
連結串列基礎知識總結--
連結串列和陣列作為演算法中的兩個基本資料結構,在程式設計過程中經常用到。儘管兩種結構都可以用來儲存一系列的資料,但又各有各的特點。
陣列的優勢,在於可以方便的遍歷查詢需要的資料。在查詢陣列指定位置(如查詢陣列中的第4個數據)的操作中,只需要進行1次操作即可,時間複雜度為O(1)。但是,這種時間上的便利性,是因為陣列在記憶體中佔用了連續的空間,在進行類似的查詢或者遍歷時,本質是指標在記憶體中的定向偏移。然而,當需要對陣列成員進行新增和刪除的操作時,陣列內完成這類操作的時間複雜度則變成了O(n)。
連結串列的特性,使其在某些操作上比陣列更加高效。例如當進行插入和刪除操作時,連結串列操作的時間複雜度僅為O(1)。另外,因為連結串列在記憶體中不是連續儲存的,所以可以充分利用記憶體中的碎片空間。除此之外,連結串列還是很多演算法的基礎,最常見的雜湊表就是基於連結串列來實現的。基於以上原因,我們可以看到,連結串列在程式設計過程中是非常重要的。本文總結了我們在學習連結串列的過程中碰到的問題和體會。
接下來,我們將對連結串列進行介紹,用C語言分別實現:連結串列的初始化、建立、元素的插入和刪除、連結串列的遍歷、元素的查詢、連結串列的刪除、連結串列的逆序以及判斷連結串列是否有環等這些常用操作。並附上在Visual Studio 2010 中可以執行的程式碼供學習者參考。
說到連結串列,可能有些人還對其概念不是很瞭解。我們可以將一條連結串列想象成環環相扣的結點,就如平常所見到的鎖鏈一樣。連結串列內包含很多結點(當然也可以包含零個結點)。其中每個結點的資料空間一般會包含一個數據結構(用於存放各種型別的資料)以及一個指標,該指標一般稱為next,用來指向下一個結點的位置。由於下一個結點也是連結串列型別,所以next的指標也要定義為連結串列型別。例如以下語句即定義了連結串列的結構型別。
typedef struct LinkList
{
int Element;
LinkList * next;
}LinkList;
連結串列初始化
在對連結串列進行操作之前,需要先新建一個連結串列。此處講解一種常見的場景下新建連結串列:在任何輸入都沒有的情況下對連結串列進行初始化。
連結串列初始化的作用就是生成一個連結串列的頭指標,以便後續的函式呼叫操作。在沒有任何輸入的情況下,我們首先需要定義一個頭指標用來儲存即將建立的連結串列。所以函式實現過程中需要在函式內定義並且申請一個結點的空間,並且在函式的結尾將這個結點作為新建連結串列的頭指標返回給主調函式。本文給出的例程是生成一個頭結點的指標,具體的程式碼實現如下:
linklist * List_init()
{
linklist *HeadNode= (linklist*)malloc(sizeof(linklist));
if(HeadNode == NULL)
{
printf("空間快取不足");
return HeadNode;
}
HeadNode->Element= 0;
HeadNode->next= NULL;
returnHeadNode;
}
當然,初始化的過程或者方法不只這一種,其中也包含頭指標存在的情況下對連結串列進行初始化,此處不再一一羅列。
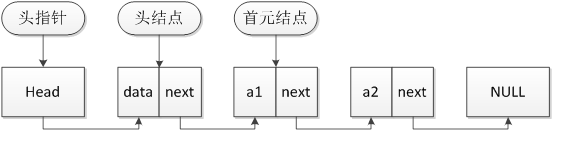
這裡引申一下,此處例程中返回的連結串列指標為該連結串列的頭結點,相對應的還有一個頭指標的概念。頭指標內只有指標的元素,並沒有資料元素,但頭結點除了指標還有資料。
頭指標就是連結串列的名字,僅僅是個指標而已。頭結點是為了操作的統一與方便而設立的,放在第一個有效元素結點(首元結點)之前,其資料域一般無意義(當然有些情況下也可存放連結串列的長度、用做監視哨等等)。一般情況下見到的連結串列的指標多為頭指標,但最近在一個程式設計師程式設計網站leetcode中發現,題目中所給的連結串列一般是首元結點作為第一個元素,而不是頭指標。
下圖為頭指標與頭結點以及首元結點的關係。
連結串列建立
建立連結串列需要將既定資料按照連結串列的結構進行儲存,本文以一種最簡單的方式來演示:使用陣列對連結串列賦值。將原來在連續空間存放的陣列資料,放置在不連續的連結串列空間中,使用指標進行連結。
連結串列建立的步驟一般使用給定的頭指標以及需要初始化的資料序列作為輸入引數,本文使用陣列作為輸入資料序列。在下面的例程中,先將首元結點使用陣列第一個元素初始化,再在首元結點之後建立新的連結串列結點賦值陣列內餘下的資料。具體實現如下:
void CreatList(linklist *HeadNode,int *InData,int DataNum)
{
int i = 0;
linklist *CurrentNode = (linklist*) HeadNode;
for(i = 0;i<DataNum;i++)
{
CurrentNode->Element = InData[i];
if(i< DataNum-1)// 由於每次賦值後需要新建結點,為了保證沒有多餘的廢結點
{
CurrentNode->next =(linklist *)malloc(sizeof(linklist));
CurrentNode= CurrentNode->next;
}
}
CurrentNode->next= NULL;
}
程式內先新建了一個指標變數CurrentNode用來表示當前的結點指標。最初,我們讓CurrentNode指向了首元結點HeadNode的位置。然後根據輸入陣列的大小進行迴圈賦值,賦值完成之後再重新申請一個結點空間用來存放下一個結點的內容,並且將當前結點指標CurrentNode指向新生成的結點。由於連結串列建立函式呼叫時已經存在一個首元結點,按照這個邏輯最終在使用最後一個數組資料賦值之後還會多生成一個結點。因此,為了保證沒有冗餘的結點,迴圈內需要用DataNum-1來控制結點數量。
另外,C語言的初學者需要注意:無論被調子函式內含在幾個引數,雖然子函式內的形參使用的是主函式內實參的指標,但在子函式內是不會改變主函式裡實參的地址的。也就是說,只要子函式不返回指標,子函式的內容就不會影響主函式內的引數指標。正如程式中CurrentNode的指標最初是主函式內的頭指標傳遞進來的,雖然建立連結串列的函式內CurrentNode的指標一直在往後移動,但並不會改變主調函式內的首元結點的指標。本文連結串列的學習過程中會大量使用指標,建議各位學習者在打牢基礎後再進行學習。
插入連結串列結點
連結串列建立完之後,下面我們將介紹如何向連結串列內插入結點。一般新增結點可以分為兩類:一類是在連結串列尾部插入;另一類為在中間插入。
連結串列結尾新增結點的步驟就是新建一個連結串列結點,將其連結到當前連結串列尾指標。
在中間結點插入結點的步驟稍微複雜一些,其中也包含兩種情況,分別是在指定結點前插入和指定結點後插入。其操作原理一樣,本文只對指定位置後插入結點進行介紹。指定結點前插入結點留給大家嘗試。
假設一個連結串列記憶體在幾個幾點A1,A2,A3,A4….,當根據要求需要在指定位置之後(比如A2結點)插入一個新結點時。首先我們需要新建立一個結點NodeToInsert,然後將新結點的next指向A3,並且將A2的next指標指向新建立的結點NodeToInsert,切記操作順序不要改變。如果操作順序變換一下,先將A2的next指向了新建立的結點,那麼我們就丟失了A3的定址方式。因此,在將A2的next指向其他任何地方之前,請務必將A3的地址存在NodeToInsert或者某個新建節點內。
插入結點的具體操作如下:
bool InsertList(linklist *HeadNode,int LocateIndex,int InData)
{
int i=1;// 由於起始結點HeadNode是頭結點,所以計數從1開始
linklist *CurrentNode= (linklist *) HeadNode;
//將CurrentNode指向待插入位置的前一個結點(index -1)
while(CurrentNode&& i<LocateIndex-1)
{
CurrentNode= CurrentNode->next;
i++;
}
linklist *NodeToInsert=(linklist*)malloc(sizeof(linklist));
if(NodeToInsert == NULL)
{
printf("空間快取不足");
return ERROR;
}
NodeToInsert->Element= InData;
NodeToInsert->next = CurrentNode->next;
CurrentNode->next = NodeToInsert;
return OK;
}
刪除連結串列結點
對應於插入連結串列結點,連結串列的基本操作中同樣也有刪除連結串列結點。刪除結點包括刪除指定位置的結點和指定元素的結點。其基本原理都是先鎖定待刪除的結點的位置,然後將該結點的後置結點連結到前置結點的next指標處。這樣中間這個結點即我們要刪除的結點就從原來的連結串列中脫離開來。相對於原來的連結串列,即刪除了該結點。
bool DeleteList(linklist * HeadNode,int index, int * DataToDel)
{
int i = 1;
linklist *CurrentNode = HeadNode;
linklist *NodeToDelete;
//將CurrentNode指向待刪除位置的前一個結點(index -1)
while(CurrentNode&& i<index-1)
{
CurrentNode= CurrentNode->next;
i++;
}
NodeToDelete = CurrentNode->next;
*DataToDel =NodeToDelete->Element;
CurrentNode->next= NodeToDelete->next;
free(NodeToDelete);
return OK;
}
此處為什麼還要重新建立一個指標來記錄或者儲存待刪除的結點呢?明明一個簡單的步驟CurrentNode ->next = CurrentNode ->next->next;就可以將這個結點CurrentNode->next刪除了,為什麼要多此一舉呢?
此處新建的連結串列型別的指標NodeToDelete是為了釋放CurrentNode->next。直接使用CurrentNode ->next = CurrentNode ->next->next只是將該節點從連結串列中剔除,但是沒有將其空間從記憶體中釋放。而且,經過了CurrentNode ->next = CurrentNode ->next->next這個賦值語句之後,我們已經丟失了原本需要刪除的結點的地址。所以,在刪除之前新建了個結點用來儲存待刪除的結點地址,以便後面對記憶體空間的釋放。
獲取連結串列長度&連結串列遍歷
獲取連結串列的長度實際上和遍歷連結串列具有相同的操作。遍歷的過程將連結串列內的結點都訪問了一邊。獲取連結串列長度的具體步驟是遍歷連結串列之後能夠記錄並返回連結串列結點個數。
本文給出獲取連結串列長的函式程式碼。
int GetListLength(linklist *HeadNode)
{
int ListLength = 0;
linklist *CurrentNode= (linklist*) HeadNode;
while(CurrentNode)// 當前指標不為空時可以計數累加
{
ListLength++;
CurrentNode= CurrentNode->next; //指標移到下一結點
}
returnListLength;
}
在該函式中,出現了CurrentNode = CurrentNode ->next的表示方法,這是將CurrentNode ->next這個結點的指標移動到了當前這個結點CurrentNode,下一次使用CurrentNode指標的時候CurrentNode實際已經指向了下一個結點CurrentNode ->next。所以這也是常說到的結點後移。
對於連結串列內的賦值操作我們總結出幾種情況:
獲取連結串列元素
接下來我們將“給定連結串列中的某一個位置,返回該位置的資料值”和“返回連結串列內某一個元素的位置”這兩個問題放在一起介紹。
這兩種情況的思路都是需要遍歷連結串列。在給定元素值的情況下,定義一個元素序號隨著遍歷的過程累加,遍歷的過程校驗連結串列的結點是否與給定的元素匹配,如果匹配則返回元素位置的序號;在給定位置的情況下就更簡單一些,元素序號累加到對應位置,返回對應結點的元素即可。
本文只列出給定元素值的例子:
int LocateElement(linklist * HeadNode,int DataToLocate)
{
int LocateIndex = 1;
linklist *CurrentNode= (linklist*) HeadNode;
while(CurrentNode)
{
if(CurrentNode->Element== DataToLocate)
{
returnLocateIndex; //找到位置返回
}
CurrentNode= CurrentNode->next;
LocateIndex++;
}
return -1; //如果沒有這個值,返回-1
}
本函式的邏輯是如果遍歷連結串列之後能夠找到與所給元素匹配的結點,則將該結點的位置返回。但如果沒有匹配的結點的話,則返回一個-1,表示獲取元素位置失敗。
連結串列置空
連結串列置空又可以稱為銷燬連結串列。同樣是在遍歷的前提下,一直到連結串列結尾結束,所有遍歷到的連結串列結點均釋放掉空間,具體程式碼如下:
bool DestroyList(linklist * HeadNode)
{
linklist *pNext;
linklist *CurrentNode= (linklist*) HeadNode;
while(CurrentNode)
{
pNext = CurrentNode->next;
free(CurrentNode);
CurrentNode= pNext;
}
HeadNode->next = NULL;
return OK;
}
連結串列逆序
連結串列的逆序有很多種思路,本文介紹一種將當前結點的下一結點一直往頭指標之後移動的思路。
假設當前有5個結點,head、a1、a2、a3、a4、a5,他們的頭指標是head。我們的思路便是將a1作為當前元素一直往後遍歷,並且將a1後面的資料依次挪到head之後。
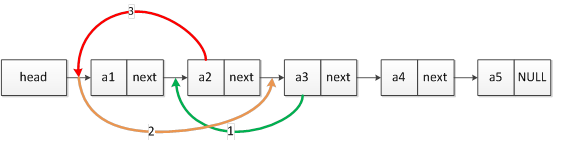
在第一次搬移的過程中,需要將a1的下一個元素a2放在head之後。如圖所示,當前結點選定為a1,起一個變數名為current,當前結點的下一個結點為pNext,則a2便成了pNext = current->next。如果想要將pNext移到head之後,我們按照圖中第1步先將a3連線到a1的後面,然後第2步再將head後面的整體連結串列放到要移動的a2的後面,也就是pNext->next= head->next,第3步將a2移到head之後。這三個步驟下來,我們的第一次反轉工作就算完成了。此時的連結串列連結串列就變成了head、a2、a1、a3、a4、a5,如圖所示:

如果上面移動的步驟不按圖中進行會出現什麼情況呢?假設現在按照3-2-1的步驟來實現a2移動到head後面。當先進行第三步之後,即head->next = pNext;這一步直接將a2挪到了head之後。然後我們接下來應該再將原來head後面的一串資料鏈接到剛剛移動到head後面的a2後面,此處由於head後面的資料已經被pNext更新了,此時head後面是a2結點,所以在執行第二步以後,連結串列就變成了無限迴圈的連結串列,而且迴圈的元素值是a2。
按照上圖正確的順序實現第一次反轉以後,可以判定當前的current指標是否已經是尾指標,如果不是就可以繼續執行。第二次反轉後連結串列就變成了head、a3、a2、a1、a4、a5。因此當把連結串列內的最後一個元素也移動到head之後時,連結串列逆序的工作就算完成了。

具體的程式碼實現如下。
linklist * ListRotate(linklist * HeadNode)
{
linklist* current,*pNext,*pPrev;
pPrev = (linklist*)malloc(sizeof(linklist));
if(pPrev == NULL)
{
printf("空間快取不足");
return ERROR;
}
pPrev->next = HeadNode;
current = HeadNode;
while(current->next)
{
pNext = current->next;
current->next = pNext->next;
pNext->next = pPrev->next;
pPrev->next = pNext;
}
return pPrev->next;
}
連結串列判斷是否有環
判斷連結串列是否存在環的過程中,通常最先想到的方法就是從定義下手,有環的話就沒有尾結點,也就是說不存在一個結點的next指標是null。通過這種思路可以對有環無環進行判定,但需要判定到何時呢?
當遍歷了4000個結點都沒有遇到null結點,難道就可以斷定這就是一個有環的連結串列嗎?如果它的第4001個結點就是尾結點呢?很多情況下,我們是不知道連結串列的長度的,所以我們很難確定需要判定到哪一個結點才能確定連結串列是否為環形連結串列。因此我們需要藉助快指標、慢指標的概念,這是目前用來判斷連結串列內有環無環的最通用有效的方法。
假設有這樣一種情況,有兩輛車,一輛車每秒鐘可以跑n米,另外一輛速度要快一些,每秒能跑2n米,這兩輛車都勻速執行。如果在一個沒有交叉點的跑道上,這時跑道上有一個終點,快車和慢車同時在起始點相遇出發之後,一直到終點,快車和慢車的距離只會越拉越大,等到快車到達終點的時候,兩者之間的距離差最大。假想一種情況,如果跑道的終點與起始點連線了起來,雖然說從慢車的角度看,快車在前方越來越遠。但快車的角度看,慢車在後面越來越遠,但在前面看的話確實越來越近。所以在一個環形的跑道上,快車終究會有第二次與慢車相遇,此時正好超車一圈。
函式的執行過程如下:
bool IsListLoop(linklist *HeadNode)
{
linklist *pFast,*pSlow;
pFast = pSlow = HeadNode;
while(pFast && pSlow)
{
pSlow = pSlow->next;
if(pFast->next)
{
pFast= pFast->next->next;
}
else
{
pFast= pFast->next;
}
if(pFast == pSlow)
{
returnTRUE;
}
}
return FALSE;
}
以上介紹了連結串列的部分基本操作,這些操作是實現很多演算法的基礎。希望大家共同學習進步,不足之處望指出。