
AlexNet和VGG學習筆記
AlexNet
2012年,Alex Krizhevsky(Hinton的學生)提出了AlexNet,它可以看做是LeNet的一個更深更寬版本。
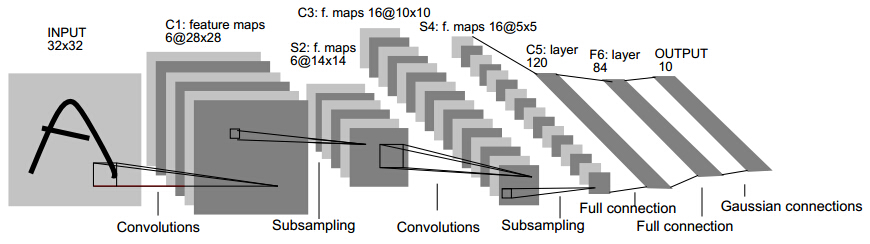
這就是Gradient-Based Learning Applied to Document Recognition論文裡LeNet模型的架構。
LeNet 這個網路雖然很小,但是它包含了卷積神經網路的基本模組:卷積層,池化層,全連結層。是其他深度學習模型的基礎。
但是由於當時的計算機效能(沒有GPU),還有資料樣本的限制等等原因沒有快速發展起來。
而AlexNet在論文ImageNet Classification with Deep Convolutional Neural Networks 中的架構如下:
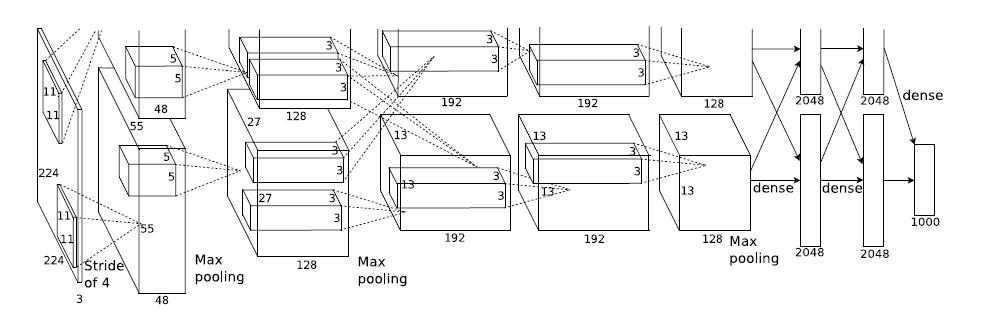
可以看到整體的思想並沒有改變,但是卻引入了ReLU,Dropout和LRN等trick。
整個AlexNet包含了了八個需要訓練的層(不包括池化層),前五層是卷積層,後三層是全連線層。上圖之所以分開兩部分是因為作者使用了兩塊GPU訓練。
AlexNet的每層結構引數如下:
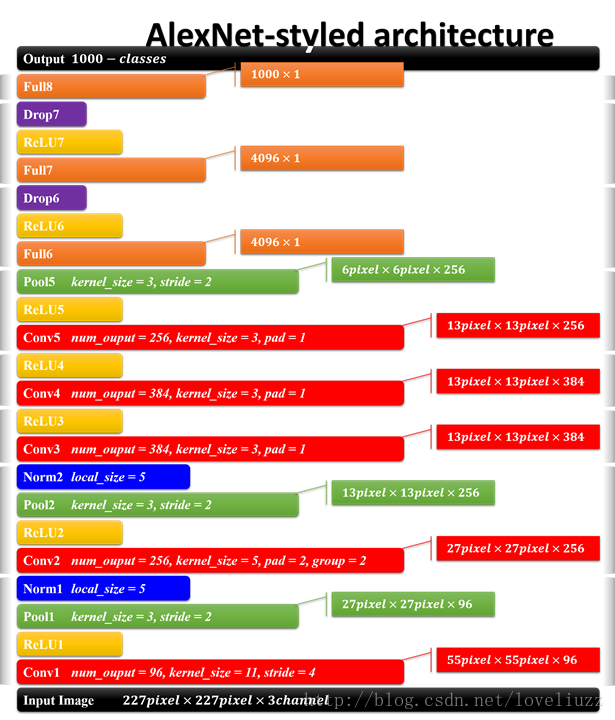
AlexNet主要用到的新技術包括:
1.使用了ReLU啟用函式代替sigmoid啟用函式
Relu函式:f(x)=max(0,x)
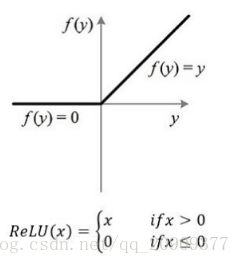
ReLU的有效性體現在兩個方面:
- 克服梯度消失的問題
- 加快訓練速度
而sigmoid會在網路層數增加的時候帶來梯度彌散的問題。
2.使用Dropout隨機忽略一部分神經元
dropout是指在深度學習網路的訓練過程中,對於神經網路單元,按照一定的概率將其暫時從網路中丟棄。
對於dropout為何會有效,這要有兩種觀點:
1.受人類繁衍影響提出了dropout
論文Dropout: A Simple Way to Prevent Neural Networks from Overfitting裡面提到,Dropout類似於性別在生物進化中的角色,物種為了使適應不斷變化的環境,性別的出現有效的阻止了過擬合,即避免環境改變時物種可能面臨的滅亡。dropout也能達到同樣的效果,它迫使一個神經單元和隨機挑選出來的其他神經單元能夠達到好的效果。消除減弱了神經元節點間的聯合適應性,增強了泛化能力。
2.dropout相當於一種ensemble
我們都知道在機器學習之中ensemble的模型能比單一模型更具有泛化效能,因為ensemble模型是多個單一模型的整合,然而對於訓練多個神經網路模型的ensemble會出現耗時和容易過擬合的問題,而dropout是將某些神經元隨機的丟棄,相當於每次訓練都得到一個比定義的模型更窄的模型。

這樣,在訓練的時候我們就似乎能夠獲得多個模型,而在測試的時候我們就不再使用dropout,相當於我們使用了多個模型的ensemble。
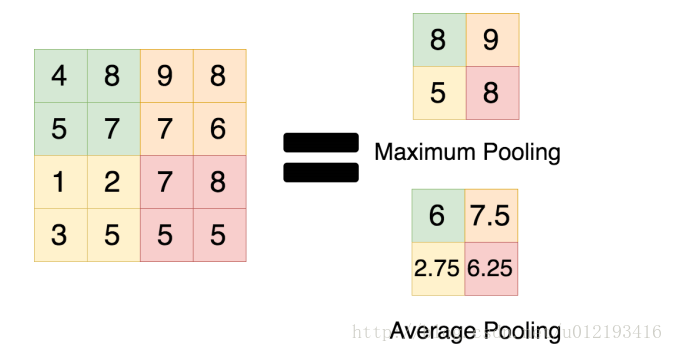
3.使用Max pooling代替Average pooling
此前CNN普遍使用average pooling,這樣會帶來模糊化的效果,並且論文中提出了讓步長小於池化核的尺寸,這樣池化層的輸出之間就會有重疊和覆蓋,提升了特徵的豐富性。max pooling更多的保留紋理資訊。average pooling更強調對整體特徵資訊進行一層下采樣,在減少引數維度的貢獻上更大一點。
4.資料增強 data augmentation
隨機地從原始影象中擷取區域,並水平翻轉,增加了資料量。如果沒有資料增強,CNN很可能會落入過擬合的尷尬局面,加入了資料增強之後可以提高模型的泛化效能。
VGGNet
VGGNet是google和牛津大學一起研發的卷積神經網路。如下是VGGNet個級別的網路結構圖
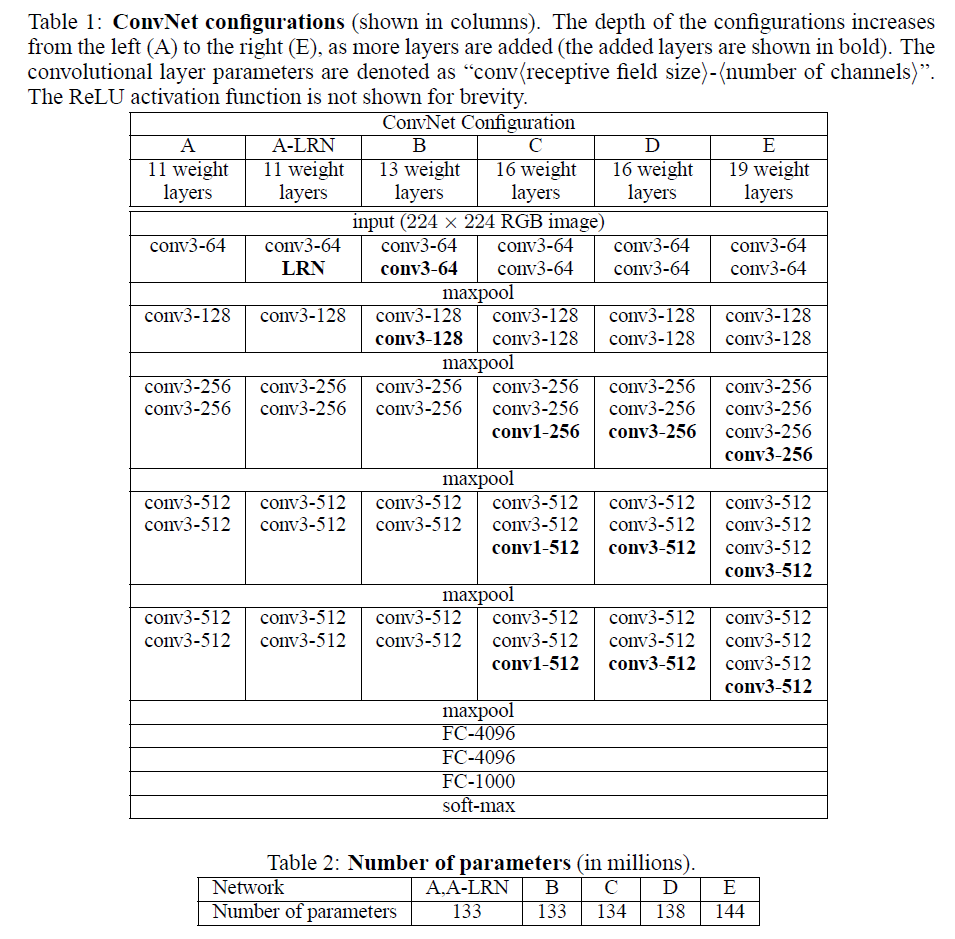
從圖中可以看出,該網路結構有如下的特點:
(1)VGG全部使用3*3卷積核、2*2池化核,不斷加深網路結構來提升效能。 (2)A到E網路變深,引數量沒有增長很多,引數量主要在3個全連線層。 (3)訓練比較耗時的依然是卷積層,因計算量比較大。 (4)VGG有5段卷積,每段有2~3個卷積層,每段尾部用池化來縮小圖片尺寸。 (5)每段內卷積核數一樣,越靠後的段卷積核數越多:64–128–256–512–512。
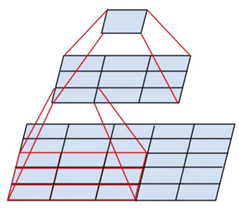
之所以使用3*3的卷積核堆疊起來是因為,這樣可以擴大區域性的感受野的同時又降低了引數的數量,三個3*3的卷積層串聯相當於1個7*7的卷積層,但3個串聯的3*3的卷積層有更少的引數量,有更多的非線性變換(3次ReLU啟用函式),使得CNN對特徵的學習能力更強。
同時在訓練的時候有一個trick就是先訓練層數比較小的的簡單網路,然後再複用這些簡單網路的權重初始化後面幾個複雜的網路,使得訓練的收斂更加快。
而在預測的時候,使用multi-scale的方法,將要預測的資料scale到一個比原來資料更小的尺寸同時預測,然後再最後使用平均的分類結果,提高了預測的準確率和圖片的利用率。btw,訓練的時候也是用了multi-scale的方法做資料增強。
論文作者總結了幾個觀點包括:
1.LRN層的作用不大
2.越深的網路效果越好
3.大一些的卷積核可以學習到更大的空間特徵
在我看來就是一個成本和效率的問題,為了降低訓練的成本而使用了更小一點的卷積核(因為大的卷積核要訓練的引數比較多),至於越深的網路越好,是因為有更多的非線性變換,在高維空間裡可以學到低維空間無法區分的特徵。
AlexNet 和 VGGNet的對比
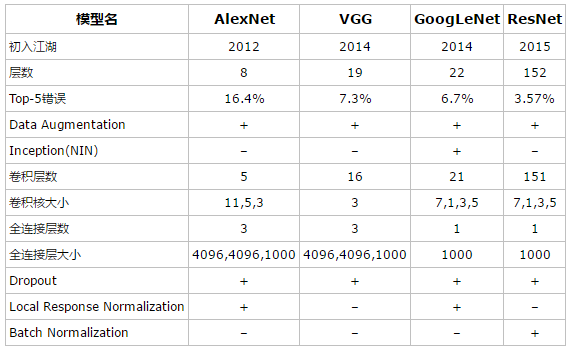
雖然VGGNet比AlexNet的引數要多,但反而需要更少的迭代次數就可以收斂,主要原因是更深的網路和更小的卷積核帶來的隱式的正則化效果。
參考文獻:
1.ImageNet Classification with Deep Convolutional Neural Networks
3.《TensorFlow實戰》