
使用 EXISTS 代替 IN 和 inner join
在使用Exists時,如果能正確使用,有時會提高查詢速度:
1,使用Exists代替inner join
2,使用Exists代替 in
1,使用Exists代替inner join例子:
在一般寫sql語句時通常會遇到如下語句:
兩個表連線時,取一個表的資料,一般的寫法通過關聯查詢(inner join):
select a.id, a.workflowid,a.operator,a.stepid from dbo.[[zping.com]]] a inner join workflowbase b on a.workflowid=b.id and operator='4028814111ad9dc10111afc134f10041'
查詢結果:
(1327 行受影響) 表 'Worktable'。掃描計數 0,邏輯讀取 0 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 表 'workflowbase'。掃描計數 1,邏輯讀取 293 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 表 '[zping.com]'。掃描計數 1,邏輯讀取 1339 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
還有一種寫法使用exists來取資料
select a.id,a.workflowid,a.operator ,a.stepid from dbo.[[zping.com]]] a where exists (select 'X' from workflowbase b where a.workflowid=b.id) and operator='4028814111ad9dc10111afc134f10041'
執行結果:
(1327 行受影響) 表 '[zping.com]'。掃描計數 1,邏輯讀取 1339 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 表 'workflowbase'。掃描計數 1,邏輯讀取 291 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
這裡兩著的IO次數,EXISTS比inner join少 2個IO, 對比執行計劃成本不一樣, 看看兩著的差異:
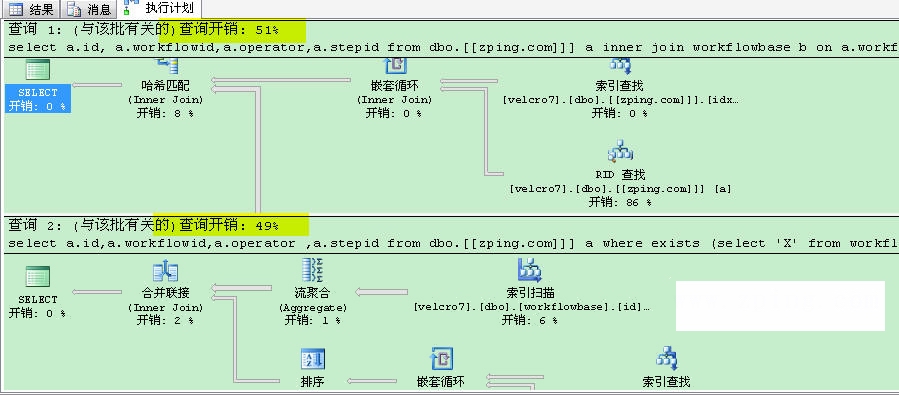
這時我們發現使用EXISTS要比inner join效率稍微高一下。 2,使用Exists代替 in
要求:編寫workflowbase表中id不在表中dbo.[[zping.com]]]的行:
一般的寫法:
select * from workflowbase where id not in ( select a.workflowid from dbo.[[zping.com]]] a )
執行結果:

(1 行受影響) 表 'Worktable'。掃描計數 0,邏輯讀取 0 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 表 '[zping.com]'。掃描計數 5,邏輯讀取 56952 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 表 'workflowbase'。掃描計數 3,邏輯讀取 1589 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 表 'Worktable'。掃描計數 0,邏輯讀取 0 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
使用Existsl來寫:
select * from workflowbase b where not exists( select 'X' from dbo.[[zping.com]]] a where a.workflowid=b.id )
看看執行結果
(1 行受影響) 表 'Worktable'。掃描計數 0,邏輯讀取 0 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 表 '[zping.com]'。掃描計數 3,邏輯讀取 18984 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 表 'workflowbase'。掃描計數 3,邏輯讀取 1589 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
兩個io的差距:56952+1589=58541次 (使用IN)
18984+1589=20573次 (使用Exists)
使用exists是in的2.8倍,查詢效能提高很大。
EXISTS 使查詢更為迅速,因為RDBMS核心模組將在子查詢的條件一旦滿足後,立刻返回結果。
in和inner join在大多數情況下都是返回兩表的交集,但是兩者還是有區別的,如下例子
mysql> select * from a; +------+------+ | id | name | +------+------+ | 1 | a | | 2 | b | | 3 | c | +------+------+
MySQL> select * from b; +------+------+ | id | name | +------+------+ | 1 | d | | 1 | g | | 2 | e | | 4 | f | +------+------+
mysql> select a.id, a.name from a where a.id in (select b.id from b); +------+------+ | id | name | +------+------+ | 1 | a | | 2 | b | +------+------+
mysql> select a.id, a.name from a inner join b on (a.id = b.id); +------+------+ | id | name | +------+------+ | 1 | a | | 1 | a | | 2 | b | +------+------+
mysql> select * from a inner join b on (a.id = b.id); +------+------+------+------+ | id | name | id | name | +------+------+------+------+ | 1 | a | 1 | d | | 1 | a | 1 | g | | 2 | b | 2 | e | +------+------+------+------+
從查詢結果中可以看出,in的結果是不會有重複的,對非主鍵進行join時,join的結果是有重複的。如果說還有另一個區別的話就是join會產生一個兩表合併的臨時表,in不會產生兩表合併的臨時表。