
【轉】【Linux 核心】記憶體管理(二)夥伴演算法
通常情況下,一個高階作業系統必須要給程序提供基本的、能夠在任意時刻申請和釋放任意大小記憶體的功能,就像malloc 函式那樣,然而,實現malloc 函式並不簡單,由於程序申請記憶體的大小是任意的,如果作業系統對malloc 函式的實現方法不對,將直接導致一個不可避免的問題,那就是記憶體碎片。
記憶體碎片就是記憶體被分割成很小很小的一些塊,這些塊雖然是空閒的,但是卻小到無法使用。隨著申請和釋放次數的增加,記憶體將變得越來越不連續。最後,整個記憶體將只剩下碎片,即使有足夠的空閒頁框可以滿足請求,但要分配一個大塊的連續頁框就可能無法滿足,所以減少記憶體浪費的核心就是儘量避免產生記憶體碎片
針對這樣的問題,有很多行之有效的解決方法,其中夥伴演算法被證明是非常行之有效的一套記憶體管理方法,因此也被相當多的作業系統所採用。
夥伴演算法,簡而言之,就是將記憶體分成若干塊,然後儘可能以最適合的方式滿足程式記憶體需求的一種記憶體管理演算法,夥伴演算法的一大優勢是它能夠完全避免外部碎片的產生。什麼是外部碎片以及內部碎片,前面博文slab分配器後面已有介紹。申請時,夥伴演算法會給程式分配一個較大的記憶體空間,即保證所有大塊記憶體都能得到滿足。很明顯分配比需求還大的記憶體空間,會產生內部碎片。所以夥伴演算法雖然能夠完全避免外部碎片的產生,但這恰恰是以產生內部碎片為代價的。
Linux 便是採用這著名的夥伴系統演算法來解決外部碎片的問題。把所有的空閒頁框分組為 11 塊連結串列,每一塊連結串列分別包含大小為1,2,4,8,16,32,64,128,256,512 和 1024 個連續的頁框。對1024 個頁框的最大請求對應著 4MB 大小的連續RAM 塊。每一塊的第一個頁框的實體地址是該塊大小的整數倍。例如,大小為 16個頁框的塊,其起始地址是 16 * 2^12 (2^12 = 4096,這是一個常規頁的大小)的倍數。
下面通過一個簡單的例子來說明該演算法的工作原理:
假設要請求一個256(129~256)個頁框的塊。演算法先在256個頁框的連結串列中檢查是否有一個空閒塊。如果沒有這樣的塊,演算法會查詢下一個更大的頁塊,也就是,在512個頁框的連結串列中找一個空閒塊。如果存在這樣的塊,核心就把512的頁框分成兩等分,一般用作滿足需求,另一半則插入到256個頁框的連結串列中。如果在512個頁框的塊連結串列中也沒找到空閒塊,就繼續找更大的塊——1024個頁框的塊。如果這樣的塊存在,核心就把1024個頁框塊的256個頁框用作請求,然後剩餘的768個頁框中拿512個插入到512個頁框的連結串列中,再把最後的256個插入到256個頁框的連結串列中。如果1024個頁框的連結串列還是空的,演算法就放棄併發出錯誤訊號。
簡而言之,就是在分配記憶體時,首先從空閒的記憶體中搜索比申請的記憶體大的最小的記憶體塊。如果這樣的記憶體塊存在,則將這塊記憶體標記為“已用”,同時將該記憶體分配給應用程式。如果這樣的記憶體不存在,則作業系統將尋找更大塊的空閒記憶體,然後將這塊記憶體平分成兩部分,一部分返回給程式使用,另一部分作為空閒的記憶體塊等待下一次被分配。
以上過程的逆過程就是頁框塊的釋放過程,也是該演算法名字的由來。核心試圖把大小為 b 的一對空閒夥伴塊合併為一個大小為 2b 的單獨塊。滿足以下條件的兩個塊稱為夥伴:
兩個快具有相同的大小,記作 b它們的實體地址是連續的 第一塊的第一個頁框的實體地址是 2 * b * 2^12 的倍數 該演算法是迭代的,如果它成功合併所釋放的塊,它會試圖合併 2b 的塊,以再次試圖形成更大的塊。
假設要釋放一個256個頁框的塊,演算法就把其插入到256個頁框的連結串列中,然後檢查與該記憶體相鄰的記憶體,如果存在同樣大小為256個頁框的並且空閒的記憶體,就將這兩塊記憶體合併成512個頁框,然後插入到512個頁框的連結串列中,如果不存在,就沒有後面的合併操作。然後再進一步檢查,如果合併後的512個頁框的記憶體存在大小為512個頁框的相鄰且空閒的記憶體,則將兩者合併,然後插入到1024個頁框的連結串列中。
簡而言之,就是當程式釋放記憶體時,作業系統首先將該記憶體回收,然後檢查與該記憶體相鄰的記憶體是否是同樣大小並且同樣處於空閒的狀態,如果是,則將這兩塊記憶體合併,然後程式遞迴進行同樣的檢查。
下面通過一個例子,來深入地理解一下夥伴演算法的真正內涵(下面這個例子並不嚴格表示Linux 核心中的實現,是闡述夥伴演算法的實現思想):
假設系統中有 1MB 大小的記憶體需要動態管理,按照夥伴演算法的要求:需要將這1M大小的記憶體進行劃分。這裡,我們將這1M的記憶體分為 64K、64K、128K、256K、和512K 共五個部分,如下圖 a 所示
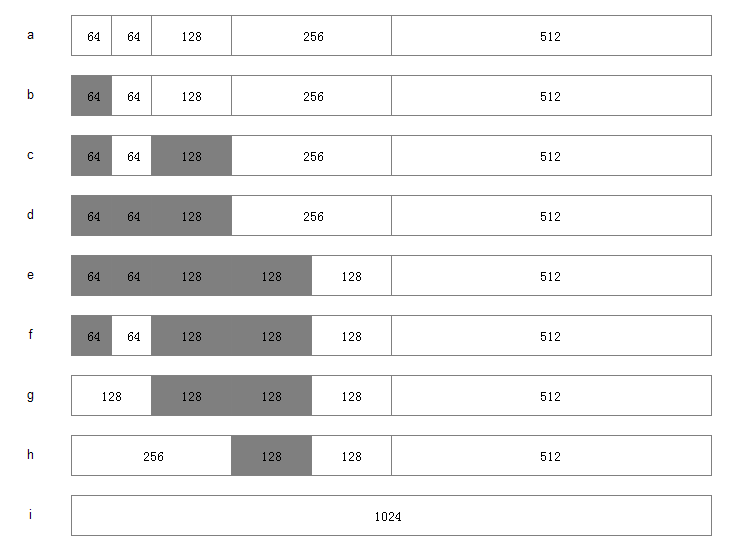
1.此時,如果有一個程式A想要申請一塊45K大小的記憶體,則系統會將第一塊64K的記憶體塊分配給該程式(產生內部碎片為代價),如圖b所示;
2.然後程式B向系統申請一塊68K大小的記憶體,系統會將128K記憶體分配給該程式,如圖c所示;
3.接下來,程式C要申請一塊大小為35K的記憶體。系統將空閒的64K記憶體分配給該程式,如圖d所示;
4.之後程式D需要一塊大小為90K的記憶體。當程式提出申請時,系統本該分配給程式D一塊128K大小的記憶體,但此時記憶體中已經沒有空閒的128K記憶體塊了,於是根據夥伴演算法的原理,系統會將256K大小的記憶體塊平分,將其中一塊分配給程式D,另一塊作為空閒記憶體塊保留,等待以後使用,如圖e所示;
5.緊接著,程式C釋放了它申請的64K記憶體。在記憶體釋放的同時,系統還負責檢查與之相鄰並且同樣大小的記憶體是否也空閒,由於此時程式A並沒有釋放它的記憶體,所以系統只會將程式C的64K記憶體回收,如圖f所示;
6.然後程式A也釋放掉由它申請的64K記憶體,系統隨機發現與之相鄰且大小相同的一段記憶體塊恰好也處於空閒狀態。於是,將兩者合併成128K記憶體,如圖g所示;
7.之後程式B釋放掉它的128k,系統也將這塊記憶體與相鄰的128K記憶體合併成256K的空閒記憶體,如圖h所示;
8.最後程式D也釋放掉它的記憶體,經過三次合併後,系統得到了一塊1024K的完整記憶體,如圖i所示。
有了前面的瞭解,我們通過Linux 核心原始碼(mmzone.h)來看看夥伴演算法是如何實現的:
夥伴演算法管理結構
#define MAX_ORDER 11 struct zone { …… struct free_area free_area[MAX_ORDER]; …… } struct free_area { struct list_head free_list[MIGRATE_TYPES]; unsigned long nr_free;//該組類別塊空閒的個數 }; 前面說到夥伴演算法把所有的空閒頁框分組為11塊連結串列,記憶體分配的最大長度便是2^10頁面。
上面兩個結構體向我們揭示了夥伴演算法管理結構。zone結構中的free_area陣列,大小為11,分別存放著這11個組,free_area結構體裡面又標註了該組別空閒記憶體塊的情況。
將所有空閒頁框分為11個組,然後同等大小的串成一個連結串列對應到free_area陣列中。這樣能很好的管理這些不同大小頁面的塊。
(啊哦,有時間再補充吧...) --------------------- 作者:selfimpr1991 來源:CSDN 原文:https://blog.csdn.net/wenqian1991/article/details/27968779