
嵌入式C語言的位元組對齊理解(圖文)
1.位元組對齊?
對齊跟資料在記憶體中的位置有關。如果一個變數的記憶體地址正好位於系統長度的整數倍,他就被稱做自然對齊。比如在32位cpu下,假設一個整型變數的地址為0x00000004,那它就是自然對齊的。
2. 計算機為什麼要對齊?
需要位元組對齊的根本原因在於CPU訪問資料的效率問題。假設上面整型變數的地址不是自然對齊,比如為0x00000002,則CPU如果取它的值的話需要訪問兩次記憶體,第一次取從0x00000002-0x00000003的一個short,第二次取從0x00000004-0x00000005的一個short然後組合得到所要的資料,如果變數在0x00000003地址上的話則要訪問三次記憶體,第一次為char,第二次為short,第三次為char,然後組合得到整型資料。而如果變數在自然對齊位置上,則只要一次就可以取出資料。
3. 一個對齊的例子
通常,我們寫程式的時候,不需要考慮對齊問題,編譯器會替我們選擇適合目標平臺的對齊策略。當然,我們也可以通知給編譯器傳遞預編譯指令而改變對指定資料的對齊方法,比如寫入預編譯指令#pragma pack(2),即告訴編譯器按兩位元組對齊。
但是,正因為我們一般不需要關心這個問題,所以,如果編輯器對資料存放做了對齊,而我們不瞭解的話,常常會對一些問題感到迷惑。最常見的就是struct資料結構的sizeof結果,比如以下程式:
#include <stdio.h> void main(){ struct A{ char a; short b; int c; }; printf( "size of struct A = %d \n", sizeof(struct A) ); }

輸出結果為:8位元組。
如果我們將結構體中的變數宣告位置稍加改動(並不改變變數本身),請再看以下程式:
#include <stdio.h>
void main(){
struct A{
short b;
int c;
char a;
};
printf( "size of struct A = %d \n", sizeof(struct A) );
}輸出結果為:12位元組。
問題出來了,他們都是同一個結構體,為什麼佔用的記憶體大小不同呢?為此,我們需要對對齊演算法有所瞭解。
4. 對齊演算法
首先,我們給出四個概念:
1)資料型別自身的對齊值:就是基本資料型別的自身對齊值,比如char型別的自身對齊值為1位元組,int型別的自身對齊值為4位元組。

2)指定對齊值:預編譯命令#pragma pack (value)指定的對齊值value。
3)結構體或者類的自身對齊值:其成員中自身對齊值最大的那個值,比如以上的struct A的對齊值為4。
4)資料成員、結構體和類的有效對齊值:自身對齊值和指定對齊值中較小的那個值。
設結構體如下定義:
struct A{
char a;
short b;
int c;
};
a是char型資料,佔用1位元組記憶體;short型資料,佔用2位元組記憶體;int型資料,佔用4位元組記憶體。因此,結構體A的自身對齊值為4。於是,a和b要組成4個位元組,以便與c的4個位元組對齊。而a只有1個位元組,a與b之間便空了一個位元組。我們知道,結構體型別資料是按順序儲存結構一個接一個向後排列的,於是其儲存方式為:
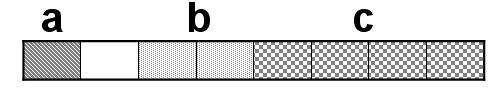
其中空白方格無資料,是浪費的記憶體空間,共佔用8位元組記憶體。
實際上,為了更加明顯地表示“對齊”,我們可以將以上結構想象為以下的行排列:

對於另一個結構體定義:
struct A{
short b;
int c;
char a;
};
其記憶體儲存方式為:

同樣把它想象成行排列:
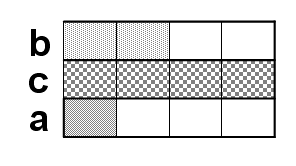
可見,浪費的空間更多。
其實,除了結構體之外,整個程式在給每個變數進行記憶體分配時都會遵循對齊機制,也都會產生記憶體空間的浪費。但我們要知道,這種浪費是值得的,因為它換來的是效率的提高。
以上分析都是建立在程式預設的對齊值基礎之上的,我們可以通過新增預定義命令#pragma pack(value)來對對齊值進行自定義,比如#pragma pack(1),對齊值變為1,此時記憶體緊湊,不會出現記憶體浪費,但效率降低了。效率之所以降低,是因為:如果存在更大位元組數的變數時(比1大),比如int型別,需要進行多次讀週期才能將一個int資料拼湊起來。