Scrapy爬取京東商城華為全系列手機評論
阿新 • • 發佈:2018-12-16
本文轉自:https://mp.weixin.qq.com/s?__biz=MzA4MTk3ODI2OA==&mid=2650342004&idx=1&sn=4d270ab7ca54f6f2f7ec7aca113993f4&chksm=87811487b0f69d91d2b3a072be22e50b436e342e05cea6c1e28c9ade4c814f8ba1a53118a69b&scene=0&xtrack=1#rd
前言
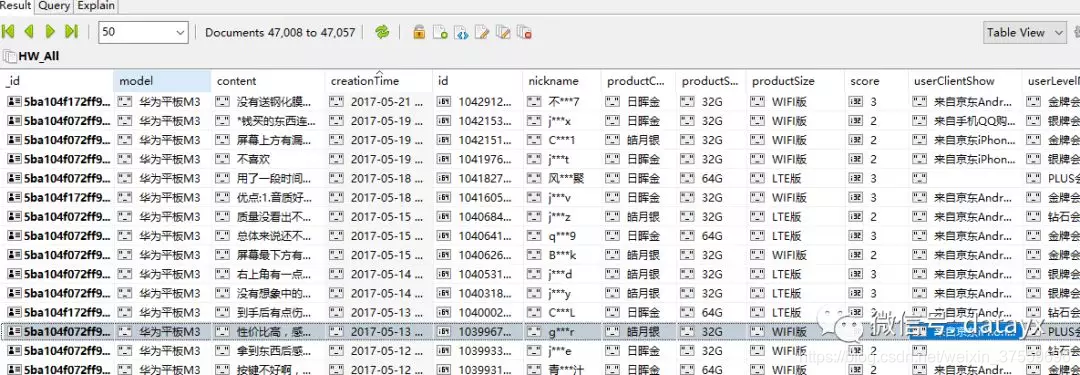
大致分析了下京東評論 相同手機型號的產品用的評論都是一樣的,所以每個型號的爬一個就可以了;
每一個評論最多隻能爬100頁,每頁10條, 加上好中差評 大概能有2000多條不重複的評論
{productId}就是對應產品的productId;
{score}對應全部/好/中/差評 0:全部評價 1:差評 2:中評 3:好評
爬去評論
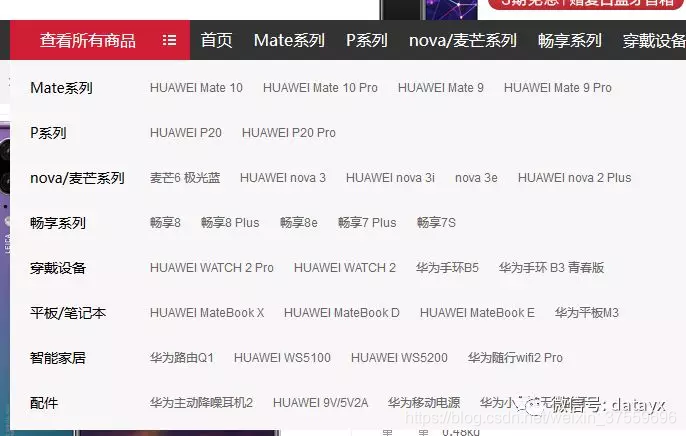
每個型號的找一個主頁,爬取評論
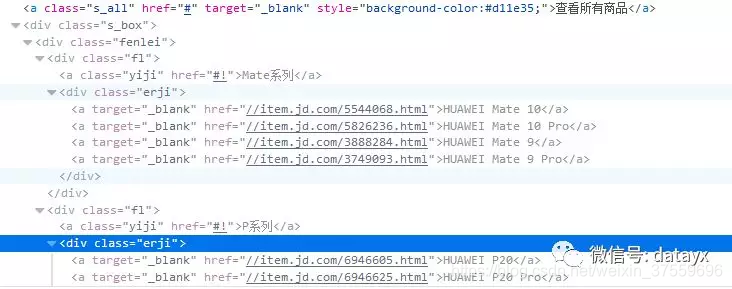
對應的html程式碼,用beautisoup分析網頁,得到手機型號和herf
程式碼實現:
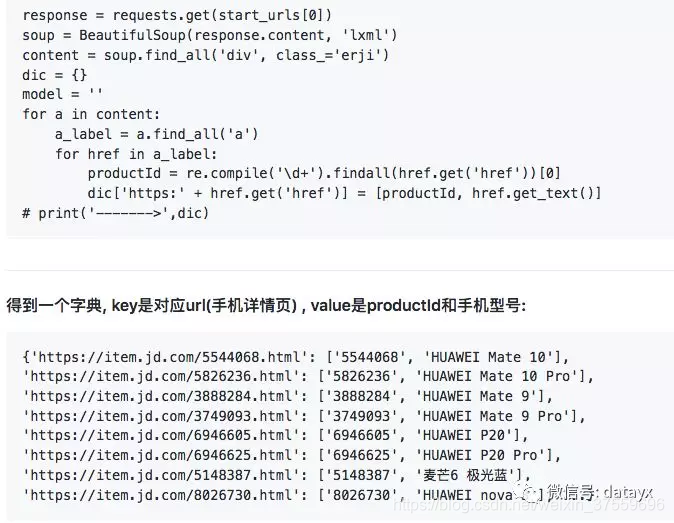

Start_requests:這裡用的方法比較簡單就是遍歷迴圈,根據url三個引數,爬取每個手機型號的,好中差評評論,最後通過pipelines存入mongodb,程式碼實現:
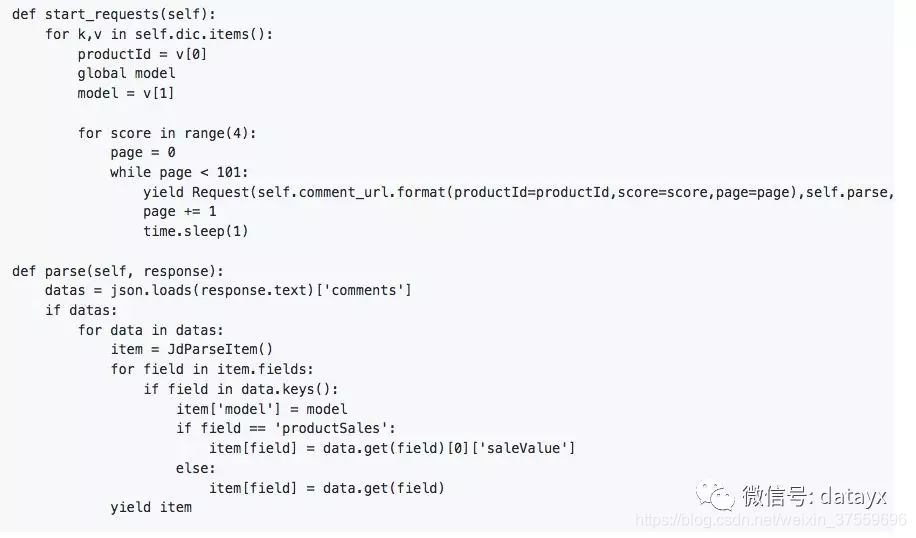
完整程式碼如下:
# -*- coding: utf-8 -*-
import re
import json
import time
import requests
from bs4 import BeautifulSoup
import 爬到的資料