
轉載 -- HTTP 協議中的 Content-Encoding
Jerry Qu -- 牛x的作者
HTTP 協議中的 Content-Encoding
https://imququ.com/post/content-encoding-header-in-http.html
如何壓縮 HTTP 請求正文
https://imququ.com/post/how-to-compress-http-request-body.html
HTTP 協議中的 Content-Encoding
提醒:本文最後更新於 975 天前,文中所描述的資訊可能已發生改變,請謹慎使用。
Accept-Encoding 和 Content-Encoding 是 HTTP 中用來對「採用何種編碼格式傳輸正文」進行協定的一對頭部欄位。它的工作原理是這樣:瀏覽器傳送請求時,通過 Accept-Encoding 帶上自己支援的內容編碼格式列表;服務端從中挑選一種用來對正文進行編碼,並通過 Content-Encoding 響應頭指明選定的格式;瀏覽器拿到響應正文後,依據 Content-Encoding 進行解壓。當然,服務端也可以返回未壓縮的正文,但這種情況不允許返回 Content-Encoding。這個過程就是 HTTP 的內容編碼機制。
內容編碼目的是優化傳輸內容大小,通俗地講就是進行壓縮。一般經過 gzip 壓縮過的文字響應,只有原始大小的 1/4。對於文字類響應是否開啟了內容壓縮,是我們做效能優化時首先要檢查的重要專案;而對於 JPG / PNG 這類本身已經高度壓縮過的二進位制檔案,不推薦開啟內容壓縮,效果微乎其微還浪費 CPU。
內容編碼針對的只是傳輸正文。在 HTTP/1 中,頭部始終是以 ASCII 文字傳輸,沒有經過任何壓縮。這個問題在 HTTP/2 中得以解決,詳見:HTTP/2 頭部壓縮技術介紹。
內容編碼使用特別廣泛,理解起來也很簡單,隨手開啟一個網頁抓包看下請求響應就能明白。唯一要注意的是不要把它與 HTTP 中的另外一個概念:傳輸編碼(Transfer-Encoding)搞混即可。
有關 HTTP 內容編碼機制我打算只介紹這麼多,下面重點介紹兩種具體的內容編碼格式:gzip 和 deflate,具體會涉及到兩個問題:1)gzip 和 deflate 分別是什麼編碼?2)為什麼很少見到 Content-Encoding: deflate?
開始之前,先來介紹三種資料壓縮格式:
- DEFLATE,是一種使用 Lempel-Ziv 壓縮演算法(LZ77)和哈夫曼編碼的資料壓縮格式。定義於 RFC 1951 : DEFLATE Compressed Data Format Specification;
- ZLIB,是一種使用 DEFLATE 的資料壓縮格式。定義於 RFC 1950 : ZLIB Compressed Data Format Specification;
- GZIP,是一種使用 DEFLATE 的檔案格式。定義於 RFC 1952 : GZIP file format specification;
這三個名詞有太多的含義,很容易讓人暈菜。所以本文有如下約定:
- DEFLATE、ZLIB、GZIP 這種大寫字元,表示資料壓縮格式;
- deflate、gzip 這種小寫字元,表示 HTTP 中 Content-Encoding 的取值;
- Gzip 特指 GUN zip 檔案壓縮程式,Zlib 特指 Zlib 庫;
在 HTTP/1.1 的初始規範 RFC 2616 的「3.5 Content Codings」這一節中,這樣定義了 Content-Encoding 中的 gzip 和 deflate:
- gzip,一種由檔案壓縮程式「Gzip,GUN zip」產生的編碼格式,描述於 RFC 1952。這種編碼格式是一種具有 32 位 CRC 的 Lempel-Ziv 編碼(LZ77);
- deflate,由定義於 RFC 1950 的「ZLIB」編碼格式與 RFC 1951 中描述的「DEFLATE」壓縮機制組合而成的產物;
RFC 2616 對 Content-Encoding 中的 gzip 的定義很清晰,它就是指在 RFC 1952 中定義的 GZIP 編碼格式;但對 deflate 的定義含糊不清,實際上它指的是 RFC 1950 中定義的 ZLIB 編碼格式,但 deflate 這個名字特別容易產生誤會。
在 Zlib 庫的官方網站,有這麼一條 FAQ:What's the difference between the "gzip" and "deflate" HTTP 1.1 encodings? 就是在討論 HTTP/1.1 對 deflate 的錯誤命名:
Q:在 HTTP/1.1 的 Content-Encoding 中,gzip 和 deflate 的區別是什麼?
A:gzip 是指 GZIP 格式,deflate 是指 ZLIB 格式。HTTP/1.1 的作者或許應該將後者稱之為
zlib,從而避免與原始的 DEFLATE 資料格式產生混淆。雖然 HTTP/1.1 RFC 2016 正確指出,Content-Encoding 中的 deflate 就是 RFC 1950 描述的 ZLIB,但仍然有報告顯示部分伺服器及瀏覽器錯誤地生成或期望收到原始的 DEFLATE 格式,特別是微軟。所以雖然使用 ZLIB 更為高效(實際上這正是 ZLIB 的設計目標),但使用 GZIP 格式可能更為可靠,這一切都是因為 HTTP/1.1 的作者不幸地選擇了錯誤的命名。結論:在 HTTP/1.1 的 Content-Encoding 中,請使用 gzip。
在 HTTP/1.1 的修訂版 RFC 7230 的 4.2 Compression Codings 這一節中,徹底明確了 deflate 的含義,對 gzip 也做了補充:
-
deflate,包含「使用 Lempel-Ziv 壓縮演算法(LZ77)和哈夫曼編碼的 DEFLATE 壓縮資料流(RFC 1951)」的 ZLIB 資料格式(RFC 1950)。注:一些不符合規範的實現會發送沒有經過 ZLIB 包裝的 DEFLATE 壓縮資料;
-
gzip,具有 32 位迴圈冗餘檢查(CRC)的 LZ77 編碼,通常由 Gzip 檔案壓縮程式(RFC 1952)產生。接受方應該將 x-gzip 視為 gzip;
總結一下,HTTP 標準中定義的 Content-Encoding: deflate,實際上指的是 ZLIB 編碼(RFC 1950)。但由於 RFC 2616 中含糊不清的定義,導致 IE 錯誤地實現為只接受原始 DEFLATE(RFC 1951)。為了相容 IE,我們只能用 Content-Encoding: gzip 進行內容編碼,它指的是 GZIP 編碼(RFC 1952)。
其實上,ZLIB 和 DEFLATE 的差別很小:ZLIB 資料去掉 2 位元組的 ZLIB 頭,再忽略最後 4 位元組的校驗和,就變成了 DEFLATE 資料。在 Fiddler 增加以下處理,就可以讓 IE 支援標準的 Content-Encoding: deflate(ZLIB 編碼),很好奇為啥微軟一直不改。
JSif ((compressedData.Length > 2) &&
((compressedData[0] & 0xF) == 0x8) && // Low 4-bits must be 8
((compressedData[0] & 0x80) == 0) && // High-bit must be clear
((((compressedData[0] << 8) + compressedData[1]) % 31) == 0)) // Validate checksum
{
Debug.Write("Fiddler: Ignoring RFC1950 Header bytes for DEFLATE");
iStartOffset = 2;
}
由於其它瀏覽器也能解析原始 DEFLATE,所以有些 WEB 應用乾脆為了遷就 IE 直接輸出原始 DEFLATE,個人覺得這種不遵守標準的做法不值得推薦,還是推薦直接用 GZIP 編碼來獲得更好的相容性。
另外 Google 提出的 sdch 這種內容編碼方式,我之前關注過一段時間,不過只停留在理論階段,所以本文沒有提及,感興趣的同學可以自己去研究。
最後預告一下:今天這篇 Content-Encoding 以及 GZIP、ZLIB、DEFLATE 編碼格式的科普文,是為下一篇講《如何壓縮 HTTP 請求正文》做準備,敬請期待!
————————————————————————————————————————————
如何壓縮 HTTP 請求正文
文章目錄
提醒:本文最後更新於 973 天前,文中所描述的資訊可能已發生改變,請謹慎使用。
上篇文章中,我介紹了 HTTP 協議中的 Accept-Encoding/Content-Encoding 機制。這套機制可以很好地用於文字類響應正文的壓縮,可以大幅減少網路傳輸,從而一直被廣泛使用。但 HTTP 請求的發起方(例如瀏覽器),無法事先知曉要訪問的服務端是否支援解壓,所以現階段的瀏覽器沒有壓縮請求正文。
有一些通訊協議基於 HTTP 做了擴充套件,他們的客戶端和服務端是專用的,可以放心大膽地壓縮請求正文。例如 WebDAV 客戶端就是這樣。
實際的 Web 專案中,會存在請求正文非常大的場景,例如發表長篇部落格,上報用於除錯的網路資料等等。這些資料如果能在本地壓縮後再提交,就可以節省網路流量、減少傳輸時間。本文介紹如何對 HTTP 請求正文進行壓縮,包含如何在服務端解壓、如何在客戶端壓縮兩個部分。
開始之前,先來介紹本文涉及的三種資料壓縮格式:
- DEFLATE,是一種使用 Lempel-Ziv 壓縮演算法(LZ77)和哈夫曼編碼的壓縮格式。詳見 RFC 1951;
- ZLIB,是一種使用 DEFLATE 的壓縮格式,對應 HTTP 中的 Content-Encoding: deflate。詳見 RFC 1950;
- GZIP,也是一種使用 DEFLATE 的壓縮格式,對應 HTTP 中的 Content-Encoding: gzip。詳見 RFC 1952;
Content-Encoding 中的 deflate,實際上是 ZLIB。為了清晰,本文將 DEFLATE 稱之為 RAW DEFLATE,ZLIB 和 GZIP 都是 RAW DEFLATE 的不同 Wrapper。
解壓請求正文
服務端收到請求正文後,需要分析請求頭中的 Content-Encoding 欄位,才能知道正文采用了哪種壓縮格式。本文規定用 gzip、deflate 和 deflate-raw 分別表示請求正文采用 GZIP、ZLIB 和 RAW DEFLATE 壓縮格式。
Nginx
Nginx 沒有類似於 Apache 的 SetInputFilter 指令,不能直接給請求新增處理邏輯,還好有 OpenResty。OpenResty 通過整合 Lua 及大量 Lua 庫,極大地提升了 Nginx 的功能豐富度和可擴充套件性。而 LuaJIT 中的 FFI 庫,允許純 Lua 程式碼呼叫外部 C 函式,使用 C 資料結構。
把這一切結合起來,就能方便地實現這個需求:首先安裝 OpenResty;下載並解壓 Zlib 庫的 FFI 版;然後在 Nginx 的配置中,通過 lua_package_path 指令將這個庫引入;再新建一個 lua 檔案,如 request-compress.lua,呼叫 Zlib 庫實現解壓功能:
LUAlocal ffi = require "ffi"
local zlib = require "zlib"
local function reader(s)
local done
return function()
if done then return end
done = true
return s
end
end
local function writer()
local t = {}
return function(data, sz)
if not data then return table.concat(t) end
t[#t + 1] = ffi.string(data, sz)
end
end
local encoding = ngx.req.get_headers()['Content-Encoding']
if encoding == 'gzip' or encoding == 'deflate' or encoding == 'deflate-raw' then
ngx.req.clear_header('Content-Encoding');
ngx.req.read_body()
local body = ngx.req.get_body_data()
if body then
local write = writer()
local map = {
gzip = 'gzip',
deflate = 'zlib',
['deflate-raw'] = 'deflate'
}
local format = map[encoding]
zlib.inflate(reader(body), write, nil, format)
ngx.req.set_body_data(write())
end
end
我們的 Nginx 一般都是擋在最前面,背後還有 PHP、Node.js 等實際服務。這段程式碼從 Content-Encoding 請求頭中獲取請求壓縮格式,並在解壓後移除了這個頭部。這樣對於 Nginx 背後的服務來說,完全感知不到跟平常有什麼不一樣。
現在還差最後一步,找到 Nginx 中配置 xxx_pass(proxy_pass、uwsgi_pass、fastcgi_pass 等)的地方,加入 lua 處理邏輯:
NGINXlocation ~ \.php$ {
access_by_lua_file /your/path/to/request-compress.lua;
fastcgi_pass 127.0.0.1:9000;
#... ...
}
這個配置目的是讓這個 lua 邏輯工作在 Nginx 的 Access 階段。
到此為止,基於 OpenResty 的解壓方案已經寫好。它能否按預期正常工作呢?我決定先放一放,後面再驗證。
Node.js
Node.js 內建了對 Zlib 庫的封裝。使用 Node.js 也可以輕鬆應對壓縮內容。直接上程式碼:
JSvar http = require('http');
var zlib = require('zlib');
http.createServer(function (req, res) {
var zlibStream;
var encoding = req.headers['content-encoding'];
switch(encoding) {
case 'gzip':
zlibStream = zlib.createGunzip();
break;
case 'deflate':
zlibStream = zlib.createInflate();
break;
case 'deflate-raw':
zlibStream = zlib.createInflateRaw();
break;
}
res.writeHead(200, {'Content-Type': 'text/plain'});
req.pipe(zlibStream).pipe(res);
}).listen(8361, '127.0.0.1');
這段程式碼將請求正文解壓之後,直接做為輸出返回,它可以正常工作,但僅作示意。實際專案中,這些通用邏輯應該放在框架層統一處理,業務層程式碼無需關心。
PHP
PHP 也內建了處理這些壓縮格式的函式,以下是例項程式碼:
PHP$encoding = $_SERVER['HTTP_CONTENT_ENCODING'];
$rawBody = file_get_contents('php://input');
$body = '';
switch($encoding) {
case 'gzip':
$body = gzdecode($rawBody);
break;
case 'deflate':
$body = gzinflate(substr($rawBody, 2, -4)) . PHP_EOL . PHP_EOL;
break;
case 'deflate-raw':
$body = gzinflate($rawBody);
break;
}
echo $body;
可以看到,ZLIB 格式的壓縮資料去掉頭尾,就是 RAW DEFLATE,可以直接用 gzinflate 解壓。跟前面一樣,如果採用 PHP 解壓方案,也應該在框架層統一處理。
小結一下:在 Nginx 統一解壓的好處是無論後端掛接什麼服務,都可以做到無感知,壞處是需要替換為 OpenResty;在 Web 框架中處理更靈活,但不同語言不同專案需要分別處理,效能方面應該也有差別。如何選擇,要看各自實際情況。
壓縮請求正文
瀏覽器
通過 pako 這個 JS 庫,可以在瀏覽器中使用 Zlib 庫的大部分功能。它也能用於 Node.js 環境,但 Node.js 中一般用官方的 Zlib 就可以了。
pako 的瀏覽器版可以在這裡下載,我們只需要壓縮功能,使用 pako_deflate.min.js 即可。這個檔案有 27.3KB,gzip 後 9.1KB,算很小的了。它同時支援 GZIP、ZLIB 和 RAW DEFLATE 三種壓縮格式,如果只保留一種應該還能更小。
下面是使用 pako 庫在瀏覽器中實現壓縮請求正文的示例程式碼:
JSvar rawBody = 'content=test';
var rawLen = rawBody.length;
var bufBody = new Uint8Array(rawLen);
for(var i = 0; i < rawLen; i++) {
bufBody[i] = rawBody.charCodeAt(i);
}
var format = 'gzip'; // gzip | deflate | deflate-raw
var buf;
switch(format) {
case 'gzip':
buf = window.pako.gzip(bufBody);
break;
case 'deflate':
buf = window.pako.deflate(bufBody);
break;
case 'deflate-raw':
buf = window.pako.deflateRaw(bufBody);
break;
}
var xhr = new XMLHttpRequest();
xhr.open('POST', '/node/');
xhr.setRequestHeader('Content-Encoding', format);
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded; charset=UTF-8');
xhr.send(buf);
這段程式碼本身沒什麼好多說的,十分簡單。這裡有一個最終的 DEMO 頁面,大家可以實際體驗下。在這個 DEMO 中,針對 Zepto 原始碼壓縮後能夠減少 70% 的體積,十分可觀。這個 DEMO 服務端使用的是前面介紹的 Node.js 解壓方案。
Gzip + Curl
使用 Curl 命令,可以將 Gzip 程式生成的 GZIP 壓縮資料 POST 給服務端。例如:
BASHecho "content=Web%20%E5%AE%89%E5%85%A8%E6%98%AF%E4%B8%80%E9%A1%B9%E7%B3%BB%E7%BB%9F%E5%B7%A5%E7%A8%8B%EF%BC%8C%E4%BB%BB%E4%BD%95%E7%BB%86%E5%BE%AE%E7%96%8F%E5%BF%BD%E9%83%BD%E5%8F%AF%E8%83%BD%E5%AF%BC%E8%87%B4%E6%95%B4%E4%B8%AA%E5%AE%89%E5%85%A8%E5%A0%A1%E5%9E%92%E5%9C%9F%E5%B4%A9%E7%93%A6%E8%A7%A3%E3%80%82" | gzip -c > data.txt.gz
curl -v --data-binary @data.txt.gz -H'Content-Type: application/x-www-form-urlencoded; charset=UTF-8' -H'Content-Encoding: gzip' -X POST https://qgy18.com/node/
通過下圖可以清晰的看到整個資料傳輸過程:
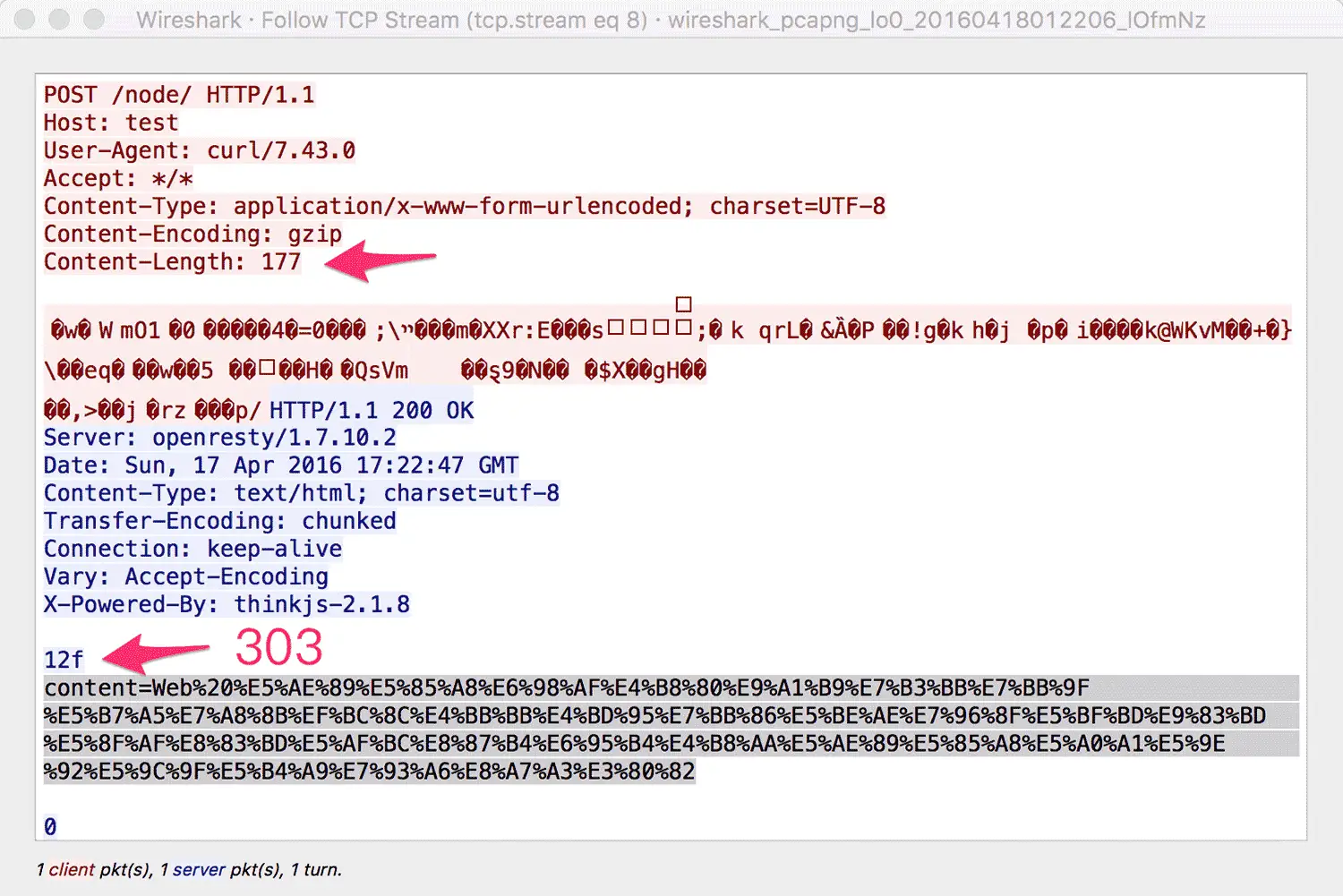
本文到此馬上就要結束了。對於本文沒有提及的移動 APP,如果有 POST 大資料的場景,也可以使用本方案,以較小的成本換取使用者流量的節省和網路效能的提升。更妙的是這個方案具有良好的相容性(不支援請求正文壓縮的老版本 APP,自然不會在請求頭帶上 Content-Encoding 欄位,直接會跳過服務端的解壓邏輯),非常值得嘗試!