
路徑fuzz的一種想法(指令碼試驗掃了一晚上,掃出某大廠商兩個漏洞)
阿新 • • 發佈:2018-12-18
參考了之前的路徑fuzz的工具,例如豬豬俠的工具:https://github.com/ring04h/weakfilescan,這個工具主要就是先爬取網頁的路徑,然後再對每個路徑進行fuzz,這種思路跟以前的路徑fuzz的差別就在於可獲取更多存在的連結進行fuzz;而不單單只是進行對根目錄或者某個路徑進行字典載入。
但上面的工具有一些缺點就是可能會導致一些網址會重複爬取,爬取的連結也不是很全,預設好像是設定3層。
參考了以上的有缺點,也造了一個輪子。我的做法就是先對網站的url連結進行爬取,獲取的連結可以有很多用處,之前主要是用於倒進掃描器進行一些sql注入,url跳轉和命令注入等的掃描。
掃描器的原理基本就是:先對爬取的url進行去重,然後把url連結倒進一個修改過的輪子(https://github.com/Mosuan/FileScan),這個fuzz路徑的掃描器可以對每個掃描的路徑都能掃描,並且是進行多個狀態進行比對。例如 www.abc.com/a/b,掃描的路徑就會有www.abc.com,www.abc.com/a,www.baidu.com/a/b。但爬取的url路徑可能會有重複的情況,例如www.abc.com/a/b/c,這時候也進行一個路徑的去重,把之前掃描過一次的路徑進行標記,下次掃描的時進行狀態的比對,結果主要存在mongodb中。
效果圖:
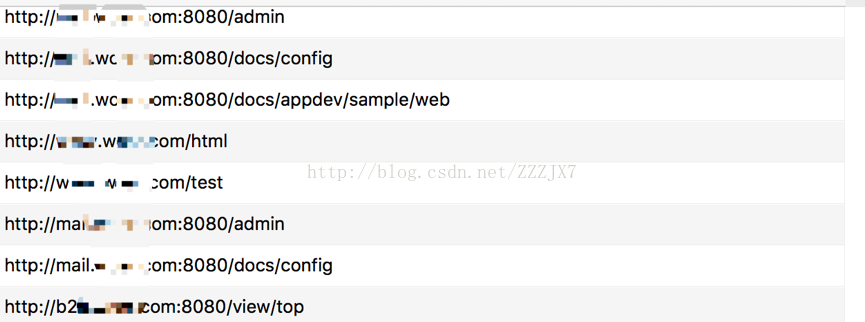
目前存在的情況是由於一些路徑沒有進行規則的匹配,還是存在一點誤報的情況。好東西不是一蹴而就,需要不停地進行優化,這裡分享了一下自己在路徑fuzz上面的看法。
更新:
進行了優化,一是當命中規則時會再一次進行返回包長度的檢驗;二是當命中規則數超過一個伐值,會捨棄這些資料。
這樣誤報率一下子下降,準確率提高了很多。