
生信(七)生信中常用命令
今天將生信工作中的一些常用命令記錄(分享)如下: (以後會不定期更新)
轉換dos/windows格式的bed檔案為unix格式
(說明:我們拿到的bed檔案時常是客戶在Windows系統下編輯好的,其行尾是\r\n,在進行NGS分析前最好將其轉換為Unix風格的行尾\n。)
 可以看出上面的dos.bed.txt是一個dos風格(^MKaTeX parse error: Can't use function '\r' in math mode at position 3: ,即\̲r̲\n結尾)的檔案。要想轉換成u…,即\n結尾)的檔案,當然可以用dos2unix命令來完成:
可以看出上面的dos.bed.txt是一個dos風格(^MKaTeX parse error: Can't use function '\r' in math mode at position 3: ,即\̲r̲\n結尾)的檔案。要想轉換成u…,即\n結尾)的檔案,當然可以用dos2unix命令來完成:
dos2unix –n dos.bed.txt unix.bed.txt
 可以看到轉換成功。問題在於dos2unix命令往往不是系統預設安裝的,你要自行安裝後才可以使用。一個替代的方法是用sed命令。
可以看到轉換成功。問題在於dos2unix命令往往不是系統預設安裝的,你要自行安裝後才可以使用。一個替代的方法是用sed命令。
sed ‘s/\r//’ dos.bed.txt > unix.bed.txt
 可以看到,轉換效果是一樣的。
可以看到,轉換效果是一樣的。
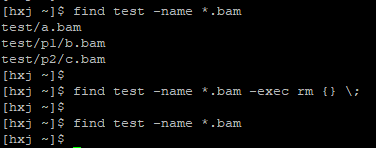
批量刪除一個目錄及其子目錄下的bam檔案
find your_path –name *.bam –exec rm {} \;
合併兩個fastq檔案
cat fastq1 fastq2 > merged_fastq
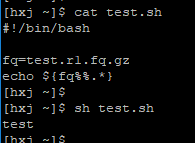
獲取fastq檔名字首 (假設fastq檔名是test.r1.fq.gz,我們想得到其字首test)
your_string | cut –d. –f1
 或者:
或者:
your_string | sed ‘s/\..*//’
 或者:
或者:
your_string | awk –F. ‘{print $1}’
 或者(如果是在指令碼中實現這一功能的話):
利用shell中的字串變數刪除功能 ${var%%} 來實現。
或者(如果是在指令碼中實現這一功能的話):
利用shell中的字串變數刪除功能 ${var%%} 來實現。
打包並壓縮專案檔案
tar zcvf tar_file origin_files
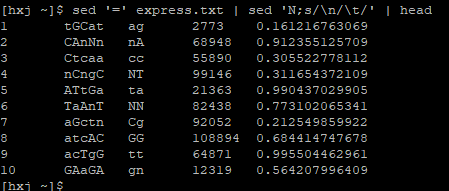
列印行號
sed ‘=’ your_file | sed ‘N;s/\n/\t/’
 或者:
或者:
awk ‘{printf(“%d\t%s\n”, NR, $0)}’ your_file

輸出指定的行數 (比如第666行)
sed –n ‘666p;666d’ your_file
 或者:
或者:
awk ‘NR==666{print $0; exit}’ your_file

統計不重複的基因個數 (假設基因名在第一列)
awk ‘{print $1}’ your_file | sort -u | wc –l
 或者
或者
awk ‘{a[$1]++} END {print length(a)}’ your_file

找出表達量最高的基因 (假設基因名在第一列,表達量資料在第四列)
sort –k4,4nr your_file | head -1 | cut –f1
 或者(如果僅僅是找出最高表達量的基因,下面的方法更快!因為它不對所有記錄排序):
或者(如果僅僅是找出最高表達量的基因,下面的方法更快!因為它不對所有記錄排序):
awk ‘{if(max<$4){max=$4;gene=$1}} END {print gene}’ your_file

列印最後一列
awk ‘{print $NF}’ your_file
反向互補序列 (如”agctn”的反向互補序列應該是”nagct”)
your_string | tr ‘agctnAGCTN’ ‘tcganTCGAN’ | rev

或者:
your_string | sed ‘y/agctnAGCTN/tcganTCGAN/’ | rev

求取某一列平均值 (假設求第四列的平均值)
awk ‘{x+=$4} END {print x/NR}’ your_file
 如果是壓縮檔案,則需利用zcat來生成“流”:
如果是壓縮檔案,則需利用zcat來生成“流”:
zcat your_zipped_file | awk ‘{x+=$4} END {print x/NR}’
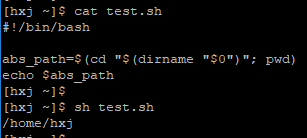
獲取指令碼檔案所在目錄的絕對路徑 (假設你有一個指令碼test.sh,你想在該腳本里寫幾行程式碼獲取test.sh所在目錄的絕對路徑)
abs_path=$(cd “$(dirname “$0”)”; pwd)
echo $abs_path
對bed檔案排序 (假設依次按照前三列進行排序)
sort –k1,1V –k2,2n –k3,3n unsort.bed > sort.bed
最後提一句:從上面的諸多例子中,我們可以看出,sed與awk的威力。它們與grep並稱Linux下的“三劍客”,牛叉哄哄!
如果有任何意見或建議,歡迎留言!
公眾號:生信了
