
基本爬蟲架構實現的豆瓣爬蟲(三): HTML 解析器
阿新 • • 發佈:2018-12-19
一、實現原理
HTML 解析器使用 Xpath 規則進行 HTML 解析,需要解析的部分主要有書名、評分和評分人數。


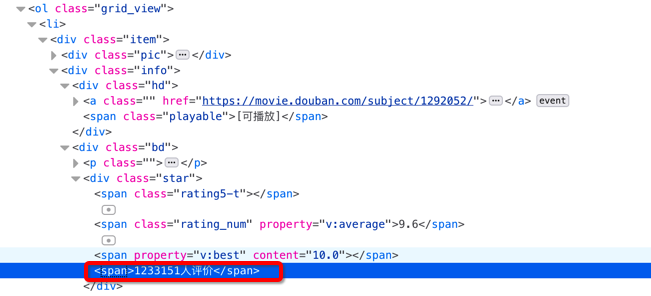
二、程式碼如下
1 from lxml.html import etree 2 import re 3 4 class HtmlParser: 5 def parser(self, page_url, html_text): 6 """ 7 解析頁面新的 url 連結和資料 8 :param page_url: url 9 :param html_text: 頁面內容10 :return: tuple / None 11 """ 12 if not page_url and not html_text: 13 return None 14 new_urls = self._get_new_urls(page_url, html_text) 15 new_data = self._get_new_data(html_text) 16 17 return new_urls, new_data 18 19 def _get_new_urls(self, page_url, html_text):20 """ 21 返回解析後的 url 集合 22 :param page_url: url 23 :param html_text: 頁面內容 24 :return: set 25 """ 26 new_urls = set() 27 links = re.compile(r'\?start=\d+').findall(html_text) 28 for link in links: 29 new_urls.add(page_url.split('?')[0] + link) 30 return new_urls 31 32 def _get_new_data(self, html_text): 33 """ 34 返回解析後的資料列表 35 :param html_text: 頁面內容 36 :return: list 37 """ 38 datas = [] 39 for html in etree.HTML(html_text).xpath('//ol[@class="grid_view"]/li'): 40 name = html.xpath('./div/div[@class="info"]/div[@class="hd"]/a/span[1]/text()')[0] 41 score = html.xpath('./div/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[2]/text()')[0] 42 person_num = html.xpath('./div/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[4]/text()')[0].strip('人評價') 43 datas.append([name, score, person_num]) 44 return datas