
Hadoop核心元件之MapReduce
MapReduce概述
- Google MapReduce的克隆版本
- 優點:海量資料的離線處理,易開發,易執行
- 缺點:實時流式計算 Hadoop MapReduce是一個軟體框架,用於輕鬆編寫應用程式,以可靠,容錯的方式在大型叢集(數千個節點)的商用硬體上並行處理大量資料(多TB資料集)
MapReduce程式設計模型
思想:分而治之
MapReduce作業通常將輸入資料集拆分為獨立的塊,這些塊由map任務以完全並行的方式處理。框架對map的輸出進行排序,然後輸入到reduce任務。通常,作業的輸入和輸出都儲存在檔案系統中。該框架負責排程任務,監視它們並重新執行失敗的任務。
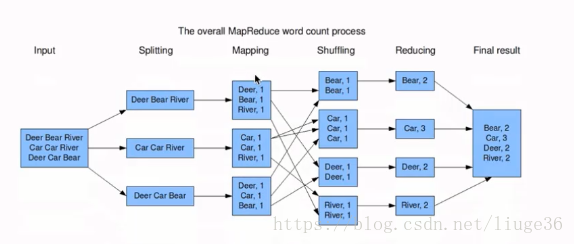
案例;統計一篇文章,各個單詞出現的次數 Input資料輸入 Splitting:拆分資料讀取到各個節點 Mapping:為每一個單詞賦1,不會做合併操作 Shuffling: 重新洗牌(指定規則),這裡把相同單詞發到同一個節點去 Reducing : 統計合併相同單詞的次數
最後把結果寫到一個檔案中去就ok了
相關推薦
Hadoop核心元件之MapReduce
MapReduce概述 Google MapReduce的克隆版本 優點:海量資料的離線處理,易開發,易執行 缺點:實時流式計算 Hadoop MapReduce是一個軟體框架,用於輕鬆編寫應用程式,以可靠,容錯的方式在大型叢集(數千個節點)的商用硬體上並行處理大量資料(多TB資料集) MapReduce
Hadoop基礎 - Hadoop核心元件之HDFS工作原理
HDFS 1.HDFS是Hadoop的儲存元件是一個檔案系統,用於儲存和管理檔案,通過統一的名稱空間(類似於本地檔案系統的目錄樹)。是分散式的,伺服器叢集中各個節點都有自己的角色和職責。HDFS為高吞吐量做了優化,尤其在讀寫大檔案(GB級別或更大)時執行最佳。為了維持高吞吐量,HDFS利用超大資
Hadoop核心元件之HDFS
HDFS:分散式檔案系統 一句話總結 一個檔案先被拆分為多個Block塊(會有Block-ID:方便讀取資料),以及每個Block是有幾個副本的形式儲存 1個檔案會被拆分成多個Block blocksize:128M(Hadoop2.0以後預設的塊大小,可以
hadoop的三大核心元件之MapReaduce
Hadoop的三大核心元件之MapReaduce MapReduce是什麼? MR是一個分散式計算框架,它是Hadoop的一個程式,不會產生程序。 (DATA資料夾是程式碼測試使用的資料,RESULT資料夾是程式碼測試結果) =======================
hadoop基礎概念之Hadoop核心元件
認知和學習Hadoop,我們必須得了解Hadoop的構成,我根據自己的經驗通過Hadoop構件、大資料處理流程,Hadoop核心三個方面進行一下介紹: 一、 Hadoop元件 由圖我們可以看到Hadoop元件由底層的Hadoop核心構件以及上層的Hadoop
Hadoop核心元件—MapReduce詳解
Hadoop 分散式計算框架(MapReduce)。 MapReduce設計理念: - 分散式計算 - 移動計算,而不是移動資料 MapReduce計算框架 步驟1:split split切分Blo
Hadoop體系結構之 Mapreduce
框架 多個 不同 merge 單獨 ref order class task MR框架是由一個單獨運行在主節點上的JobTracker和運行在每個集群從節點上的TaskTracker共同組成。主節點負責調度構成一個作業的所有任務,這些任務分布在不同的不同的從節點上。主節
Hadoop核心組件之MapReduce
數據集 shu 分而治之 put 存儲 ont 監視 計算 cin ## MapReduce概述- Google MapReduce的克隆版本- 優點:海量數據的離線處理,易開發,易運行- 缺點:實時流式計算Hadoop MapReduce是一個軟件框架,用於輕松編寫應用程
Hadoop生態圈之MapReduce
什麼是MapReduce? MapReduce是一個分散式計算框架,以可靠,容錯的方式在大型叢集(數千個節點)上並行處理大量資料(多為TB級資料)。 MapReduce的主要思想是:分久必合 MapReduce的核心思想是:把相同的key分成一組,呼叫一次Reduce方法。 一、
分散式架構核心元件之訊息佇列
訊息佇列已經逐漸成為分散式應用場景、內部通訊、以及秒殺等高併發業務場景的核心手段,它具有低耦合、可靠投遞、廣播、流量控制、最終一致性 等一系列功能。 無論是 RabbitMQ、RocketMQ、ActiveMQ、Kafka還是其它等,都有的一些基本原理、術語、機制等,總結分享出來,希望大家在使用訊息佇列
詳解Hadoop核心架構HDFS+MapReduce+Hbase+Hive
通過對Hadoop分散式計算平臺最核心的分散式檔案系統HDFS、MapReduce處理過程,以及資料倉庫工具Hive和分散式資料庫Hbase的介紹,基本涵蓋了Hadoop分散式平臺的所有技術核心。 通過這一階段的調研總結,從內部機理的角度詳細分析,HDFS、MapRed
Thinking in BigData(八)大資料Hadoop核心架構HDFS+MapReduce+Hbase+Hive內部機理詳解
純乾貨:Hadoop核心架構HDFS+MapReduce+Hbase+Hive內部機理詳解。 通過這一階段的調研總結,從內部機理的角度詳細分析,HDFS、MapReduce、Hbase、Hive是如何執行,以及基於Hadoop資料倉庫的構建和分散式資
hadoop核心元件架構
關鍵性名詞YARN(Yet Another Resource Negotiator):ResourceManager: 通常存在於獨立節點Mastr上,承擔了 JobTracker 的角色,管理整個叢
Hadoop系列--Hadoop基本架構之MapReduce架構
1 MapReduce架構的元件組成 1.1 元件組成 Hadoop的MapReduce架構主要由以下幾個元件組成:Client、JobTracker、TaskTracker、Task。
5. 彤哥說netty系列之Java NIO核心元件之Channel
你好,我是彤哥,本篇是netty系列的第五篇。 簡介 上一章我們一起學習瞭如何使用Java原生NIO實現群聊系統,這章我們一起來看看Java NIO的核心元件之一——Channel。 思維轉變 首先,我想說的最重要的一個點是,學習NIO思維一定要從BIO那種一個連線一個執行緒的模式轉變成多個連線(Chan
6. 彤哥說netty系列之Java NIO核心元件之Buffer
——日拱一卒,不期而至! 你好,我是彤哥,本篇是netty系列的第六篇。 簡介 上一章我們一起學習了Java NIO的核心元件Channel,它可以看作是實體與實體之間的連線,而且需要與Buffer互動,這一章我們就來學習一下Buffer的特性。 概念 Buffer用於與Channel互動時使用,通過上一
7. 彤哥說netty系列之Java NIO核心元件之Selector
——日拱一卒,不期而至! 你好,我是彤哥,本篇是netty系列的第七篇。 簡介 上一章我們一起學習了Java NIO的核心元件Buffer,它通常跟Channel一起使用,但是它們在網路IO中又該如何使用呢,今天我們將一起學習另一個NIO核心元件——Selector,沒有它可以說就幹不起來網路IO。 概念
abp vnext2.0核心元件之模組載入元件原始碼解析
abp vnext是abp官方在abp的基礎之上構建的微服務框架,說實話,看完核心元件原始碼的時候,很興奮,整個框架將元件化的細想運用的很好,真的超級解耦.老版整個框架依賴Castle的問題,vnext對其進行了解耦,支援AutoFac或者使用.Net Core的預設容器.vnext依然沿用EF core為主
abp vnext2.0核心元件之.Net Core預設DI元件切換到AutoFac原始碼解析
老版Abp對Castle的嚴重依賴在vnext中已經得到了解決,vnext中DI容器可以任意更換,為了實現這個功能,底層架構相較於老版abp,可以說是進行了高度重構.當然這得益於.Net Core的DI容器元件本身的優勢.接著abp vnext2.0核心元件之模組載入元件原始碼解析上文,上文中我跳過了DI切換
abp vnext2.0核心元件之DDD元件之實體結構原始碼解析
接著abp vnext2.0核心元件之模組載入元件原始碼解析和abp vnext2.0核心元件之.Net Core預設DI元件切換到AutoFac原始碼解析集合.Net Core3.1,基本環境已經完備,接下去就是構建領域層,vnext整個領域層大致分為聚