
基於深度學習的人臉識別技術綜述
簡介:人臉識別是計算機視覺研究領域的一個熱點,同時人臉識別的研究領域非常廣泛。因此,本技術綜述限定於:一,在LFW資料集上(Labeled Faces in the Wild)獲得優秀結果的方法; 二,是採用深度學習的方法。
前言
LFW資料集(Labeled Faces in the Wild)是目前用得最多的人臉影象資料庫。該資料庫共13,233幅影象,其中5749個人,其中1680人有兩幅及以上的影象,4069人只有一幅影象。影象為250*250大小的JPEG格式。絕大多數為彩色圖,少數為灰度圖。該資料庫採集的是自然條件下人臉圖片,目的是提高自然條件下人臉識別的精度。該資料集有6中評價標準:
一,Unsupervised; 二,Image-restricted with no outside data; 三,Unrestricted with no outside data; 四,Image-restricted with label-free outside data; 五,Unrestricted with label-free outside data; 六,Unrestricted with labeled outside data。 目前,人工在該資料集上的準確率在0.9427~0.9920。在該資料集的第六種評價標準下(無限制,可以使用外部標註的資料),許多方法已經趕上(超過)人工識別精度,比如face++,DeepID3,FaceNet等。
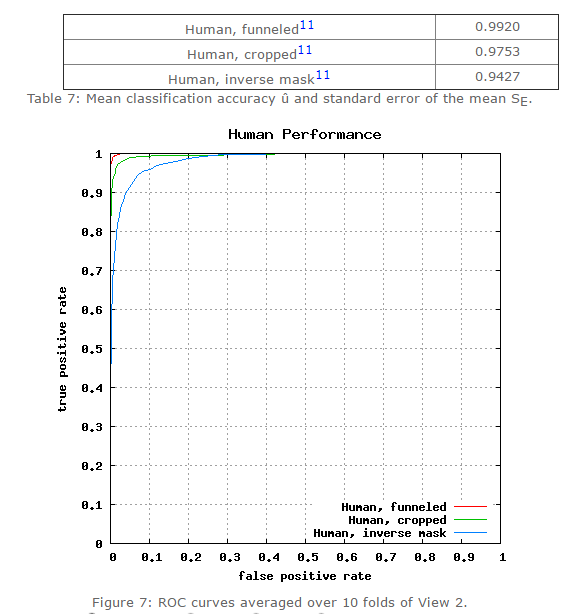
圖一/表一:人類在LFW資料集上的識別精度
表二:第六種標準下,部分模型的識別準確率(詳情參見lfw結果)
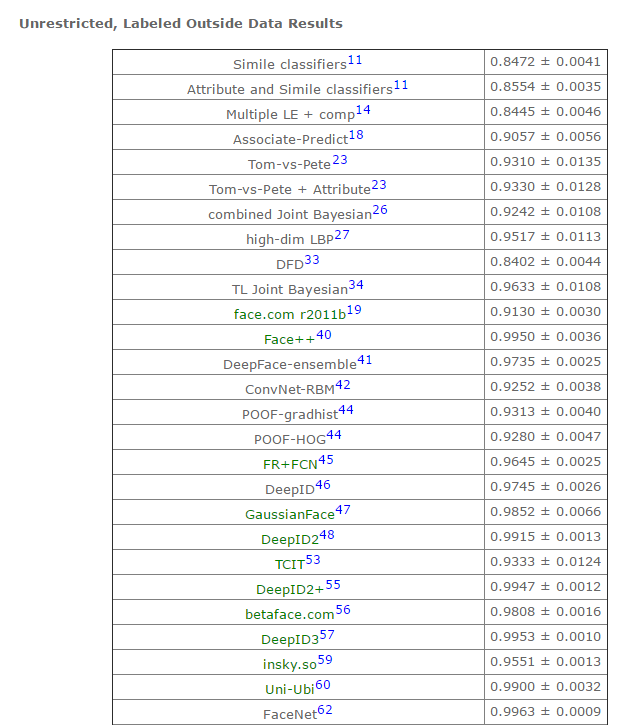
續上表

本文綜述的人臉識別方法包括以下幾個篩選標準:一,在上表中識別精度超過0.95(超過人類的識別準確度);二,公佈了方法(部分結果為商業公司提交,方法並未公佈,比如Tencent-BestImage);三,使用深度學習方法(本人是深度學習的追隨者);三,近兩年的結果。本文綜述的方法包括:1,face++(0.9950 );2,DeepFace(0.9735 );3,FR+FCN(0.9645 );4,DeepID(0.9745 );5,FaceNet(0.9963 );6, baidu的方法(0.9977 );7,pose+shape+expression augmentation(0.9807);8,CNN-3DMM estimation(0.9235 ,準確率沒那麼高,但是值得參考)。人臉識別方法
face++從網路上搜集了5million張人臉圖片用於訓練深度卷積神經網路模型,在LFW資料集上準確率非常高。該篇文章的網路模型很常規(常規深度卷積神經網路模型),但是提出的問題是值得參考的。
問題一:他們的Megvii Face Recognition System經過訓練後,在LFW資料集上達到了0.995的準確率。在真實場景測試中(Chinese ID (CHID)),該系統的假陽性率()非常低。但是,真陽性率僅為0.66,沒有達到真實場景應用要求。其中,年齡差異(包括intra-variation:同一個人,不同年齡照片;以及inter-variation:不同人,不同年齡照片)是影響模型準確率原因之一。而在該測試標準(CHID)下,人類表現的準確率大於0.90.

圖1-1:在CHID中出錯的樣本
問題二:資料採集偏差。基於網路採集的人臉資料集存在偏差。這些偏差表現在:1,個體之間照片數量差異很大;2,大部分採集的照片都是:微笑,化妝,年輕,漂亮的圖片。這些和真實場景中差異較大。因此,儘管系統在LFW資料集上有高準確率,在現實場景中準確率很低。 問題三:模型測試加陽性率非常低,但是現實應用中,人們更關注真陽性率。 問題四:人臉圖片的角度,光線,閉合(開口、閉口)和年齡等差異相互的作用,導致人臉識別系統現實應用準確率很低。 因此,該文章提出未來進一步研究的方向。方向一:從視訊中提取訓練資料。視訊中人臉畫面接近於現實應用場景(變化的角度,光照,表情等);方向二:通過人臉合成方法增加訓練資料。因為單個個體不同的照片很困難(比如,難以蒐集大量的單個個體不同年齡段的照片,可以採用人臉合成的方法(比如3D人臉重建)生成單個個體不同年齡段的照片)。該文章提出的方向在後續方法介紹中均有體現。 2,DeepFace(0.9735 ) 參考文獻:Deepface: Closing the gap to humal-level performance in face verification 2.1 簡介 常規人臉識別流程是:人臉檢測-對齊-表達-分類。本文中,我們通過額外的3d模型改進了人臉對齊的方法。然後,通過基於4million人臉影象(4000個個體)訓練的一個9層的人工神經網路來進行人臉特徵表達。我們的模型在LFW資料集上取得了0.9735的準確率。該文章的亮點有以下幾點:一,基於3d模型的人臉對齊方法;二,大資料訓練的人工神經網路。 2.2 人臉對齊方法 文中使用的人臉對齊方法包括以下幾步:1,通過6個特徵點檢測人臉;2,剪下;3,建立Delaunay triangulation;4,參考標準3d模型;5,將3d模型比對到圖片上;6,進行仿射變形;7,最終生成正面圖像。

圖2-1 人臉對齊的流程
2.3 深度神經網路

圖2-2:深度神經網路
2.4 結果 該模型在LFW資料集上取得了0.9735準確率,在其它資料集比如Social Face Classification (SFC) dataset和YouTube Faces (YTF) dataset也取得了好結果,詳情請參見原文。 3,FR+FCN(0.9645 )
3.1 簡介
自然條件下,因為角度,光線,occlusions(咬合/張口閉口),低解析度等原因,使人臉影象在個體之間有很大的差異,影響到人臉識別的廣泛應用。本文提出了一種新的深度學習模型,可以學習人臉影象看不見的一面。因此,模型可以在保持個體之間的差異的同時,極大的減少單個個體人臉影象(同一人,不同圖片)之間的差異。與當前使用2d環境或者3d資訊來進行人臉重建的方法不同,該方法直接從人臉影象之中學習到影象中的規則觀察體(canonical view,標準正面人臉影象)。作者開發了一種從個體照片中自動選擇/合成canonical-view的方法。在應用方面,該人臉恢復方法已經應用於人臉核實。同時,該方法在LFW資料集上獲得了當前最好成績。該文章的亮點在於:一,新的檢測/選擇canonical-view的方法;二,訓練深度神經網路來重建人臉正面標準圖片(canonical-view)。
3.2 canonical view選擇方法
我們設計了基於矩陣排序和對稱性的人臉正面圖像檢測方法。如圖3-1所示,我們按照以下三個標準來採集個體人臉圖片:一,人臉對稱性(左右臉的差異)進行升序排列;二,影象銳度進行降序排列;三,一和二的組合。

圖3-1 正面人臉影象檢測方法
矩陣為第i個個體的人臉影象矩陣,
為第i個個體所有人臉影象集合,
。正面人臉檢測公式為:
。
3.3 人臉重建
我們通過訓練深度神經網路來進行人臉重建。loss函式為:
i為第i個個體,k為第i個個體的第k張樣本。和Y為訓練影象和目標影象。
如圖3-2所示,深度神經網路包含三層。前兩層後接上了max pooling;最後一層接上了全連線層。於傳統卷積神經網路不同,我們的filters不共享權重(我們認為人臉的不同區域存在不同型別的特徵)。第l層卷積層可以表示為:

圖3-2 深度神經網路
最終,經過訓練的深度神經網路生成的canonical view人臉影象如圖3-3所示。

圖3-3 canonical view人臉影象
4,DeepID(0.9745 )
4.1 簡介 深度學習在人臉識別領域的應用提高了人臉識別準確率。本文中,我們使用了兩種深度神經網路框架(VGG net 和GoogleLeNet)來進行人臉識別。兩種框架ensemble結果在LFW資料集上可以達到0.9745的準確率。文章獲得高準確率主要歸功於大量的訓練資料,文章的亮點僅在於測試了兩種深度卷積神經網路框架。 4.2 深度神經網路框架
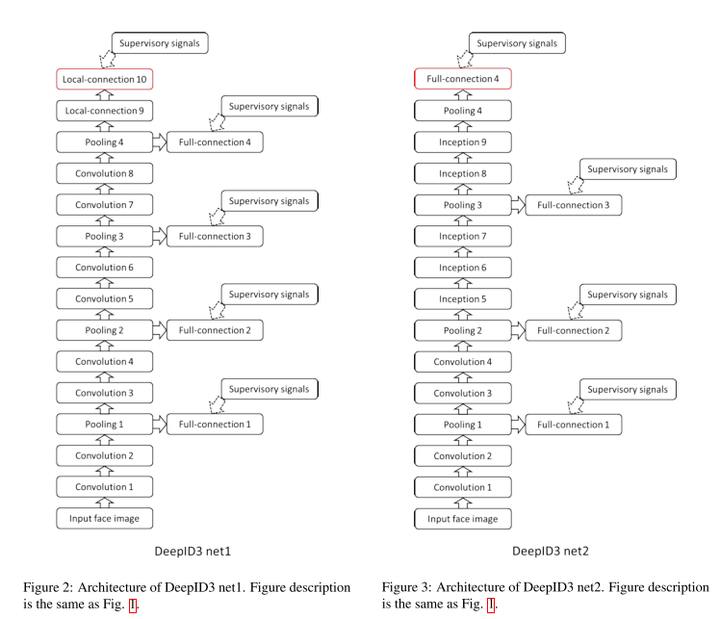
圖4-1 兩種深度卷積神經網路框架
5,FaceNet(0.9963)
參考文獻:FaceNet: A Unified Embedding for Face Recognition and Clustering
5.1 簡介
作者開發了一個新的人臉識別系統:FaceNet,可以直接將人臉影象對映到歐幾里得空間,空間的距離代表了人臉影象的相似性。只要該對映空間生成,人臉識別,驗證和聚類等任務就可以輕鬆完成。該方法是基於深度卷積神經網路,在LFW資料集上,準確率為0.9963,在YouTube Faces DB資料集上,準確率為0.9512。FaceNet的核心是百萬級的訓練資料以及 triplet loss。
5.2 triplet loss
triplet loss是文章的核心,模型將影象x embedding入d-維的歐幾里得空間。我們希望保證某個個體的影象
和該個體的其它影象
距離近,與其它個體的影象
距離遠。如圖5-1所示:
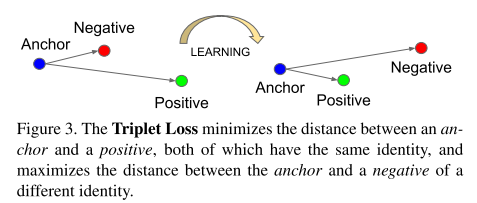
圖5-1 triplet loss示意圖
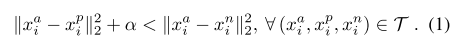
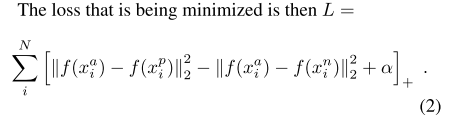
triplets 的選擇對模型的收斂非常重要。如公式1所示,對於,我們我們需要選擇不同個體的圖片
,使
;同時,還需要選擇同一個體不同圖片
,使得
。
5.3 深度卷積神經網路
採用adagrad優化器,使用隨機梯度下降法訓練CNN模型。在cpu叢集上訓練了1000-2000小時。邊界值
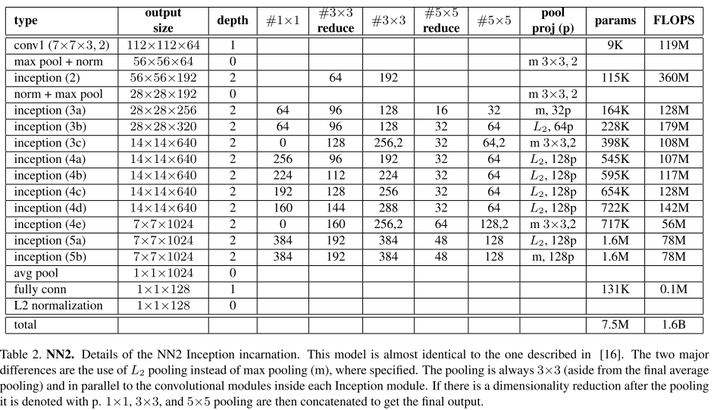
設定為0.2。總共實驗了兩類模型,引數如表5-1和表5-2所示。
表5-1 CNN模型1
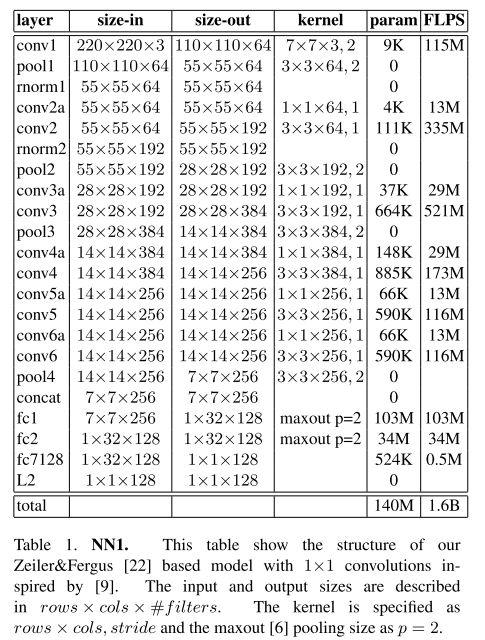
表5-2 CNN模型2
6,baidu的方法 參考文獻:Targeting Ultimate Accuracy : Face Recognition via Deep Embedding 6.1 簡介 本文中,作者提出了一種兩步學習方法,結合mutil-patch deep CNN和deep metric learning,實現臉部特徵提取和識別。通過1.2million(18000個個體)的訓練集訓練,該方法在LFW資料集上取得了0.9977的成績。 6.2 multi-patch deep CNN 人臉不同區域通過深度卷積神經網路分別進行特徵提取。如圖6-1所示。
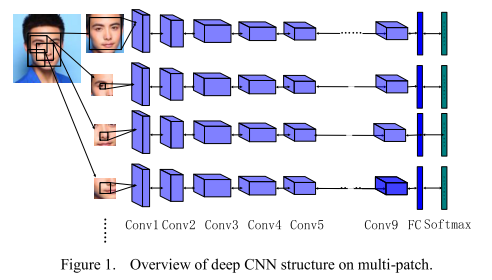
圖6-1 multi-patch示意圖 6.3 deep metric learning 深度卷積神經網路提取的特徵再經過metric learning將維度降低到128維度,如圖7-2所示。
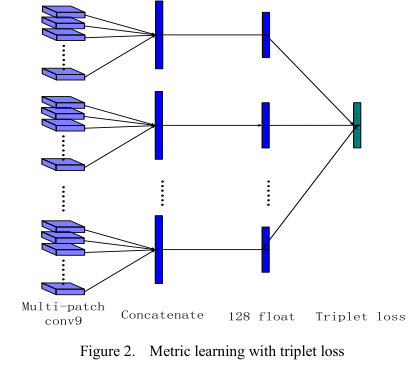
圖6-2 metric learning示意圖 7,pose+shape+expression augmentation(0.9807) 參考文章:Do We Really Need to Collect Millions of Faces for Effective Face Recognition 7.1 簡介 該文章的主要思路是對資料集進行擴增(data augmentation)。CNN深度學習模型,比如face++,DeepID,FaceNet等需要基於百萬級人臉影象的訓練才能達到高精度。而蒐集百萬級人臉資料所耗費的人力,物力,財力是很大的,所以商業公司使用的影象資料庫是不公開的。 本文中,採用了新的人臉資料擴增方法。對現有公共資料庫人臉影象,從pose,shape和expression三個方面合成新的人臉影象,極大的擴增資料量。在LFW和IJB-A資料集上取得了和百萬級人臉資料訓練一樣好的結果。該文章的思路很好,很適合普通研究者。 7.2 pose+shape+expression擴增方法 一,pose(姿態,文章中為人臉角度,即通過3d人臉模型資料庫合成影象看不見的角度,生成新的角度的人臉)。首先,通過人臉特徵點檢測(facial landmark detector),獲取人臉特徵點。根據人臉特徵點和開放的Basel 3D face set資料庫的人臉模板合成3d人臉。如圖7-1所示。

圖7-1 pose(角度)生成示意圖 二,shape(臉型)。首先,通過Basel 3D face獲取10種高質量3d面部掃描資料。再將影象資料與不同3d臉型資料結合,生成同一個人不同臉型的影象。如圖7-2所示:
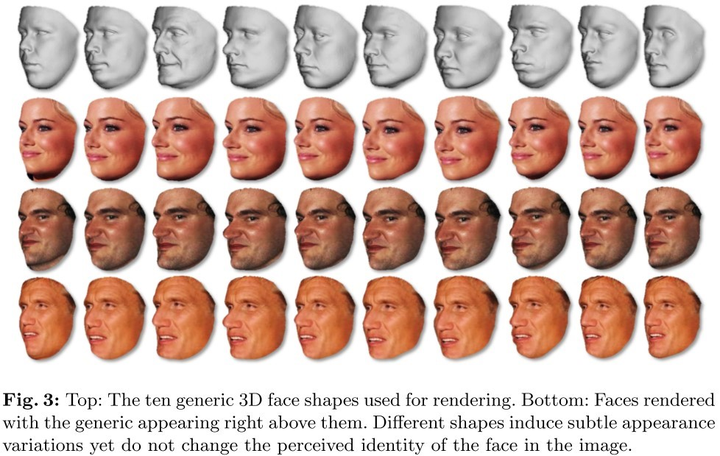
圖7-2 不同臉型生成示意圖 三,expression(表情,本文中,將影象的張嘴表情替換為閉口表情)。採用中性嘴型將影象中的開口表情換位閉口表情。如圖7--3所示。

圖7-3 不同表情(開口/閉口)生成示意圖 7.3 模型及訓練方法 文章模型採用的ILSVRC資料集上預訓練的VGG-19模型。訓練方法是常規梯度下降訓練方法。值得提出的地方是,該文章對測試集也進行了augmentation。 8, CNN-3DMM estimation(0.9235) 參考文獻:
8.1 簡介
當在真實場景中應用3d模擬來增加人臉識別精度,存在兩類問題:要麼3d模擬不穩定,導致同一個個體的3d模擬差異較大;要麼過於泛化,導致大部分合成的圖片都類似。因此,作者研究了一種魯棒的三維可變人臉模型(3D morphable face models (3DMM))生成方法。他們採用了卷積神經網路(CNN)來根據輸入照片來調節三維人臉模型的臉型和紋理引數。該方法可以用來生成大量的標記樣本。該方法在MICC資料集上進行了測試,精確度為state of the art 。與3d-3d人臉比對流程相結合,作者在LFW,YTF和IJB-A資料集上與當前最好成績持平。文章的關鍵點有兩個:一,3D重建模型訓練資料獲取;二,3D重建模型訓練 。
8.2 訓練資料
作者採用了近期發表的多影象3DMM生成方法(M.Piotraschke 2016)。他們在CASIA WebFace資料集上採用該方法生成3DMM。這些3d人臉模型用於訓練CNN的gound truth。多影象3DMM重建包括兩步:一,從CASIA資料集選取500K當個影象來估計3DMM引數。二,同一個體不同照片生成的3DMM聚合一起,獲取單個個體的3DMM(約10K個體)。
8.2.1 Single image 3DMM fitting
採用兩種不同的方法來對每一個訓練圖片配對上3DMM。對於影象I,我們估計和
來表示與輸入影象I類似的影象。採用了目前最好的人臉特徵點檢測器(CLNF)來檢測K=68個人臉特徵點
和置信值
。其中,臉部特徵點用於在3DMM座標系中初始化輸入人臉的角度。角度表達為6個自由度:角度
和平移
。然後再對臉型,紋理,角度,光照和色彩進行處理。
8.2.2 Multi image 3DMM fitting
多影象3DMM生成通過pool 單個個體不同圖片生成的3DMM的臉型和紋理引數來實現。
其中
,
為CLNF臉部特徵檢測生成的置信值。
8.3 3D重建模型訓練
對於資料集中每一個個體,有多張圖片以及單個pool的3DMM。我們將該資料用於訓練模型,使模型可以根據同一個體不同的圖片來生成類似的3DMM特徵向量。
如圖8-1所示,我們採用了101層的deep ResNet網路來進行人臉識別。神經網路的輸出層為198維度的3DMM特徵向量
。然後,使用CASIA 影象生成的pooled 3DMM作為目標值對神經網路進行fine-tuned。我們也嘗試了使用VGG-16結構,結果比ResNet結構稍微差一點。

圖8-1 3D重建訓練示意圖 8.3.1 The asymmetric Euclidean loss 我們在實驗中發現,使用Euclidean loss會導致輸出3d人臉缺少細節,如圖8-2所示。因此,我們引入了asymmetric Euclidean loss。
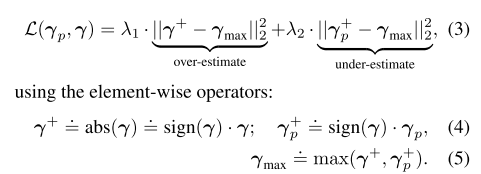
其中,為目標pooled 3DMM值,
為輸入,
為平衡over和under estimation errors的值。在實際操作中,我們設定
,來鼓勵模型學習更多的細節。
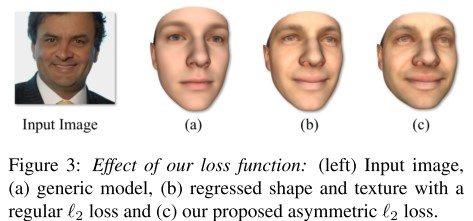
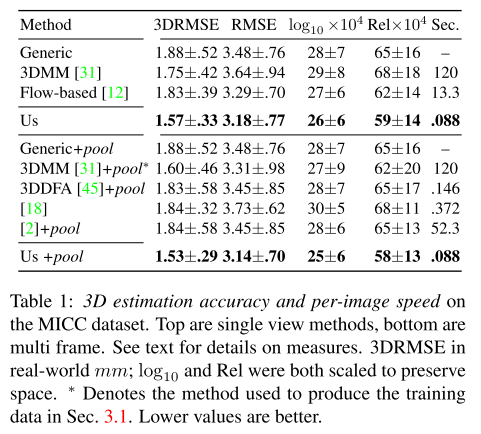
圖8-2 不同loss函式對結果的影響 8.4 實驗結果 8.4.1 3D重建結果 MICC資料集包含53個個體的人臉視訊和個體的3D模型作為gound truth。這些視訊可以用於單張圖片和多張圖片的3D重建。實驗結果如表8-1所示,該重建方法比當前的方法都要好。 表8-1 3D重建實驗結果
8.4.2 人臉識別 我們研究了同一人不同的照片重建的3DMM是否比不同人的照片重建的3DMM差異更小。我們在LFW,YTF和IJB-A資料集上測試了我們的方法。結果如表8-2和圖8-3所示。 表8-2 LFW和YTF測試結果
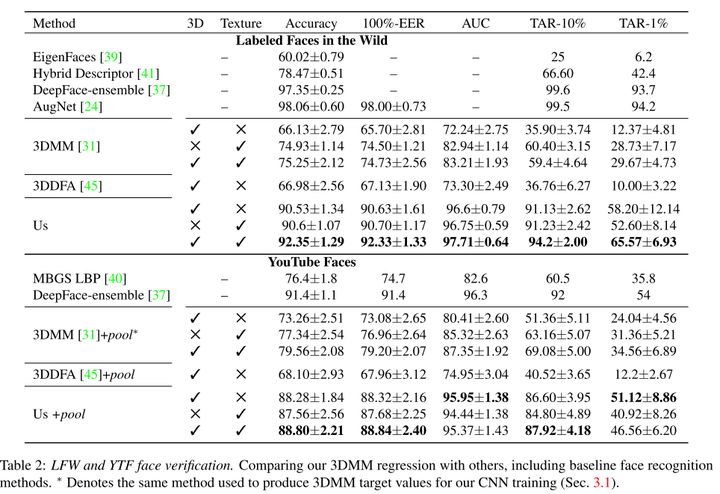
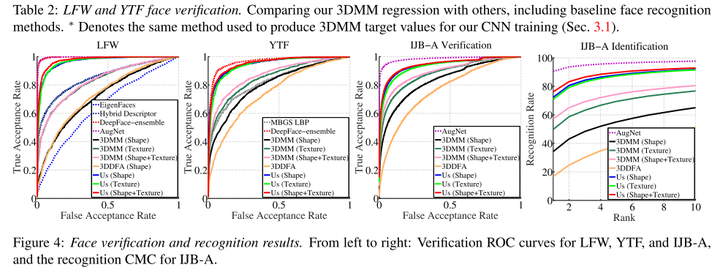
圖8-3 LFW,YTF和IJB-A測試結果 8.4.3 定性結果 圖8-4展示了訓練模型生成的3DMM結果。

圖8-4 3DMM生成模型結果總結 本文綜述了8種基於深度學習的人臉識別方法,包括:1,face++(0.9950 );2,DeepFace(0.9735 );3,FR+FCN(0.9645 );4,DeepID(0.9745 );5,FaceNet(0.9963 );6, baidu的方法(0.9977 );7,pose+shape+expression augmentation(0.9807);8,CNN-3DMM estimation(0.9235 )。上述方法可以分為兩大類: 第一類:face++,DeepFace,DeepID,FaceNet和baidu。他們方法的核心是蒐集大資料,通過更多更全的資料集讓模型學會去識別人臉的多樣性。這類方法適合百度/騰訊/谷歌等大企業,未來可以蒐集更多更全的訓練資料集。資料集包擴同一個體不同年齡段的照片,不同人種的照片,不同型別(美醜等)。通過更全面的資料,提高模型對現場應用中人臉差異的適應能力。 第二類:FR+FCN,pose+shape+expression augmentation和CNN-3DMM estimation。這類方法採用的是合成的思路,通過3D模型等合成不同型別的人臉,增加資料集。這類方法操作成本更低,更適合推廣。其中,特別是CNN-3DMM estimation,作者做了非常出色的工作,同時提供了原始碼,可以進一步參考和深度研究。 上述方法在理想條件下的人臉識別精確度已經達到或者超越人類的表現。但是,由於光線,角度,表情,年齡等多種因素,導致人臉識別技術無法在現實生活中廣泛應用。未來研究中,不管哪種思路,均是提高模型對現場複雜環境的適應能力,在複雜環境中,也能達到人類識別的精確度。 人臉識別技術是計算機視覺和深度學習領域中相對成熟的技術,很期待該技術的廣泛應用。