
Nginx+keepalived雙機熱備(主從模式)
負載均衡技術對於一個網站尤其是大型網站的web伺服器叢集來說是至關重要的!做好負載均衡架構,可以實現故障轉移和高可用環境,避免單點故障,保證網站健康持續執行。 關於負載均衡介紹,可以參考:linux負載均衡總結性說明(四層負載/七層負載)
由於業務擴充套件,網站的訪問量不斷加大,負載越來越高。現需要在web前端放置nginx負載均衡,同時結合keepalived對前端nginx實現HA高可用。 1)nginx程序基於Master+Slave(worker)多程序模型,自身具有非常穩定的子程序管理功能。在Master程序分配模式下,Master程序永遠不進行業務處理,只是進行任務分發,從而達到Master程序的存活高可靠性,Slave(worker)程序所有的業務訊號都 由主程序發出,Slave(worker)程序所有的超時任務都會被Master中止,屬於非阻塞式任務模型。 2)Keepalived是Linux下面實現VRRP備份路由的高可靠性執行件。基於Keepalived設計的服務模式能夠真正做到主伺服器和備份伺服器故障時IP瞬間無縫交接。二者結合,可以構架出比較穩定的軟體LB方案。
Keepalived介紹: Keepalived是一個基於VRRP協議來實現的服務高可用方案,可以利用其來避免IP單點故障,類似的工具還有heartbeat、corosync、pacemaker。但是它一般不會單獨出現,而是與其它負載均衡技術(如lvs、haproxy、nginx)一起工作來達到叢集的高可用。
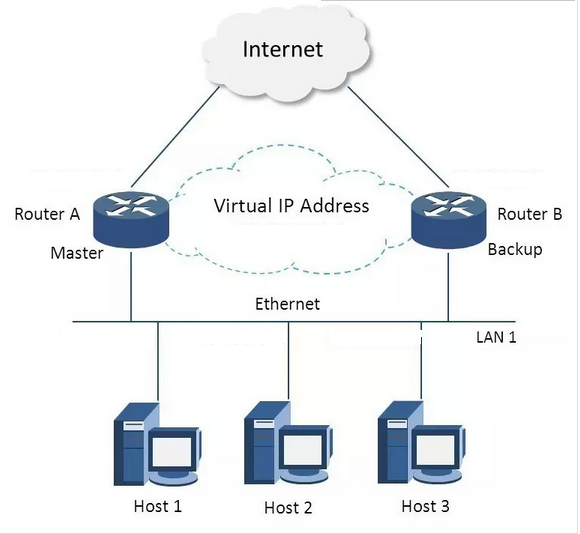
VRRP協議: VRRP全稱 Virtual Router Redundancy Protocol,即 虛擬路由冗餘協議。可以認為它是實現路由器高可用的容錯協議,即將N臺提供相同功能的路由器組成一個路由器組(Router Group),這個組裡面有一個master和多個backup,但在外界看來就像一臺一樣,構成虛擬路由器,擁有一個虛擬IP(vip,也就是路由器所在區域網內其他機器的預設路由),佔有這個IP的master實際負責ARP相應和轉發IP資料包,組中的其它路由器作為備份的角色處於待命狀態。master會發組播訊息,當backup在超時時間內收不到vrrp包時就認為master宕掉了,這時就需要根據VRRP的優先順序來選舉一個backup當master,保證路由器的高可用。
在VRRP協議實現裡,虛擬路由器使用 00-00-5E-00-01-XX 作為虛擬MAC地址,XX就是唯一的 VRID (Virtual Router IDentifier),這個地址同一時間只有一個物理路由器佔用。在虛擬路由器裡面的物理路由器組裡面通過多播IP地址 224.0.0.18 來定時傳送通告訊息。每個Router都有一個 1-255 之間的優先級別,級別最高的(highest priority)將成為主控(master)路由器。通過降低master的優先權可以讓處於backup狀態的路由器搶佔(pro-empt)主路由器的狀態,兩個backup優先順序相同的IP地址較大者為master,接管虛擬IP。
keepalived與heartbeat/corosync等比較: Heartbeat、Corosync、Keepalived這三個叢集元件我們到底選哪個好呢? 首先要說明的是,Heartbeat、Corosync是屬於同一型別,Keepalived與Heartbeat、Corosync,根本不是同一型別的。 Keepalived使用的vrrp協議方式,虛擬路由冗餘協議 (Virtual Router Redundancy Protocol,簡稱VRRP); Heartbeat或Corosync是基於主機或網路服務的高可用方式; 簡單的說就是,Keepalived的目的是模擬路由器的高可用,Heartbeat或Corosync的目的是實現Service的高可用。 所以一般Keepalived是實現前端高可用,常用的前端高可用的組合有,就是我們常見的LVS+Keepalived、Nginx+Keepalived、HAproxy+Keepalived。而Heartbeat或Corosync是實現服務的高可用,常見的組合有Heartbeat v3(Corosync)+Pacemaker+NFS+Httpd 實現Web伺服器的高可用、Heartbeat v3(Corosync)+Pacemaker+NFS+MySQL 實現MySQL伺服器的高可用。總結一下,Keepalived中實現輕量級的高可用,一般用於前端高可用,且不需要共享儲存,一般常用於兩個節點的高可用。而Heartbeat(或Corosync)一般用於服務的高可用,且需要共享儲存,一般用於多節點的高可用。這個問題我們說明白了。
那heartbaet與corosync又應該選擇哪個好? 一般用corosync,因為corosync的執行機制更優於heartbeat,就連從heartbeat分離出來的pacemaker都說在以後的開發當中更傾向於corosync,所以現在corosync+pacemaker是最佳組合。
雙機高可用一般是通過虛擬IP(飄移IP)方法來實現的,基於Linux/Unix的IP別名技術。 雙機高可用方法目前分為兩種: 1)雙機主從模式:即前端使用兩臺伺服器,一臺主伺服器和一臺熱備伺服器,正常情況下,主伺服器繫結一個公網虛擬IP,提供負載均衡服務,熱備伺服器處於空閒狀態;當主伺服器發生故障時,熱備伺服器接管主伺服器的公網虛擬IP,提供負載均衡服務;但是熱備伺服器在主機器不出現故障的時候,永遠處於浪費狀態,對於伺服器不多的網站,該方案不經濟實惠。 2)雙機主主模式:即前端使用兩臺負載均衡伺服器,互為主備,且都處於活動狀態,同時各自繫結一個公網虛擬IP,提供負載均衡服務;當其中一臺發生故障時,另一臺接管發生故障伺服器的公網虛擬IP(這時由非故障機器一臺負擔所有的請求)。這種方案,經濟實惠,非常適合於當前架構環境。
今天在此分享下Nginx+keepalived實現高可用負載均衡的主從模式的操作記錄:
keepalived可以認為是VRRP協議在Linux上的實現,主要有三個模組,分別是core、check和vrrp。
core模組為keepalived的核心,負責主程序的啟動、維護以及全域性配置檔案的載入和解析。
check負責健康檢查,包括常見的各種檢查方式。
vrrp模組是來實現VRRP協議的。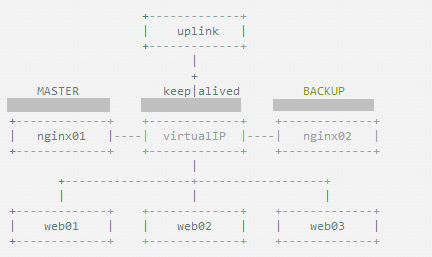
一、環境說明: 作業系統:centos6.8,64位 master機器(master-node):103.110.98.14/192.168.1.14 slave機器(slave-node):103.110.98.24/192.168.1.24 公用的虛擬IP(VIP):103.110.98.20 //負載均衡器上配置的域名都解析到這個VIP上
應用環境如下:

二、環境安裝 安裝nginx和keepalive服務(master-node和slave-node兩臺伺服器上的安裝操作完全一樣)。 安裝依賴 [[email protected] ~]# yum -y install gcc pcre-devel zlib-devel openssl-devel 下載(百度雲盤下載地址:https://pan.baidu.com/s/1ckTOKI 提取祕鑰:gi8i) [[email protected] ~]# cd /usr/local/src/ [[email protected] src]# wget http://nginx.org/download/nginx-1.9.7.tar.gz [[email protected] src]# wget http://www.keepalived.org/software/keepalived-1.3.2.tar.gz 安裝nginx [[email protected] src]# tar -zvxf nginx-1.9.7.tar.gz [[email protected] src]# cd nginx-1.9.7 新增www使用者,其中-M引數表示不新增使用者家目錄,-s引數表示指定shell型別 [[email protected] nginx-1.9.7]# useradd www -M -s /sbin/nologin [[email protected] nginx-1.9.7]# vim auto/cc/gcc #將這句註釋掉 取消Debug編譯模式 大概在179行 #CFLAGS="$CFLAGS -g" [[email protected] nginx-1.9.7]# ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_ssl_module --with-http_flv_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre [[email protected] nginx-1.9.7]# make && make install 安裝keepalived [[email protected] src]# tar -zvxf keepalived-1.3.2.tar.gz [[email protected] src]# cd keepalived-1.3.2 [[email protected] keepalived-1.3.2]# ./configure [[email protected] keepalived-1.3.2]# make && make install [[email protected] keepalived-1.3.2]# cp /usr/local/src/keepalived-1.3.2/keepalived/etc/init.d/keepalived /etc/rc.d/init.d/ [[email protected] keepalived-1.3.2]# cp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/ [[email protected] keepalived-1.3.2]# mkdir /etc/keepalived [[email protected] keepalived-1.3.2]# cp /usr/local/etc/keepalived/keepalived.conf /etc/keepalived/ [[email protected] keepalived-1.3.2]# cp /usr/local/sbin/keepalived /usr/sbin/ 將nginx和keepalive服務加入開機啟動服務 [[email protected] keepalived-1.3.2]# echo "/usr/local/nginx/sbin/nginx" >> /etc/rc.local [[email protected] keepalived-1.3.2]# echo "/etc/init.d/keepalived start" >> /etc/rc.local
三、配置服務
先關閉SElinux、配置防火牆 (master和slave兩臺負載均衡機都要做) [[email protected] ~]# vim /etc/sysconfig/selinux #SELINUX=enforcing #註釋掉 #SELINUXTYPE=targeted #註釋掉 SELINUX=disabled #增加 [[email protected] ~]# setenforce 0 #使配置立即生效
[[email protected] ~]# vim /etc/sysconfig/iptables ....... -A INPUT -s 103.110.98.0/24 -d 224.0.0.18 -j ACCEPT #允許組播地址通訊 -A INPUT -s 192.168.1.0/24 -d 224.0.0.18 -j ACCEPT -A INPUT -s 103.110.98.0/24 -p vrrp -j ACCEPT #允許 VRRP(虛擬路由器冗餘協)通訊 -A INPUT -s 192.168.1.0/24 -p vrrp -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT #開通80埠訪問
[[email protected] ~]# /etc/init.d/iptables restart #重啟防火牆使配置生效
1.配置nginx master-node和slave-node兩臺伺服器的nginx的配置完全一樣,主要是配置/usr/local/nginx/conf/nginx.conf的http,當然也可以配置vhost虛擬主機目錄,然後配置vhost下的比如LB.conf檔案。 其中: 多域名指向是通過虛擬主機(配置http下面的server)實現; 同一域名的不同虛擬目錄通過每個server下面的不同location實現; 到後端的伺服器在vhost/LB.conf下面配置upstream,然後在server或location中通過proxy_pass引用。 要實現前面規劃的接入方式,LB.conf的配置如下(新增proxy_cache_path和proxy_temp_path這兩行,表示開啟nginx的快取功能):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
|
[[email protected] ~]# mkdir /usr/local/nginx/conf/vhosts [[email protected] ~]# mkdir /var/www/cache [[email protected] ~]# ulimit 65535
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 |
|
驗證方法(保證從負載均衡器本機到後端真實伺服器之間能正常通訊): 1)首先在本機用IP訪問上面LB.cong中配置的各個後端真實伺服器的url 2)然後在本機用域名和路徑訪問上面LB.cong中配置的各個後端真實伺服器的域名/虛擬路徑
---------------------------------------------------------------------------------------------------------------------------- 後端應用伺服器的nginx配置,這裡選擇192.168.1.108作為例子進行說明 由於這裡的192.168.1.108機器是openstack的虛擬機器,沒有外網ip,不能解析域名。 所以在server_name處也將ip加上,使得用ip也可以訪問。 [[email protected] ~]# cat /usr/local/nginx/conf/vhosts/svn.conf server { listen 80; #server_name dev.wangshibo.com; server_name dev.wangshibo.com 192.168.1.108;
access_log /usr/local/nginx/logs/dev.wangshibo-access.log main; error_log /usr/local/nginx/logs/dev.wangshibo-error.log;
location / { root /var/www/html; index index.html index.php index.htm; } }
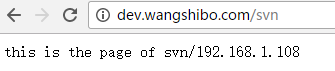
[[email protected] ~]# ll /var/www/html/ drwxr-xr-x. 2 www www 4096 Dec 7 01:46 submin drwxr-xr-x. 2 www www 4096 Dec 7 01:45 svn [[email protected] ~]# cat /var/www/html/svn/index.html this is the page of svn/192.168.1.108 [[email protected] ~]# cat /var/www/html/submin/index.html this is the page of submin/192.168.1.108
[[email protected] ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.1.108 dev.wangshibo.com
[[email protected] ~]# curl http://dev.wangshibo.com //由於是內網機器不能聯網,亦不能解析域名。所以用域名訪問沒有反應。只能用ip訪問 [[email protected] vhosts]# curl http://192.168.1.108 this is 192.168.1.108 page!!! [[email protected] vhosts]# curl http://192.168.1.108/svn/ //最後一個/符號要加上,否則訪問不了。 this is the page of svn/192.168.1.108 [[email protected] vhosts]# curl http://192.168.1.108/submin/ this is the page of submin/192.168.1.108 ----------------------------------------------------------------------------------------------------------------------------
然後在master-node和slave-node兩臺負載機器上進行測試(iptables防火牆要開通80埠): [[email protected] ~]# curl http://192.168.1.108/svn/ this is the page of svn/192.168.1.108 [[email protected] ~]# curl http://192.168.1.108/submin/ this is the page of submin/192.168.1.108
瀏覽器訪問: 在本機host繫結dev.wangshibo.com,如下,即繫結到master和slave機器的公網ip上測試是否能正常訪問(nginx+keepalive環境正式完成後,域名解析到的真正地址是VIP地址) 103.110.98.14 dev.wangshibo.com 103.110.98.24 dev.wangshibo.com

2.keepalived配置 1)master-node負載機上的keepalived配置(sendmail部署可以參考:linux下sendmail郵件系統安裝操作記錄) [[email protected] ~]# cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak [[email protected] ~]# vim /etc/keepalived/keepalived.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
2)slave-node負載機上的keepalived配置 [[email protected] ~]# cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak [[email protected] ~]# vim /etc/keepalived/keepalived.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
|
讓keepalived監控NginX的狀態: 1)經過前面的配置,如果master主伺服器的keepalived停止服務,slave從伺服器會自動接管VIP對外服務; 一旦主伺服器的keepalived恢復,會重新接管VIP。 但這並不是我們需要的,我們需要的是當NginX停止服務的時候能夠自動切換。 2)keepalived支援配置監控指令碼,我們可以通過指令碼監控NginX的狀態,如果狀態不正常則進行一系列的操作,最終仍不能恢復NginX則殺掉keepalived,使得從伺服器能夠接管服務。
如何監控NginX的狀態 最簡單的做法是監控NginX程序,更靠譜的做法是檢查NginX埠,最靠譜的做法是檢查多個url能否獲取到頁面。
注意:這裡要提示一下keepalived.conf中vrrp_script配置區的script一般有2種寫法: 1)通過指令碼執行的返回結果,改變優先順序,keepalived繼續傳送通告訊息,backup比較優先順序再決定。這是直接監控Nginx程序的方式。 2)腳本里面檢測到異常,直接關閉keepalived程序,backup機器接收不到advertisement會搶佔IP。這是檢查NginX埠的方式。 上文script配置部分,"killall -0 nginx"屬於第1種情況,"/opt/chk_nginx.sh" 屬於第2種情況。個人更傾向於通過shell指令碼判斷,但有異常時exit 1,正常退出exit 0,然後keepalived根據動態調整的 vrrp_instance 優先順序選舉決定是否搶佔VIP: 如果指令碼執行結果為0,並且weight配置的值大於0,則優先順序相應的增加 如果指令碼執行結果非0,並且weight配置的值小於0,則優先順序相應的減少 其他情況,原本配置的優先順序不變,即配置檔案中priority對應的值。
提示: 優先順序不會不斷的提高或者降低 可以編寫多個檢測指令碼併為每個檢測指令碼設定不同的weight(在配置中列出就行) 不管提高優先順序還是降低優先順序,最終優先順序的範圍是在[1,254],不會出現優先順序小於等於0或者優先順序大於等於255的情況 在MASTER節點的 vrrp_instance 中 配置 nopreempt ,當它異常恢復後,即使它 prio 更高也不會搶佔,這樣可以避免正常情況下做無謂的切換 以上可以做到利用指令碼檢測業務程序的狀態,並動態調整優先順序從而實現主備切換。
另外:在預設的keepalive.conf裡面還有 virtual_server,real_server 這樣的配置,我們這用不到,它是為lvs準備的。
如何嘗試恢復服務 由於keepalived只檢測本機和他機keepalived是否正常並實現VIP的漂移,而如果本機nginx出現故障不會則不會漂移VIP。 所以編寫指令碼來判斷本機nginx是否正常,如果發現NginX不正常,重啟之。等待3秒再次校驗,仍然失敗則不再嘗試,關閉keepalived,其他主機此時會接管VIP;
根據上述策略很容易寫出監控指令碼。此指令碼必須在keepalived服務執行的前提下才有效!如果在keepalived服務先關閉的情況下,那麼nginx服務關閉後就不能實現自啟動了。 該指令碼檢測ngnix的執行狀態,並在nginx程序不存在時嘗試重新啟動ngnix,如果啟動失敗則停止keepalived,準備讓其它機器接管。 監控指令碼如下(master和slave都要有這個監控指令碼): [[email protected] ~]# vim /opt/chk_nginx.sh
|
1 2 3 4 5 6 7 8 9 10 |
|
[r[email protected] ~]# chmod 755 /opt/chk_nginx.sh [[email protected] ~]# sh /opt/chk_nginx.sh 80/tcp open http
此架構需考慮的問題 1)master沒掛,則master佔有vip且nginx執行在master上 2)master掛了,則slave搶佔vip且在slave上執行nginx服務 3)如果master上的nginx服務掛了,則nginx會自動重啟,重啟失敗後會自動關閉keepalived,這樣vip資源也會轉移到slave上。 4)檢測後端伺服器的健康狀態 5)master和slave兩邊都開啟nginx服務,無論master還是slave,當其中的一個keepalived服務停止後,vip都會漂移到keepalived服務還在的節點上; 如果要想使nginx服務掛了,vip也漂移到另一個節點,則必須用指令碼或者在配置檔案裡面用shell命令來控制。(nginx服務宕停後會自動啟動,啟動失敗後會強制關閉keepalived,從而致使vip資源漂移到另一臺機器上)
最後驗證(將配置的後端應用域名都解析到VIP地址上):關閉主伺服器上的keepalived或nginx,vip都會自動飄到從伺服器上。驗證keepalived服務故障情況: 1)先後在master、slave伺服器上啟動nginx和keepalived,保證這兩個服務都正常開啟: [[email protected] ~]# /usr/local/nginx/sbin/nginx [[email protected] ~]# /etc/init.d/keepalived start [[email protected] ~]# /usr/local/nginx/sbin/nginx [[email protected] ~]# /etc/init.d/keepalived start 2)在主伺服器上檢視是否已經綁定了虛擬IP: [[email protected] ~]# ip addr ....... 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000 link/ether 44:a8:42:17:3d:dd brd ff:ff:ff:ff:ff:ff inet 103.110.98.14/26 brd 103.10.86.63 scope global em1 valid_lft forever preferred_lft forever inet 103.110.98.20/32 scope global em1 valid_lft forever preferred_lft forever inet 103.110.98.20/26 brd 103.10.86.63 scope global secondary em1:0 valid_lft forever preferred_lft forever inet6 fe80::46a8:42ff:fe17:3ddd/64 scope link valid_lft forever preferred_lft forever ...... 3)停止主伺服器上的keepalived: [[email protected] ~]# /etc/init.d/keepalived stop Stopping keepalived (via systemctl): [ OK ] [[email protected] ~]# /etc/init.d/keepalived status [[email protected] ~]# ps -ef|grep keepalived root 26952 24348 0 17:49 pts/0 00:00:00 grep --color=auto keepalived [[email protected] ~]# 4)然後在從伺服器上檢視,發現已經接管了VIP: [[email protected] ~]# ip addr ....... 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000 link/ether 44:a8:42:17:3c:a5 brd ff:ff:ff:ff:ff:ff inet 103.110.98.24/26 brd 103.10.86.63 scope global em1 inet 103.110.98.20/32 scope global em1 inet6 fe80::46a8:42ff:fe17:3ca5/64 scope link valid_lft forever preferred_lft forever ....... 發現master的keepalived服務掛了後,vip資源自動漂移到slave上,並且網站正常訪問,絲毫沒有受到影響! 5)重新啟動主伺服器上的keepalived,發現主伺服器又重新接管了VIP,此時slave機器上的VIP已經不在了。 [[email protected] ~]# /etc/init.d/keepalived start Starting keepalived (via systemctl): [ OK ] [[email protected] ~]# ip addr ....... 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000 link/ether 44:a8:42:17:3d:dd brd ff:ff:ff:ff:ff:ff inet 103.110.98.14/26 brd 103.10.86.63 scope global em1 valid_lft forever preferred_lft forever inet 103.110.98.20/32 scope global em1 valid_lft forever preferred_lft forever inet 103.110.98.20/26 brd 103.10.86.63 scope global secondary em1:0 valid_lft forever preferred_lft forever inet6 fe80::46a8:42ff:fe17:3ddd/64 scope link valid_lft forever preferred_lft forever ......
[[email protected] ~]# ip addr ....... 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000 link/ether 44:a8:42:17:3c:a5 brd ff:ff:ff:ff:ff:ff inet 103.110.98.24/26 brd 103.10.86.63 scope global em1 inet6 fe80::46a8:42ff:fe17:3ca5/64 scope link valid_lft forever preferred_lft forever
接著驗證下nginx服務故障,看看keepalived監控nginx狀態的指令碼是否正常? 如下:手動關閉master機器上的nginx服務,最多2秒鐘後就會自動起來(因為keepalive監控nginx狀態的指令碼執行間隔時間為2秒)。域名訪問幾乎不受影響! [[email protected] ~]# /usr/local/nginx/sbin/nginx -s stop [[email protected] ~]# ps -ef|grep nginx root 28401 24826 0 19:43 pts/1 00:00:00 grep --color=auto nginx [[email protected] ~]# ps -ef|grep nginx root 28871 28870 0 19:47 ? 00:00:00 /bin/sh /opt/chk_nginx.sh root 28875 24826 0 19:47 pts/1 00:00:00 grep --color=auto nginx [[email protected] ~]# ps -ef|grep nginx root 28408 1 0 19:43 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx www 28410 28408 0 19:43 ? 00:00:00 nginx: worker process www 28411 28408 0 19:43 ? 00:00:00 nginx: worker process www 28412 28408 0 19:43 ? 00:00:00 nginx: worker process www 28413 28408 0 19:43 ? 00:00:00 nginx: worker process
最後可以檢視兩臺伺服器上的/var/log/messages,觀察VRRP日誌資訊的vip漂移情況~~~~
------------------------------------------------------------------------------------------------------------------------------------------------- 可能出現的問題:1)VIP繫結失敗 原因可能有: -> iptables開啟後,沒有開放允許VRRP協議通訊的策略(也有可能導致腦裂);可以選擇關閉iptables -> keepalived.conf檔案配置有誤導致,比如interface繫結的裝置錯誤
2)VIP繫結後,外部ping不通 可能的原因是: -> 網路故障,可以檢查下閘道器是否正常; -> 閘道器的arp快取導致,可以進行arp更新,命令是"arping -I 網絡卡名 -c 5 -s VIP 閘道器"
***************當你發現自己的才華撐不起野心時,就請安靜下來學習吧***************