
資料結構之查詢(下):雜湊表
雜湊(雜湊)技術既是一種儲存方法,也是一種查詢方法。然而它與線性表、樹、圖等結構不同的是,前面幾種結構,資料元素之間都存在某種邏輯關係,可以用連線圖示表示出來,而雜湊技術的記錄之間不存在什麼邏輯關係,它只與關鍵字有關聯。因此,雜湊主要是面向查詢的儲存結構。雜湊技術最適合的求解問題是查詢與給定值相等的記錄。

一、基本概念及原理
1.1 雜湊定義的引入
這裡首先看一個場景:在大多數情況下,陣列中的索引並不具有實際的意義,它僅僅表示一個元素在陣列中的位置而已,當需要查詢某個元素時,往往會使用有實際意義的欄位。例如下面一段程式碼,它使用學生的學號來查詢學生的地址。
(1)學生實體類定義

public class StudentInfo
{
public string Number { get; set; }
public string Address { get; set; }
public StudentInfo(string number, string address)
{
Number = number;
Address = address;
}
}
(2)通過索引遍歷查詢
static StudentInfo[] InitialStudents()
{
StudentInfo[] arrStudent = {
new StudentInfo("200807001","四川達州"),
new StudentInfo("200807002","四川成都"),
new StudentInfo("200807003","山東青島"),
new StudentInfo("200807004","河南鄭州"),
new StudentInfo("200807005","江蘇徐州")
};
return arrStudent;
}
static void NormalSearch(StudentInfo[] arrStudent, string searchNumber)
{
bool isFind = false;
foreach (var student in arrStudent)
{
if (student.Number == searchNumber)
{
isFind = true;
Console.WriteLine("Search successfully!{0} address:{1}", searchNumber, student.Address);
}
}
if (!isFind)
{
Console.WriteLine("Search {0} failed!", searchNumber);
}
}
static void Main(string[] args)
{
StudentInfo[] arrStudent = InitialStudents();
// 01.普通陣列遍歷查詢
NormalSearch(arrStudent, "200807005");
Console.ReadKey();
}
執行結果如下圖所示,可以看到圓滿完成了查詢任務。

但是,如果查詢的記錄位於陣列的最後或者根本就不存在,仍然需要遍歷整個陣列。當陣列非常巨大時,還以這樣的方式查詢將會消耗較多的時間。是否有一種方法可以通過學號關鍵字就能直接地定位到相應的記錄?
(3)改寫查詢方式為雜湊查詢
通過觀察學號記錄與索引的對應關係,學號的後三位陣列恰好是一組有序數列,如果把每個學生的學號後三位陣列抽取出來並減去1,結果剛好可以與陣列的索引號一一對應。於是,我們可以將上例改寫為如下方式:
static int GetHashCode(string number)
{
string index = number.Substring(6);
return Convert.ToInt32(index) - 1;
}
static void HashSearch(StudentInfo[] arrStudent, string searchNumber)
{
Console.WriteLine("{0} address:{1}", searchNumber, arrStudent[GetHashCode(searchNumber)].Address);
}
static void Main(string[] args)
{
StudentInfo[] arrStudent = InitialStudents();
HashSearch(arrStudent, "200807005");
HashSearch(arrStudent, "200807001");
Console.ReadKey();
}
可以看出,通過封裝GetHashCode()方法,實現了學號與陣列索引的一一對應關係,在查詢中直接定位到了索引號,避免了遍歷操作,從而提高了查詢效率,從原來的O(n)提高到了O(1),執行結果如下圖所示:
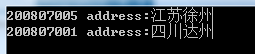
上例中的學號是不重複的,它可以唯一標識學生集合中的每一條記錄,這樣的欄位就被稱為key(關鍵字)。而在記錄儲存地址和它的關鍵字之間建立一個確定的對應關係h,使得每個關鍵字和一個唯一的儲存位置相對應。在查詢時,只需要根據這個對應關係h,就可以找到所需關鍵字及其對應的記錄,這種查詢方式就被稱為雜湊查詢,關鍵字和儲存位置的對應關係可以用函式表示為:
h(key)=儲存地址
1.2 構造雜湊函式的方法
構造雜湊函式的目標在於使雜湊地址儘可能均勻地分佈在連續的記憶體單元地址上,以減少發生衝突的可能性,同時使計算儘可能簡單以達到儘可能高的時間效率,這裡主要看看兩個構造雜湊函式的方法。
(1)直接地址法
直接地址法取關鍵字的某個線性函式值為雜湊地址,即h(key)=key 或 h(key)=a*key+b
其中,a、b均為常數,這樣的雜湊函式優點就是簡單、均勻,也不會產生衝突,但問題是這需要事先知道關鍵字的分佈情況,適合查詢表較小且連續的情況。由於這樣的限制,在現實應用中,此方法雖然簡單,但卻並不常用。
(2)除留餘數法
除留餘數法採用取模運算(%)把關鍵字除以某個不大於雜湊表表長的整數得到的餘數作為雜湊地址,它也是最常用的構造雜湊函式的方法,其形式為:h(key)=key%p
![]()
本方法的關鍵就在於選擇合適的p,p如果選得不好,就可能會容易產生同義詞。
PS:根據前輩們的經驗,若雜湊表表長為m,通常p為小於或等於表長(最好接近m)的最小質數或不包含小於20質因子的合數。
1.3 解決雜湊衝突的方法
(1)閉雜湊法
閉雜湊法時把所有的元素都儲存在雜湊表陣列中,當發生衝突時,在衝突位置的附近尋找可存放記錄的空單元。尋找“下一個”空位的過程則稱為探測。上述方法可用如下公式表示為:

其中,h(key)為雜湊函式,m為雜湊表長度,di為遞增的序列。根據di的不同,又可以分為幾種探測方法:線性探測法、二次探測法以及雙重雜湊法。
(2)開雜湊法
開雜湊法的常見形式是將所有關鍵字為同義詞的記錄儲存在一個單鏈表中。我們稱這種表為同義詞子表,在散列表中只儲存所有同義詞子表的頭指標。對於關鍵字集合{12,67,56,16,25,37,22,29,15,47,48,34},我們用前面同樣的12為除數,進行除留餘數法,可得到如下圖所示的結構,此時,已經不存在什麼衝突換址的問題,無論有多少個衝突,都只是在當前位置給單鏈表增加結點的問題。

該方法對於可能會造成很多衝突的雜湊函式來說,提供了絕不會出現找不到地址的保障。當然,這也就帶來了查詢時需要遍歷單鏈表的效能損耗。在.NET中,連結串列的各個元素分散於託管堆各處,也會給GC垃圾回收帶來壓力,影響程式的效能。
二、.NET中的Hashtable
2.1 Hashtable的用法
在.NET中,實現了雜湊表資料結構的集合類有兩個,其中一個就是Hashtable,另一個是泛型版本的Dictionary<TKey,TValue>。這裡我們首先看看Hashtable的用法,由於Hashtable中key/value鍵值對均為object型別,所以Hashtable可以支援任何型別的key/value鍵值對。
static void HashtableTest()
{
// 建立一個Hashtable例項
Hashtable ht = new Hashtable();
// 新增key/value鍵值對
ht.Add("北京", "帝都");
ht.Add("上海", "魔都");
ht.Add("廣州", "省會");
ht.Add("深圳", "特區");
// 根據key獲取value
string capital = (string)ht["北京"];
Console.WriteLine("北京:{0}", capital);
Console.WriteLine("--------------------");
// 判斷雜湊表是否包含特定鍵,其返回值為true或false
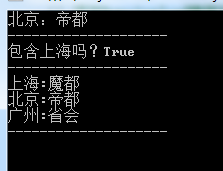
Console.WriteLine("包含上海嗎?{0}",ht.Contains("上海"));
Console.WriteLine("--------------------");
// 移除一個key/value鍵值對
ht.Remove("深圳");
// 遍歷雜湊表
foreach (DictionaryEntry de in ht)
{
Console.WriteLine("{0}:{1}", de.Key, de.Value);
}
Console.WriteLine("--------------------");
// 移除所有元素
ht.Clear();
// 遍歷雜湊表
foreach (DictionaryEntry de in ht)
{
Console.WriteLine("{0}:{1}", de.Key, de.Value);
}
}
執行結果如下圖所示:
2.2 剖析Hashtable
(1)閉雜湊法
Hashtable內部使用了閉雜湊法來解決衝突,它通過一個結構體bucket來表示雜湊表中的單個元素,這個結構體有三個成員:
private struct bucket
{
public object key;
public object val;
public int hash_coll;
}
兩個object型別(那麼必然會涉及到裝箱和拆箱操作)的變數,其中key表示鍵,val表示值,而hash_coll則是一個int型別,它用於表示鍵所對應的雜湊碼。眾所周知,一個int型別佔4個位元組(這裡主要探討32位系統中),一個位元組又是8位,那麼4*8=32位。它的最高位是符號位,當最高位為“0”時,表示是一個正整數,而為“1”時則表示是一個負整數。hash_coll使用最高位表示當前位置是否發生衝突,為“0”時也就是正數時,表示未發生衝突;為“1”時,則表示當前位置存在衝突。之所以專門使用一個標誌位用於標註是否發生衝突,主要是為了提高雜湊表的執行效率。
(2)雙重雜湊法
Hashtable解決衝突使用了雙重雜湊法,但又與普通的雙重雜湊法不同。它探測地址的方法如下:

其中,雜湊函式h1和h2的公式有如下所示:

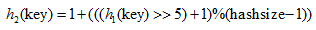
由於使用了二度雜湊,最終的h(key,i)的值有可能會大於hashsize,所以需要對h(key,i)進行取模運算,最終計算的雜湊地址為:
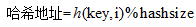
這裡需要注意的是:在bucket結構體中,hash_coll變數儲存的是h(key,i)的值而不是最終的雜湊地址。

Hashtable通過關鍵字查詢元素時,首先會計算出鍵的雜湊地址,然後通過這個雜湊地址直接訪問陣列的相應位置並對比兩個鍵值,如果相同,則查詢成功並返回;如果不同,則根據hash_coll的值來決定下一步操作。
①當hash_coll為0或整數時,表明沒有衝突,此時表明查詢失敗;
②當hash_coll為負數時,表明存在衝突,此時需要通過二度雜湊繼續計算雜湊地址進行查詢,如此反覆直到找到相應的鍵值表明查詢成功,如果在查詢過程中遇到hash_coll為正數或計算二度雜湊的次數等於雜湊表長度則查詢失敗。
由此可知,將hash_coll的高位設為衝突檢測位主要是為了提高查詢速度,避免無意義地多次計算二度雜湊的情況。
(3)使用素數實現hashsize
通過檢視Hashtable的建構函式,我們可以發現呼叫了HashHelpers的GetPrime方法生成了一個素數來為hashsize賦值:
public Hashtable(int capacity, float loadFactor)
{
.......
int num2 = (num > 3.0) ? HashHelpers.GetPrime((int) num) : 3;
this.buckets = new bucket[num2];
this.loadsize = (int) (this.loadFactor * num2);
.......
}
Hashtable是可以自動擴容的,當以指定長度初始化雜湊表或給雜湊表擴容時都需要保證雜湊表的長度為素數,GetPrime(int min)方法正是用於獲取這個素數,引數min表示初步確定的雜湊表長度,它返回一個比min大的最合適的素數。
三、.NET中的Dictionary
3.1 Dictionary的用法
Dictionary是泛型版本的雜湊表,但和Hashtable之間並非只是簡單的泛型和非泛型的區別,兩者使用了完全不同的雜湊衝突解決辦法,我們先來看看Dictionary如何使用。
static void DictionaryTest()
{
Dictionary<string, StudentInfo> dict = new Dictionary<string, StudentInfo>();
for (int i = 0; i < 10; i++)
{
StudentInfo stu = new StudentInfo()
{
Number = "200807" + i.ToString().PadLeft(3, '0'),
Name = "Student" + i.ToString()
};
dict.Add(i.ToString(), stu);
}
// 判斷是否包含某個key
if (dict.ContainsKey("1"))
{
Console.WriteLine("已經存在key為{0}的鍵值對了,它是{1}", 1, dict["1"].Name);
}
Console.WriteLine("--------------------------------");
// 遍歷鍵值對
foreach (var de in dict)
{
Console.WriteLine("Key:{0},Value:[Number:{1},Name:{2}]", de.Key, de.Value.Number, de.Value.Name);
}
// 移除一個鍵值對
if(dict.ContainsKey("5"))
{
dict.Remove("5");
}
Console.WriteLine("--------------------------------");
// 遍歷鍵值對
foreach (var de in dict)
{
Console.WriteLine("Key:{0},Value:[Number:{1},Name:{2}]", de.Key, de.Value.Number, de.Value.Name);
}
// 清空鍵值對
dict.Clear();
Console.WriteLine("--------------------------------");
// 遍歷鍵值對
foreach (var de in dict)
{
Console.WriteLine("Key:{0},Value:[Number:{1},Name:{2}]", de.Key, de.Value.Number, de.Value.Name);
}
}
執行結果如下圖所示:

3.2 剖析Dictionary
(1)較Hashtable簡單的雜湊地址公式
Dictionary的雜湊地址求解方式較Hashtable簡單了許多,其計算公式如下所示:
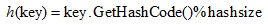
通過檢視其原始碼,在Add方法中驗證是否是上面的地址計算方式:
int num = this.comparer.GetHashCode(key) & 0x7fffffff; int index = num % this.buckets.Length;
(2)內部兩個陣列結合的儲存結構

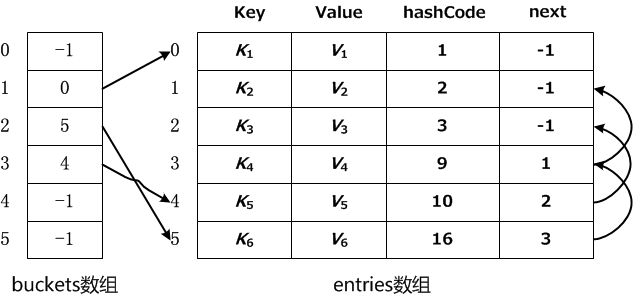
Dictionary內部有兩個陣列,一個數組名為buckets,用於存放由多個同義詞組成的靜態連結串列頭指標(連結串列的第一個元素在陣列中的索引號,當它的值為-1時表示此雜湊地址不存在元素);另一個數組為entries,它用於存放雜湊表中的實際資料,同時這些資料通過next指標構成多個單鏈表。entries中所存放的是Entry結構體,Entry結構體由4個部分組成,如下所示:
private struct Entry
{
public int hashCode;
public int next;
public TKey key;
public TValue value;
}
Dictionary將多個連結串列繼承於一個順序表之中進行統一管理:
Hashtable 與 Dictionary 的區別:
①Hashtable使用閉雜湊法來解決衝突,而Dictionary使用開雜湊法解決衝突;
②Dictionary相對Hashtable來說需要更多的儲存空間,但它不會發生二次聚集的情況,並且使用了泛型,相對非泛型可能需要的裝箱和拆箱操作,Dictionary的速度更快;
③Hashtable使用了填充因子的概念,而Dictionary則不存在填充因子的概念;
④Hashtable在擴容時由於重新計算雜湊地址,會消耗大量時間計算,而Dictionary的擴容相對Hashtable來說更快;
⑤單執行緒程式中推薦使用Dictionary,而多執行緒程式中則推薦使用Hashtable。預設的Hashtable允許單執行緒寫入,多執行緒讀取,對Hashtable進一步呼叫Synchronized()方法可以獲得完全執行緒安全的型別。相反,Dictionary不是執行緒安全的,必須人為使用lock語句進行保護,效率有所降低。
四、.NET中幾種查詢表的對比
4.1 測試對比介紹
在.NET中有三種主要的查詢表的資料結構,分別是SortedDictionary(前面已經介紹過了,其內部是紅黑樹資料結構實現)、Hashtable與Dictionary。本次測試會首先建立一個100萬個隨機排列整數的陣列,然後將陣列中的數字依次插入三種資料結構中,最後從三種資料結構中刪除所有資料,每個操作分別計算耗費時間(這裡計算操作使用了老趙的CodeTimer類實現效能計數)。
(1)準備工作:初始化一個100萬個隨機數的陣列
int length = 1000000;
int[] arrNumber = new int[length];
// 首先生成有序陣列進行初始化
for (int i = 0; i < length; i++)
{
arrNumber[i] = i;
}
Random rand = new Random();
// 隨機將陣列中的數字打亂順序
for (int i = 0; i < length; i++)
{
int randIndex = rand.Next(i,length);
// 交換兩個數字
int temp = arrNumber[i];
arrNumber[i] = arrNumber[randIndex];
arrNumber[randIndex] = temp;
}
(2)測試SortedDictionary
// Test1:SortedDictionary型別測試
SortedDictionary<int, int> sd = new SortedDictionary<int, int>();
Console.WriteLine("SortedDictionary插入測試開始:");
CodeTimer.Time("SortedDictionary_Insert_Test", 1, () =>
{
for (int i = 0; i < length; i++)
{
sd.Add(arrNumber[i], arrNumber[i]);
}
});
Console.WriteLine("SortedDictionary插入測試結束;");
Console.WriteLine("-----------------------------");
Console.WriteLine("SortedDictionary刪除測試開始:");
CodeTimer.Time("SortedDictionary_Delete_Test", 1, () =>
{
for (int i = 0; i < length; i++)
{
sd.Remove(arrNumber[i]);
}
});
Console.WriteLine("SortedDictionary刪除測試結束;");
Console.WriteLine("-----------------------------");
(3)測試Hashtable
// Test2:Hashtable型別測試
Hashtable ht = new Hashtable();
Console.WriteLine("Hashtable插入測試開始:");
CodeTimer.Time("Hashtable_Insert_Test", 1, () =>
{
for (int i = 0; i < length; i++)
{
ht.Add(arrNumber[i], arrNumber[i]);
}
});
Console.WriteLine("Hashtable插入測試結束;");
Console.WriteLine("-----------------------------");
Console.WriteLine("Hashtable刪除測試開始:");
CodeTimer.Time("Hashtable_Delete_Test", 1, () =>
{
for (int i = 0; i < length; i++)
{
ht.Remove(arrNumber[i]);
}
});
Console.WriteLine("Hashtable刪除測試結束;");
Console.WriteLine("-----------------------------");
(4)測試Dictionary
// Test3:Dictionary型別測試
Dictionary<int, int> dict = new Dictionary<int, int>();
Console.WriteLine("Dictionary插入測試開始:");
CodeTimer.Time("Dictionary_Insert_Test", 1, () =>
{
for (int i = 0; i < length; i++)
{
dict.Add(arrNumber[i], arrNumber[i]);
}
});
Console.WriteLine("Dictionary插入測試結束;");
Console.WriteLine("-----------------------------");
Console.WriteLine("Dictionary刪除測試開始:");
CodeTimer.Time("Dictionary_Delete_Test", 1, () =>
{
for (int i = 0; i < length; i++)
{
dict.Remove(arrNumber[i]);
}
});
Console.WriteLine("Dictionary刪除測試結束;");
Console.WriteLine("-----------------------------");
4.2 測試對比結果
(1)SortedDictionary測試結果:

SortedDictionary內部是紅黑樹結構,在插入和刪除操作時需要經過大量的旋轉操作來維持平衡,因此耗時是三種類型中最多的。此外,在插入過程中,引起了GC大量的垃圾回收操作。
(2)Hashtable測試結果:

Hashtable插入操作的耗時和SortedDictionary相近,但刪除操作卻比SortedDictionary快了好幾倍。
(3)Dictionary測試結果:

Dictionary在插入和刪除操作上是三種類型中最快的,且對GC的友好程度上也較前兩種型別好很多。
參考資料
(1)陳廣,《資料結構(C#語言描述)》
(2)程傑,《大話資料結構》
(3)段恩澤,《資料結構(C#語言版)》
作者:周旭龍
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連結。
