
資料結構(c語言)—— 七大排序演算法總結
排序是資料結構最重要的演算法之一,在這裡整理一下七大排序演算法的思路及程式碼。
排序分為以下四類共七種排序方法:
插入排序:1) 直接插入排序 2) 希爾排序
選擇排序:3) 直接選擇排序 4) 堆排序
交換排序:5) 氣泡排序 6) 快速排序
合併排序:7) 合併排序
(注:本文中講解均以升序為例)
1、直接插入排序
直接插入排序是最為直接也是最簡單的排序,對於一個無序的序列 a1,a2,a3,…,我們將它分為兩個序列 a1 和 a2,a3,...,因為 a1序列中只有一個元素,我們可以將它看做一個有序序列,剩下的所有元素組成的序列為無序序列,我們只需要從無序序列中一次拿出每個元素,與有序序列中的元素作比較,找到合適的位置並將它插入,直到無序序列為空,此時排序完畢。
具體來說,首先,我們將一個無序陣列分看做兩個子序列,如下圖。在第一個子序列中只有一個元素,因此可以將它看做有序,並且用一個指標 i 指向有序序列的最後一個,即 a1,再用一個指標 j 指向無序序列的第一個元素,即 a2,準備下次一排序。
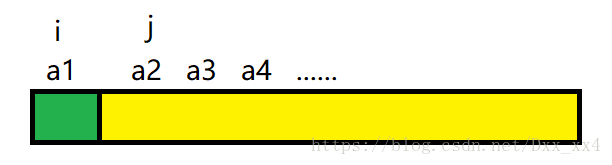
接下來我們來看第二個元素 a2,假設 a2 < a1,那麼我們交換 a2 和 a1,並且讓 i 指標左移一個,j 指標左移一個,此時 i 指標已超出陣列範圍,說明 a2 已到了正確的位置,此趟排序結束,得到一個新的有序序列,再將 i 指標指向有序序列的最後一個元素,將 j 指標指向無需陣列的第一個元素,準備下一趟排序,如下圖。
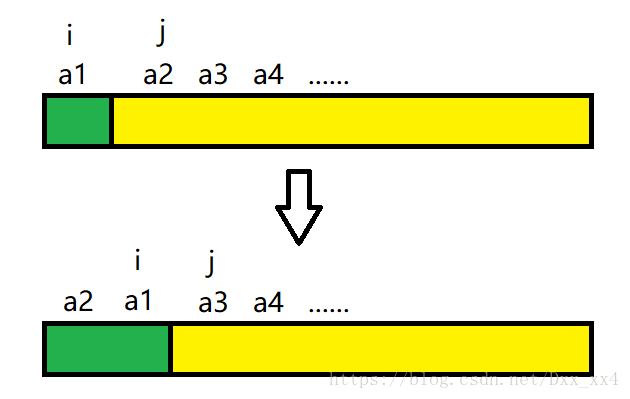
接下來我們再來看第三個元素 a3,比較 i 指標所指向的 a1 與 j 指標指向的 a3,假設 a3 < a1,交換 a1 與 a3,將 i、j 指標分別左移一個,接著比較 i 指標指向的 a2 元素與 j 指標指向的 a3 元素,假設 a2 < a3,則說明 a3 已到了正確的位置,此趟排序結束,得到一個新的有序序列,再將 i 指標指向有序序列的最後一個元素,將 j 指標指向無需陣列的第一個元素,準備下一趟排序,如下圖。
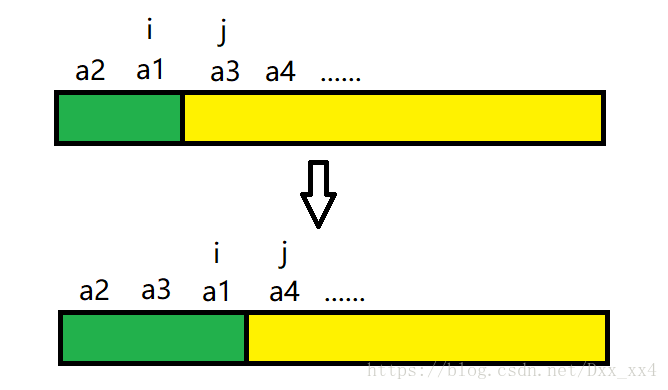
依次類推,直到 i = size-1 時,表明所有的元素都在有序序列中,即該序列排序完成。
例項排序效果如下圖:

程式碼如下:
void InsertSort(int arr[], size_t size) { size_t i = 0; size_t j = 1; int key; size_t right; while(i < size-1){ right = j; while(i >= 0 && arr[j] < arr[i]){ key = arr[i]; arr[i] = arr[j]; arr[j] = key; j--; i--; } j = right+1; i = right; } }
2、希爾排序
希爾排序是在1958年由希爾提出的,是基於直接插入排序的一個優化版本。
首先我們要明確希爾排序出現的原因:
1)當資料項數量不多的時候,插入排序可以很好的完成工作。
2)當資料項基本有序的時候,插入排序具有很高的效率。
基於這兩個原因我們來了解一下希爾排序的步驟:
1)因為對於插入排序,若一個數列天生有序,則其排序效率最高。因此我們對一個序列進行預排序,使其儘量有序。
2)對一個序列進行預排序時,我們採用分組排序的方法,分組的間隔,我們記為 gap。
3)當 gap 越大時,排序的速度越快;而當 gap 越小,排序的效果越好,即預排序後的序列越接近與有序。
因此 gap 是動態變化的,在這裡,我們讓 gap 從 size 開始,每次 gap = gap / 3 + 1,直到 gap == 1 時預排序結束。
4)分組進行排序時,每組組內我們都採用插排的方式來排序。
以下面這個逆序的序列為例,在這個序列中,size = 9,因此第一次分組時 gap = 4,即每組的間隔為4,在圖中表示為顏色相同的為一組:

我們將每組在組內進行插入排列,得到一個新的序列,在對其進行分組,此時 gap = gap / 3 + 1 ,即 gap = 2,如下圖:

接著我們繼續對得到的新序列進行排序,排序後發現 gap = gap / 3 + 1,即 gap = 1,則此時我們對序列進行最後一次排序後排序完成。

程式碼如下:
void _InsertSort(int arr[], size_t size, size_t gap)
{
size_t i = 0;
size_t j;
size_t k;
int key;
while(i < gap)
{
j = i;
k = j+gap;
while(k < size)
{
key = arr[j];
if(arr[j] > arr[k])
{
arr[j] = arr[k];
arr[k] = key;
}
j += gap; //間隔為gap
k += gap;
}
i++;
}
}
void ShellSort(int arr[], size_t size)
{
size_t gap = size;
while(1)
{
gap = gap/3 + 1;
_InsertSort(arr, size, gap);
if(gap == 1) //排序完成後若gap=1則排序完成
{
break;
}
}
}3、直接選擇排序
直接選擇排序的思路很簡單,就是每次從未排序的序列中選出最小的一個放在已排序的序列末尾,直到未排序序列為空,則排序結束。

就上圖的例子來說,我們定義一個 i 指標記錄未排序序列的第一個元素,再定義一個 j 指標尋找當前序列中的最小元素,當 j 指標找到最小的元素後,交換 i 指標與 j 指標的元素,然後讓 i 指標後移一位,指向當前未排序序列中的第一個元素,j 指標從 i 指標指向的位置開始遍歷,尋找下一個最小的元素,以此類推,當 i 指標走到序列末尾時,排序結束。
顯然,這樣一個一個尋找最小元素然後放到隊尾的效率實在是太低了,那麼我們可以將它優化一下,用兩個指標同時指向序列的頭和尾,此時當一次遍歷時就可以同時尋找當前序列中的最大元素和最小元素,然後分別放到序列的開頭結尾,當指向頭和尾的指標相遇時,排序結束。這樣雖然效率會高一些,但時間複雜度其實和上面的方法是一樣的。
程式碼如下:
void Swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//選擇排序
void SelectSrot(int arr[], size_t size)
{
size_t minSp = 0; //記錄頭的指標
size_t maxSp = size-1; //記錄尾的指標
size_t minPos = minSp; //尋找最小元素的指標
size_t maxPos = maxSp; //尋找最大元素的指標
size_t i;
while(minSp < maxSp)
{
for(i = minSp; i <= maxSp; i++)
{
if(arr[i] < arr[minPos])
{
minPos = i;
}
}
Swap(&arr[minSp], &arr[minPos]);
for(i = minSp; i <= maxSp; i++)
{
if(arr[i] > arr[maxPos])
{
maxPos = i;
}
}
Swap(&arr[maxSp], &arr[maxPos]);
minSp++;
maxSp--;
}
}4、氣泡排序
氣泡排序應該是我們在學習資料結構之前就很熟悉的一種排序,它的思想就如同它的名字一樣,比較相鄰兩元素的大小,若反序,則交換,每趟將序列中最大的元素交換到最後位置,就像氣泡從水裡冒出一樣。
具體來說,我們定義一個指標 i 指向序列的第一個元素,再定義一個指標 j 指向 i 的下一個元素,比較兩元素的大小,若 j 指標指向的元素小於 i 指標指向的元素,則交換兩指標指向的元素,再將兩指標分別後移一個;反之,直接將兩指標後移一位,繼續下一次比較。當一趟排序完成後,下一次參與排序的元素個數就要減一。

值得注意的是,若在一趟排序中沒有發生任何一次交換,則說明該序列已經有序。
程式碼如下:
void Swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//氣泡排序
void BubbleSort(int arr[], int size)
{
int i, j;
for(i = 0; i < size-1; i++)
{
for(j = 0; j < size-1-i; j++)
{
if(arr[j] > arr[j+1]) //若前一個大於後一個,則交換
{
Swap(arr+j, arr+j+1);
}
}
}
}
5、堆排序
上面我們介紹的所有排序的時間複雜度均為O(n^2),下面我們要介紹的排序演算法均為O(nlogn),可以說都是很優秀的排序演算法,但對於不同的情況,它們有各自的優勢,首先來看堆排序。堆排序的優勢在於它只需要一定數量的額外空間,堆排序要比空間複雜度為O(n)的歸併排序稍微慢一點。
首先,我們來看看堆的定義:一顆二叉樹,任意非葉子節點的左右子節點都同時比它大,或者同時比它小。
堆的定義有很明顯的作用,最小的或者最大的數字永遠在堆頂,因此我們藉助堆的這個特點,實現排序。首先我們根據給出的序列建一個大堆,此時序列中最大的元素就在堆頂,我們取出該元素將它與堆的最後一個元素進行交換,縮小區間,並做向下調整,此時第二大的元素就到了堆頂,再次交換堆頂元素與當前堆的最後一個元素,並縮小區間,以此類推,直到排序完成。
下面我們以序列{53,17,78,9,45,65,87,23,31}為例,首先我們根據給出的序列建堆,並做向下調整,得到第一個大堆。


交換堆頂元素與堆尾元素,同時縮小排序區間,對現在的樹再次進行向下調整,此時的堆頂元素就是第二大的元素。


此時再次交換堆頂元素與堆尾元素,縮小排序區間,再次進行向下調整。


重複上述操作,直到需要排序的堆中只剩一個元素時,排序結束。
程式碼如下:
//向下調整
void AdjustDown(int array[], size_t size, size_t root)
{
size_t left = 2 * root + 1;
size_t right = 2 * root + 2;
size_t max;
while(left < size)
{
max = left;
if(right < size)
{
if(array[right] >= array[max])
{
max = right;
}
}
if(array[root] >= array[max])
{
break;
}
Swap(array+root, array+max);
root = max;
left = 2 * root + 1;
right = 2 * root + 2;
}
}
//堆排
void HeapSort(int array[], int size)
{
int i, j;
for(i = (size - 2 ) / 2; i >= 0; i--)
{
AdjustDown(array, size, i);
}
for(j = 0; j <= size; j++)
{
Swap(array, array + size - 1 - j);
AdjustDown(array, size - 1 - j, 0);
}
}
6、快速排序
快速排序是氣泡排序的改進版,也是最好的一種內排序,在很多面試題中都會出現,也是作為程式設計師必須掌握的一種排序方法。
快速排序的基本思路是這樣的:
1)在待排序的元素任取一個元素作為基準(通常選第一個或最後一個元素),稱為基準元素;
2)將待排序的元素進行分割槽,比基準元素大的元素放在它的右邊,比其小的放在它的左邊;
3)對左右兩個分割槽重複以上步驟直到所有元素都是有序的。
而對於怎樣將待排序元素根據基準值分割槽,有三種方法,分別是:挖坑法、Hoare法和快慢指標法,在下面我們以最後一個元素作為基準值為例來講解一下這三種方法。
挖坑法:
挖坑法,顧名思義就是挖一個“坑”將合適的元素放進去。
首先我們確定最後一個元素為基準元素,定義一個begin指標指向序列的第一個元素,再定義一個end指標指向序列的最後一個元素,即基準元素所在的位置,並定義一個pivot變數儲存基準元素。此時就可以看做我們將基準元素從序列中拿了出來,而基準元素在序列中的位置就可以看做是一個坑。
然後我們開始排序,因為end指標此時指向的是一個“坑”,所以我們讓begin指標先開始遍歷。當begin指向的元素小於或等於基準元素時,begin向後走,當begin遇到第一個大於基準元素的元素時停止遍歷,並將begin所指向的元素放入end所指向的位置,此時begin所在的位置就是一個“坑”了。然後我們讓end開始遍歷,當end指向的元素大於基準元素時,end向前走,當end遇到第一個小於基準元素的元素時,停止遍歷,並將end所指向的元素放入begin所指向的位置,此時end所指向的位置就又變成“坑”了。以此類推,當begin和end相遇時,將最開始拿出去儲存在pivot中的基準值放在最後的坑裡,第一趟排序就結束了。
排序中序列中元素分佈:

下面我們舉個例子來理解一下:
首先我們選擇序列中的最後一個元素作為基準元素,並用變數pivot儲存它的值,定義一個begin指標指向序列開頭,一個end指標指向序列末尾,此時end指標指向的位置就可以看作是一個“坑”。我們讓begin指標從序列開頭開始遍歷,遇到第一個大於基準元素的元素時停止遍歷,即begin在 7 處停止遍歷,並將 7 放入end所指向的“坑”中,此時begin所指向的位置就變成了“坑”。再讓end開始遍歷,當end遇到第一個小於或等於基準元素的元素時停止遍歷,即當end指向 3 時停止遍歷,再將 3 放入begin指向的“坑”中,此時,end所指向的位置就又變成了“坑”,後面以此類推。

當begin指標與end指標相遇時,如下圖所示,此時“坑”左邊的元素全部小於或等於基準值,而坑右邊的元素全部大於基準元素,因此這個“坑”的位置就是基準元素的位置,我們將基準元素放入“坑”中。
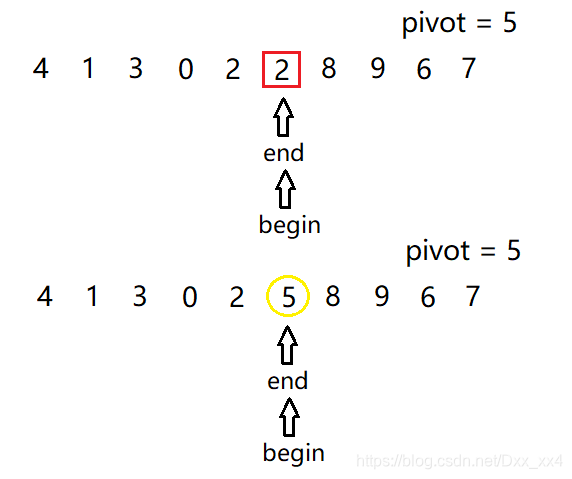
一趟排序完成後,原序列被分成了三部分:基準元素左邊的序列、基準元素、基準元素右邊的序列,我們用分而治之的思想來處理基準元素兩邊的序列,即對左右兩邊的小序列進行同樣方式的排序,直到小序列已經有序(小序列中只有一個元素)或分不出小序列(小序列中有0個元素)時,我們才能得到一個完全有序的序列,排序結束。
挖坑法程式碼如下:
void QuickSort_1(int arr[], int left, int right)
{
int begin = left;
int end = right;
int pivot = arr[right];
if(left >= right) //小序列有序或小序列裡沒有元素時,返回
{
return;
}
while(begin < end)
{
while(begin < end && arr[begin] <= pivot)
{
begin++;
}
arr[end] = arr[begin];
while(end > begin && arr[end] >= pivot)
{
end--;
}
arr[begin] = arr[end];
}
arr[end] = pivot;
QuickSort_1(arr, left, end-1); //遞迴完成基準元素左邊序列的排序
QuickSort_1(arr, end+1, right); //遞迴完成基準元素右邊序列的排序
}
Hoare法:
Hoare法,又叫左右指標法,Hoare法也需要定義一個基準元素,和挖坑法不同的是,Hoare法是通過交換來實現排序的。
首先我們用pivot指標標記最後一個元素作為基準元素,再定義一個begin指標指向序列的開頭,一個end指標指向序列的末尾,讓begin指標從序列開頭開始遍歷,當begin指向的元素小於或等於基準元素時,begin向後走,當begin遇到第一個大於基準元素的元素時,begin停止遍歷,end從序列末尾開始遍歷,當end指向的元素大於基準元素時,end向前走,當end遇到第一個小於基準值的元素時,end停止遍歷,此時交換begin指向的元素和end指向的元素,繼續遍歷,直到begin和end相遇,交換begin指向的元素與pivot指向的元素,第一趟排序完成。
排序中序列中元素分佈:

下面舉例說明:
首先我們選擇序列的最後一個元素作為基準元素,並用pivot指標標記,在定義一個begin指標指向序列開頭,一個end指標指向序列末尾。先讓begin指標開始遍歷,當begin指標遇到第一個大於基準元素的元素時停止遍歷,end指標開始遍歷,當end指標遇到第一個小於或等於基準元素的元素時停止遍歷,交換begin指向的元素和end指向的元素,讓begin指標和end指標繼續遍歷,進行下一次交換,直到begin指標與end指標相遇。

當begin指標與end指標相遇時,如下圖所示,此時begin指標和end指標共同指向的是序列中第一個大於基準元素的元素,那麼我們只需要交換begin指標與pivot指標所指向的元素,就可以完成讓基準元素左邊的元素全部小於或等於基準元素,基準元素右邊的元素全部大於基準元素。

一趟排序完成後,原序列同樣被分成了三部分:基準元素左邊的序列、基準元素、基準元素右邊的序列,我們還是採用分而治之的思想來處理基準元素兩邊的序列,即對左右兩邊的小序列進行同樣方式的排序,直到小序列已經有序(小序列中只有一個元素)或分不出小序列(小序列中有0個元素)時,我們才能得到一個完全有序的序列,排序結束。
Hoare法程式碼如下:
void Swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//Hoare法
void QuickSort_3(int arr[], int left, int right)
{
int begin = left;
int end = right;
if(left >= right)
{
return;
}
while(begin < end)
{
while(begin < end && arr[begin] <= arr[right])
{
begin++;
}
while(begin < end && arr[end] > arr[right])
{
end--;
}
Swap(arr + begin, arr + end);
}
Swap(arr + begin, arr + right);
QuickSort_3(arr, left, begin - 1);
QuickSort_3(arr, begin + 1, right);
}
快慢指標法:
快慢指標法和上述兩個方法略有不同,但快慢指標法的應用範圍更廣,在連結串列中也能很好的使用,使我們必須掌握的排序方法。
首先我們還是確定序列的最後一個元素為基準元素,用指標pivot標記,再定義一個div指標和一個cur指標同時指向序列的開頭。這裡我們要清楚,雖然div和cur是同時從序列的開頭出發,但div指標是指向序列中第一個大於基準元素的元素的,而cur指標是在序列中尋找小於或等於基準元素的元素,並與div指向的元素進行交換,使得小於基準元素的元素與大於基準元素的元素分開。一開始div指標和cur指標同時開始遍歷,當遇到第一個大於基準元素的元素時div停止遍歷,cur繼續向後遍歷,當cur指向的元素小於或等於基準元素時,交換div與cur所指向的元素,div向後走一個,繼續指向序列中第一個大於基準元素的元素,cur繼續向後遍歷,當cur指標與pivot指標相遇時,將基準元素與div指向的元素交換,第一趟排序結束。
排序中序列中元素分佈:

下面我們舉個例子來理解一下:
首先我們選擇序列的最後一個元素作為基準元素,並用pivot指標基準元素的標記,再定一個div指標和一個cur指標指向序列的開頭,讓他們同時從序列的開頭開始遍歷,當遇到第一個大於基準元素的元素,即遇到元素 7 時,div停止遍歷,cur繼續遍歷,當遇到第一個小於或等於基準元素的元素,即元素 2 時,cur停止遍歷,此時div指向的是序列中第一個大於基準元素的元素,因此我們交換div指向的元素和cur指向的元素,使得比基準元素小的元素在比基準元素大的元素前面,交換之後讓div元素向後走一個,即讓div指標繼續指向序列中第一個大於基準元素的元素,cur指標繼續遍歷,直到與pivot指標相遇。

當cur指標與pivot指標相遇時,基準元素之前的序列中所有小於等於基準元素的元素全部都在大於基準元素我的元素前面,因為div指向的是第一個大於基準元素的元素,那麼我們只需要交換div指向的元素與基準元素,就可以將基準元素放在比它大的元素和比它小的元素之間,第一趟排序完成。

一趟排序完成後,原序列同樣被分成了三部分:基準元素左邊的序列、基準元素、基準元素右邊的序列,我們繼續採用分而治之的思想來處理基準元素兩邊的序列,即對左右兩邊的小序列進行同樣方式的排序,直到小序列已經有序(小序列中只有一個元素)或分不出小序列(小序列中有0個元素)時,我們才能得到一個完全有序的序列,排序結束。
快慢指標法程式碼如下:
void Swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//快慢指標法
void QuickSort_2(int arr[], int left, int right)
{
int div = left;
int cur = left;
if(left >= right || left < 0 || right < 0)
{
return;
}
for(; cur < right; cur++)
{
if(arr[cur] <= arr[right])
{
Swap(arr+cur, arr+div);
div++;
}
}
Swap(arr+div, arr+right);
QuickSort_2(arr, left, div-1);
QuickSort_2(arr, div+1, right);
}7、歸併排序
歸併排序的思想很簡單,是建立在歸併操作上的一種有效的排序演算法。該演算法是採用分治法(Divide and Conquer)的一個非常典型的應用。
歸併排序的思想:
將待排序的元素序列分成兩個長度相等的子序列,對每一個子序列排序,然後將它們合併成一個序列。合併兩個子序列的過程稱為二路歸併。
歸併排序的核心步驟:
1、分組。停止條件:①分出的小區間已經有序(區間內只有一個元素)②分出的小區間內沒有元素。
2、歸併。

程式碼如下:
// 合併兩個有序區間
void Merge(int array[], int left, int mid, int right, int extra[])
{
int left_index = left;
int right_index = mid;
int extra_index = left;
while (left_index < mid && right_index < right) {
if (array[left_index] <= array[right_index]) {
extra[extra_index++] = array[left_index++];
}
else {
extra[extra_index++] = array[right_index++];
}
}
while (left_index < mid) {
extra[extra_index++] = array[left_index++];
}
while (right_index < right) {
extra[extra_index++] = array[right_index++];
}
for (int i = left; i < right; i++) {
array[i] = extra[i];
}
}
//歸併排序
void __MergeSort(int array[], int left, int right, int extra[])
{
if (left + 1 == right) {
// 裡面只剩一個數了,所以已經有序了
return;
}
if (left >= right) {
// 區間內沒有數了
return;
}
int mid = left + (right - left) / 2;
__MergeSort(array, left, mid, extra);
__MergeSort(array, mid, right, extra);
// 左右兩個小區間都已經有序了
Merge(array, left, mid, right, extra);
}最後附上各排序演算法的時間、空間複雜度對比:
