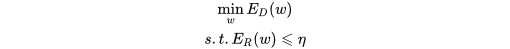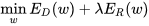機器學習中L1L2規則化詳解(先驗及稀疏性解釋)
(作者:陳玓玏)
1、 為什麼要正則化?
知乎上有個兄弟說得對(https://www.zhihu.com/question/20924039 這個問題下Stark Einstein的回答),不應該說是正則化,應該說是規則化,也就是說,我們原來是在完全沒有任何先驗知識的情況下進行的訓練,那訓練出來的結果有可能會“過”,你不知道哪個特徵會有用,於是你找了很多特徵,儘可能精確地去擬合你的訓練資料,結果用上了一些其實不重要的特徵,這些特徵在訓練集中表現不錯,但是在測試集中卻不重要,也就是說這些特徵本身就不具備普適性,但你還學習到它了,在這種不具備普遍性的情況下學習到它,自然會影響你測試集的效果,自然就做不出泛化能力強的模型,就產生了過擬合。當然了,並不是只要引數一多就會過擬合,還要看你的樣本量。
規則化的另外一個意義是減少不必要的特徵,只剩下那些普遍成立的特徵,既然每個特徵都對應一個引數,那麼我們減少特徵或者降低特徵權重,就是讓引數等於0或接近0。最原始的想法就是用L0範數,因為它表示向量中非零元素的個數,只要把這個控制在一定範圍內,模型複雜度就控制住了。但L0不好求解,因為是NP完全問題,因此求意義接近的L1範數,表示所有引數的絕對值之和。但是L1範數會把一些特徵丟棄,但是大家只想讓它們在最小化結構風險的過程中儘可能小,所以就有了L2範數來進行規則化。
具體的問題我們接下來慢慢討論。
2、 為什麼說正則相當於加入先驗?
那如果我們有了先驗知識呢?規則化就是幫助我們加入先驗知識到學習過程中的。先說個結論:L1正則就是加入拉普拉斯先驗,L2正則就是加入高斯先驗,這個先驗是針對引數來說的。
下面的內容是從知乎上(https://www.zhihu.com/question/23536142 這個回答下Charles Xiao和Thaurun的回答)學到的,算是自己做的筆記,這些博主的部落格也有一些很棒的其他文章,可以學習一下~
規則化=加入先驗資訊這個是從貝葉斯的角度來看的,如果我們考慮一個線性模型,那麼其模型公式為:
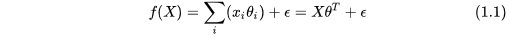
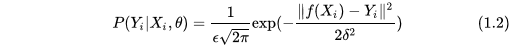
假設樣本之間是獨立的,那麼我們最後得到的整體預測正確的概率為:
 根據極大似然估計,我們最後能夠儘可能多地預測正確資料,其概率值和引數有關,那麼我們的目標就是找到使式(1.3)概率最大的值,對其取log也成立:
根據極大似然估計,我們最後能夠儘可能多地預測正確資料,其概率值和引數有關,那麼我們的目標就是找到使式(1.3)概率最大的值,對其取log也成立:
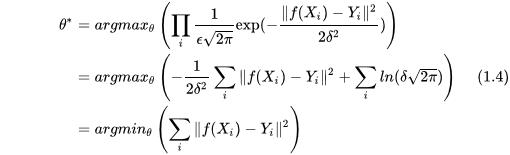
到了這一步我們可以看出來,正則就是在最後一個等式的結果上加了一項,對L1規則化往回推導,那就是在似然函式上乘上以下這一項:
L2規則化往回推導,就是在似然函式乘上這一項:
這兩項的形式正好一個接近拉普拉斯分佈,一個接近高斯分佈。下面還是順著來看吧。在不考慮的分佈時,我們認為它的分佈是個常數,既然現在知道了,那麼極大似然估計的最大化後驗概率中必然要乘上這一項:

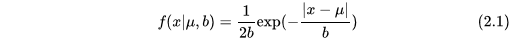
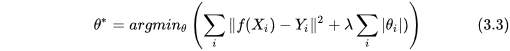
3、 為什麼L1稀疏L2平滑?
從上面兩個概率公式中能看出些苗頭,首先,拉普拉斯分佈圖是這樣的:


這個從導數上能窺得一二。先寫出L1正則的結構風險導數,L1表示加了L1正則後的結構化風險,L表示規則化以前的結構化風險:
什麼時候會是我們要找的極小值點呢?看以下這幅圖:

那麼L2正則呢?先看看導數: 很容易發現,當的時候,L2的導數就是原來L的導數,所以原來的極小值不在的位置,那麼L2規則化之後的也不會在這個位置。這就解釋了為什麼L1稀疏而L2不稀疏。
4、 直觀解釋
下面要放那張被詬病面試時被問死了的圖了,如下:

具體分析時,為什麼可以把結構化風險函式拆分成兩部分?因為在優化裡