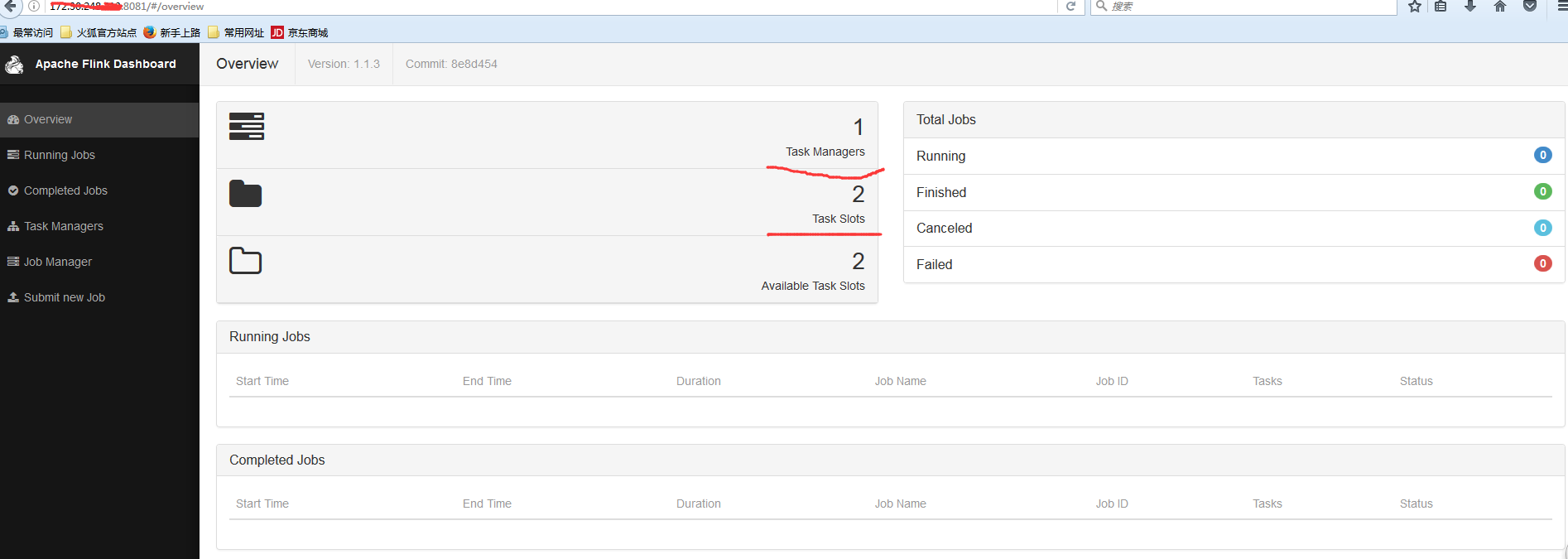
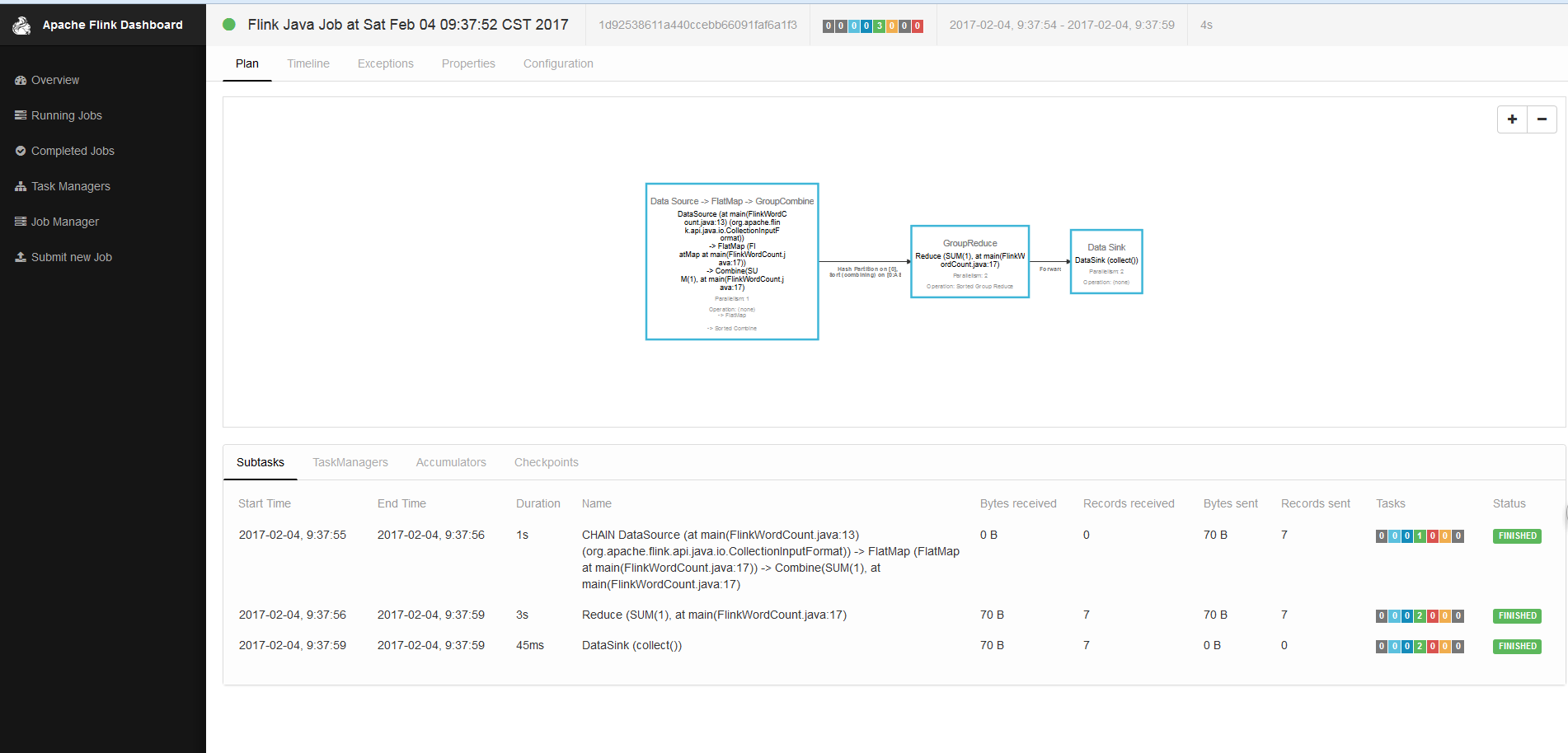
若見到上圖頁面,就說明flink配置成功了,下面就以wordcount為案例執行,案例程式碼如下:
public class FlinkWordCount {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"hadoop hive?",
"think hadoop hive sqoop hbase spark flink?");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split("\\W+")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
以上程式碼進行打包上傳;上傳後執行提交命令:
列印結果如下:

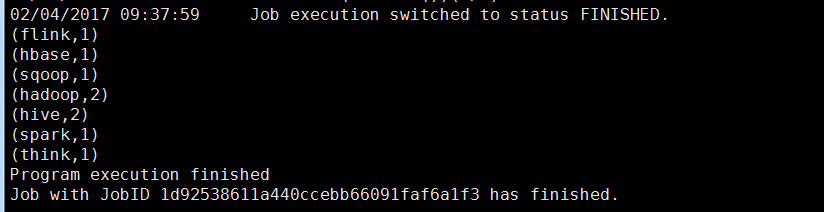
web頁面監控