
機器學習模型評測:holdout cross-validation & k-fold cross-validation
cross-validation:從 holdout validation 到 k-fold validation
2016年01月15日 11:06:00 Inside_Zhang 閱讀數:4445
版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/lanchunhui/article/details/50522424
構建機器學習模型的一個重要環節是評價模型在新的資料集上的效能。模型過於簡單時,容易發生欠擬合(high bias);模型過於複雜時,又容易發生過擬合(high variance)。為了達到一個合理的 bias-variance 的平衡,此時需要對模型進行認真地評估。本文將介紹兩個十分有用的cross-validation技術,holdout cross-validation 以及 k-fold cross-validation,這些方法將幫助我們獲得模型關於泛化誤差(generalization error)的可信的估計,所謂的泛化誤差也即模型在新資料集上的表現。
holdout validation
from sklearn.cross_validation import train_test_split使用 holdout 方法,我們將初始資料集(initial dataset)分為訓練集(training dataset)和測試集(test dataset)兩部分。訓練集用於模型的訓練,測試集進行效能的評價。然而,在實際機器學習的應用中,我們常常需要反覆除錯和比較不同的引數設定以提高模型在新資料集上的預測效能。這一調參優化的過程就被稱為模型的選擇(model selection):select the optimal
一個使用 holdout 方法進行模型選擇的較好的方式是將資料集做如下的劃分:
-
訓練集(training set);
The training set is used to fit the different models
-
評價集(validation set);
The performance on the validation set
is then used for the model selection。 -
測試集(test set);
The advantage of having a test set that the model hasn’t seen before during the training and model selection steps is that we can obtain a less biased estimate of its ability to generalize to new data. 下圖闡述了 holdout cross-validation 的工作流程,其中我們重複地使用 validation set 來評估引數調整時(已經歷訓練的過程)模型的效能。一旦我們對引數值滿意,我們就將在測試集(新的資料集)上評估模型的泛化誤差。
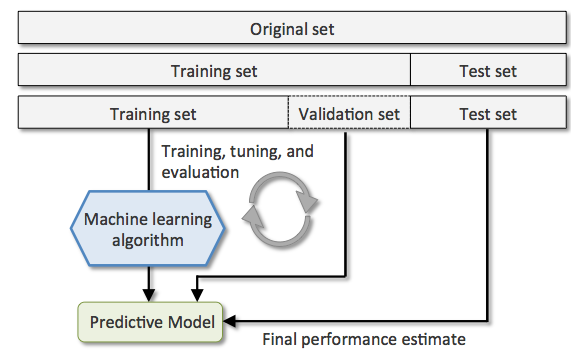
holdout 方法的弊端在於效能的評估對training set 和 validation set分割的比例較為敏感。
k-fold validation
在 k-fold cross_validation,我們無放回(without replacement)地將訓練集分為 k folds(k個部分吧),其中的 k-1 folds 用於模型的訓練,1 fold 用於測試。將這一過程重複 k 次,我們便可獲得 k 個模型及其效能評價。
我們然後計算基於不同的、獨立的folds的模型(s)的平均效能,顯見該效能將與holdout method相比,對training set的劃分較不敏感。一旦我們找到了令人滿意的超參的值,我們將在整個訓練集上進行模型的訓練。
因為k-fold cross-validation 是無放回的重取樣技術,這種方法的優勢在於每一個取樣資料僅只成為訓練或測試集一部分一次,這將產生關於模型效能的評價,比 hold-out 方法較低的variance。下圖展示了 k=10k=10 時的 k-fold 方法的工作流程。
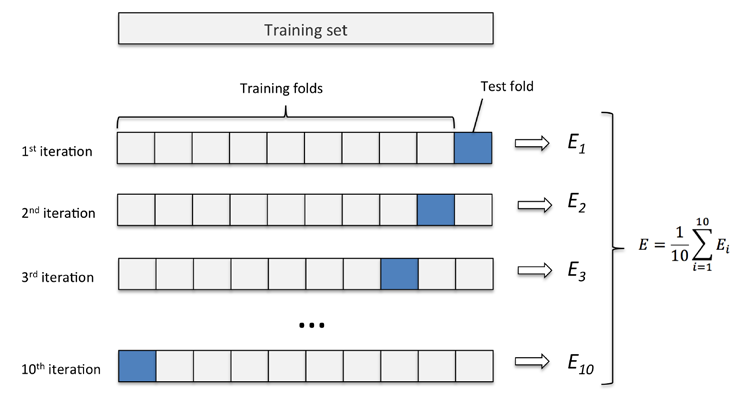
k-fold cross-validation 的 kk 值一般取10,對大多數應用而言是一個合理的選擇。然而,如果我們處理的是相對較小的訓練集的話,增加 kk 的值將會非常實用。因為如果增加 kk,更多的訓練資料(N×(1−1k)N×(1−1k))得以使用在每次迭代中,這將導致較低的 bias在評估模型的泛化效能方面。然而,更大的 kk 將會增加cross-validation的執行時間,生成具有更高higher variance 的評價因為此時訓練資料彼此非常接近。另一方面,如果我們使用的是大資料集,我們可以選擇更小的 kk,比如 k=5k=5,較小的 kk 值將會降低在不同folds上的refitting 以及模型評估時的計算負擔。
一個 k-fold cross-validation 的特例是 LOO(leave-one-out) cross-validation method。在LOO中,我們取 k=nk=n,如前所述,LOO尤其適用於具有小規模的資料集上。
對於 k-fold cross-validation 的一中改進是 stratified k-fold cv method,該方法可以產生更好的 bias以及variance 評價,尤其當 unequal class proportions。
實踐
from sklearn.cross_validation import StratifiedKFold
kfolds = StratifiedKFold(y=y_train, n_folds=10, random_state=1)
scores = []
for i, (train, test) in enumerate(kfolds):
# train.shape 將是 test.shape的接近9倍
clf.fit(X_train[train], y_train[train])
score = clf.score(X_train[test], y_train[test])
scores.append(score)
print('Fold: %s, class dist.: %s, Acc: %.4f' %(i+1, np.bincount(y_train[train]), score))
print('CV accuracy: %.4f +/- %.4f' % (np.mean(scores), np.std(scores)))