
【論文閱讀】Deep Mixture of Diverse Experts for Large-Scale Visual Recognition
導讀:
本文為論文《Deep Mixture of Diverse Experts for Large-Scale Visual Recognition》的閱讀總結。目的是做大規模影象分類(>1000類),方法是混合多個小深度網路實現更多類的分類。本文從以下五個方面來對論文做個簡要整理:
背景:簡要介紹與本文方法提出的背景和獨特性。
方法:介紹論文使用的大體方法。
細節:介紹論文中方法涉及到的問題及解決方案。
實驗:實驗結果和簡要分析。
總結:論文主要特色和個人體會。
一、背景
1.目標:大規模影象分類(>1000),以往做影象分類最多為1000類的分類,更多的類的區分難度比較大,也鮮有方法,以往對此問題的解決方案包括下面三種:
1)設計更復雜的網路
此類方法專門針對大規模影象分類設計深度網路,但是該方法可操作性不強,原因是網路結構設計的未知性、大量資源消耗、資料量不夠大導致過擬合等。
2)網路轉換
此類方法是指將在其他資料集上訓練好的網路模型移植到新的資料上使用,但該方法一般是從在多類資料集上訓練好的模型遷移到少類上,而以往訓練的模型(<1000)類別數比較少,移植到類別大的資料集上往往效果不夠好。
3)多個小CNN結合
此類方法是指,學習多個少類的神經網路,然後將多個少類神經網路結合起來,實現對多類分類的效果,該方法可以達到以更少資源取得更多分類的效果。
本文採用的分類方法為第三種多個小CNN結合
2.特色
1)與分層樹區別
分層樹是自頂而下的分類,且高層分類時需同時使用所有類別。
本文方法是自下而上的分類,每次訓練時只需使用大類的一個子集即可。
2)與單任務多網路區別
以往也有將多個網路結合起來做混合預測的方法,但此種單任務多網路方法的每個任務空間是相同的,只是起到特徵間相互彌補的作用。而本文方法的每個子網路都有自己的任務空間,有任務重疊但不重合。
因此,本文方法是獨特的,即鮮有人使用的。
二、方法
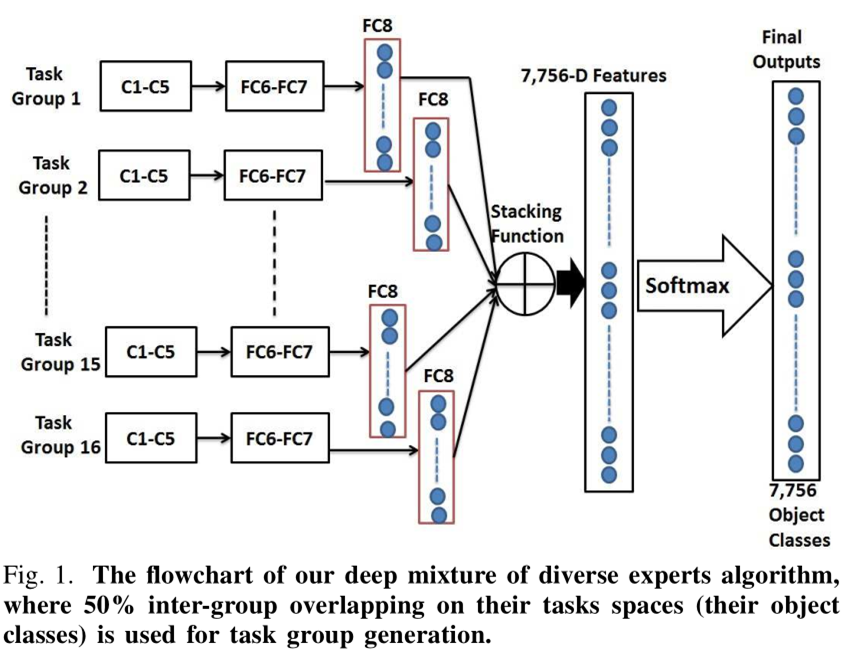
1.概述:本文采用的方法大體流程如下圖
1)按語義相似度構建兩層架構,同時允許組內有重疊。
2)組內用單個CNN學習分類網路以及類間相關性(稱為多工)。
3)多個組的CNN輸出相結合形成混合網路並得到最終輸出。
2.挑戰
1)組的產生:隨機分組將導致相似(學習複雜度相同)的類不在一組將難以區分。
本文的解決方法是,將相似度高的分為一組,且相似度按高低排列,從左到右依此產生組,並允許組間有重疊。
2)類間可區分性:同一組的類別相似度往往比較高,更難區分。
本文的解決方法是,多工學習,即在學習分類網路的同時,學習類間的相似度,以增強可分性。
3)預測輸出可比性:如果多個子網路間沒有資訊交流,那麼產生的輸出就沒有可比性,也就不能得到最終的分類結果,而且有重疊的情況下多個組的預測結果可能產生衝突。
本文的解決方法是,在每個子網路的輸出中,增加not-in-group項,即不在該子網路裡的類別對應的gt為not-in-group,同時組間有重疊,從而使組間的資訊可以交流。
三、細節
1.兩層架構:本文方法的第一步為構建兩層架構,該步驟的方法是:
1)按下面公式計算相似度矩陣並用譜聚類方法得到大類(category)

其中,ψi,j表示小類(class)i和j的相似度,D(ci,cj)表示在WordNet上從類i到j所需要經過的節點數,H表示WordNet上從根草最深類節點經過的節點數,
2)按相似度排列大類(category)形成圈。即大類間越相似,排列後的位置越靠近。
3)以一定順序依此每次取M個小類(class)形成組(group)。
得到的組即為我們要得到的東西,即兩層架構,步驟中的大類(category)僅在形成組時有用到,後續不再使用。形成組的過程如圖:

2.單個CNN的學習:本文方法的第二步為單個CNN的學習,即組分類器的學習,其中涉及到的幾個關鍵因素如下:
1)base CNN:本文采用的基礎神經網路為預訓練好的Alexnet。
2)優化目標:
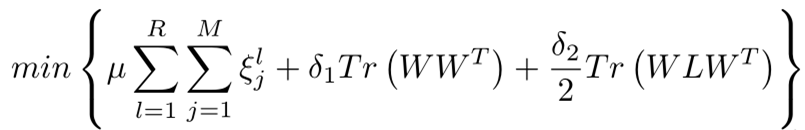
上式中,R和M分別為每類訓練集的影象數和組內的類別數,ξlj表示訓練錯誤率,符號定義為
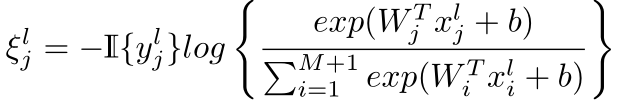
W表示網路引數,x表示深度特徵,L表示類間相似度矩陣S的拉普拉斯矩陣,相似度矩陣S定義為
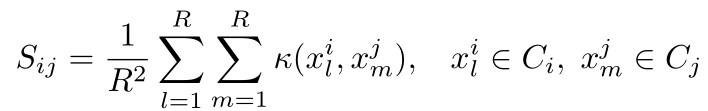
3)Loss:將上述定義帶入(2)中的優化目標可導到損失函式
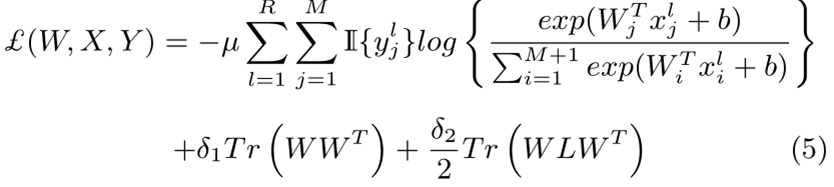
3.融合預測:本文方法的第三步為多個組預測結果的融合,其中包括以下兩步
1)獲得第j組第i類的輸出分數為pj(ci)
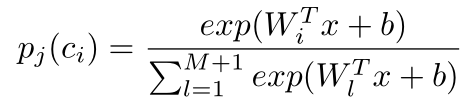
2)組內預測調整

上式中,Υ(ci)表示融合後的向量中,第i類的分數,Λj (ci)是第i個原子類在第j組的指示子,在為1不在為0,φj為第j組中not-in-group的預測分數,用於調整同組其餘預測分數。即,預測為not-in-group的分數越大,那麼是其他類的分數就應該越小。
在分數融合之後得到M維的向量,經過softmax層得到最終的預測輸出,此處總的Loss為
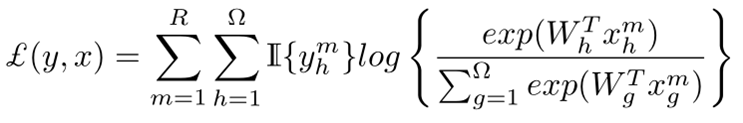
該Loss的梯度不僅用於更新融合前後網路的引數,也用於更新基礎網路的引數。
四、實驗
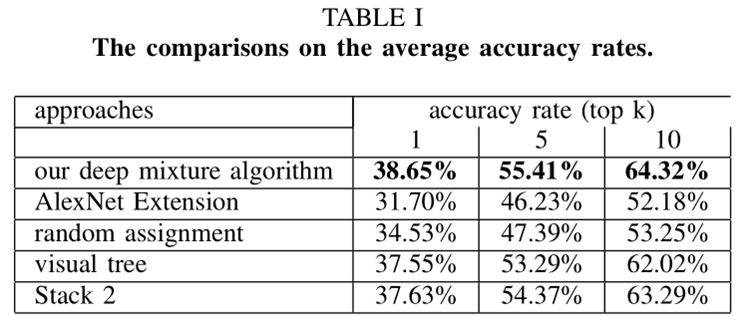
上圖的第2項表示直接將Alexnet的輸出層節點增加到M個,第3項表示不採用本文構建視覺樹的方法直接隨機分組,第4項表示採用其他論文視覺樹構建方法,第5項表示預測融合時修改not-in-group對同組其他類分數的影響得到的結果。
從上圖可以看出本文方法得到的結果最好。
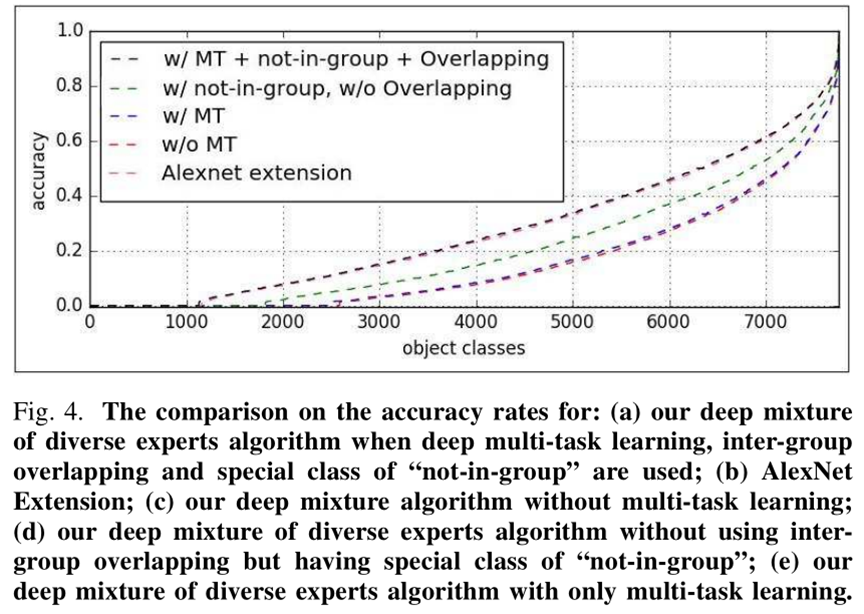
上圖表示多工學習、有沒有not-in-group項、有沒有overlap對本文方法的影響。
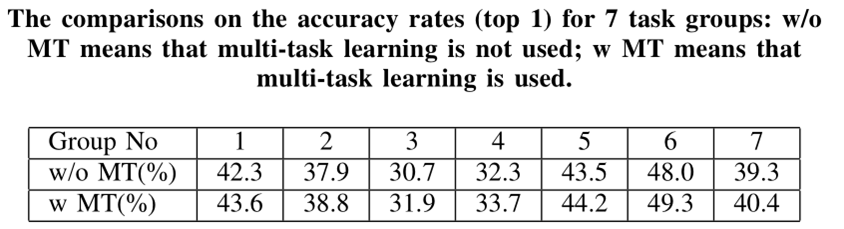
上圖表示有沒有多工學習對結果的影響還是比較大的。
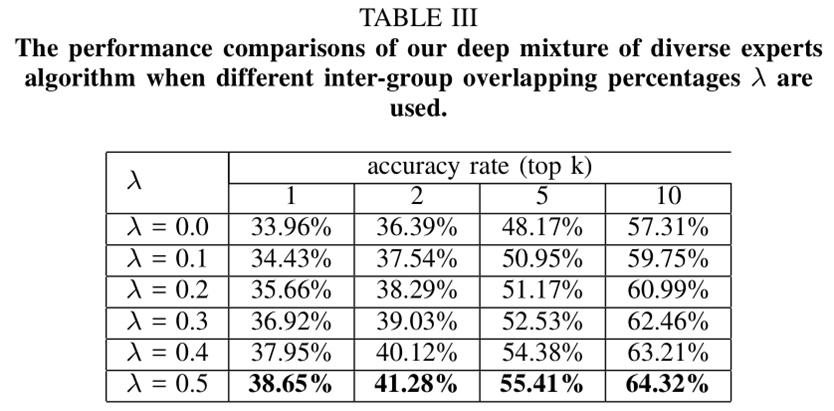
上圖表示,組內重疊率越大結果越好。
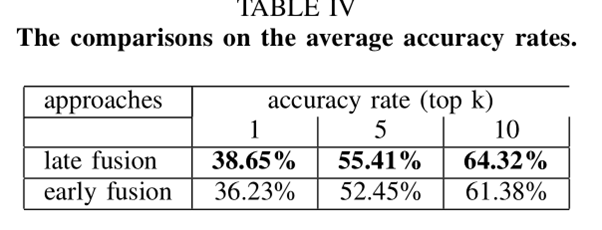
上圖第1種方法表示本文采用的將FC8層預測結果融合的方法,第2種表示將FC7層特徵融合的方法。

上圖表示採用不同基礎網路對實驗結果的影響。
五、總結
1.本文的任務是創新的:以小網路解決大任。務
2.在組內Loss中加入類間相似度矩陣學習項提高可分性。
3.組內預測輸出加入not-in-group項,使得組間資訊可比。
4.文章最後提出組內多個基礎網路融合更能提高識別結果。
5.本文方法理論簡單,可操作性較強。