
基於Ubuntu16.04+Spark+Python的線性迴歸(linear regression)演算法
參考:
spark+python+ubuntu環境配置:
https://blog.csdn.net/konglingshneg/article/details/82491157
Building A Linear Regression with PySpark and MLlib:
https://towardsdatascience.com/building-a-linear-regression-with-pyspark-and-mllib-d065c3ba246a
目錄
1.Ubuntu16.04+Spark+Python環境配置
2.利用Linear Regression預測Boston房價
1.Ubuntu16.04+Spark+Python環境配置
Spark是一個可以應用於大規模資料處理的快速通用引擎。是當今大資料領域最熱門的大資料計算平臺。Spark開發應用程式時可以採用Scala、Python、Java和R語言。在虛擬機器下的Ubuntu環境下安裝測試Spark,即使出錯也不會影響其他。
安裝JDK1.8:
Spark的執行環境依賴JVM環境,
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下載jdk-8u191-linux-x64.tar.gz
(1)在/usr/lib下新建一個資料夾 sudo mkdir /usr/lib/jdk
[email protected]:~$ sudo mkdir /usr/lib/jdk(2)系統預設下載到download資料夾(找到copy一下地址),cd 到下載檔案資料夾
[email protected]:~$ cd /home/zhb/Downloads/
[email protected]:~/Downloads$
(3)解壓縮到我們新建的資料夾 sudo tar -zxvf jdk-8u191-linux-x64.tar.gz -C /usr/lib/jdk
[email protected]:~/Downloads$ sudo tar -zxvf jdk-8u191-linux-x64.tar.gz -C /usr/lib/jdk(4)配置PATH路徑,讓jdk命令在任何路徑下都能夠直接執行, gedit、vi都可以。 sudo gedit /etc/profile
[email protected]:~$ gedit /etc/proflie
在配置檔案末尾追加
# java
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_191
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
(5)重新載入/etc/profile配置檔案 source /etc/proflie
[email protected]:~$ source /etc/profile(6)執行java -version檢視java是否安裝成功,出現如下結果說明安裝成功
[email protected]:~$ java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
[email protected]:~$
安裝spark :
(1)官網下載地址 http://spark.apache.org/downloads.html
Download Spark: spark-2.4.0-bin-hadoop2.7.tgz
(2)為spark新建一個資料夾sudo mkdir /usr/lib/spark
[email protected]:~$ sudo mkdir /usr/lib/spark(3)找到下載檔案目錄,並cd到該目錄下
[email protected]:~$ cd /home/zhb/Downloads/
[email protected]:~/Downloads$
(4)將下載檔案安裝到新建資料夾下sudo tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz -C /usr/lib/spark
[email protected]:~/Downloads$ sudo tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz -C /usr/lib/spark(5)配置spark
cd /usr/lib/spark/spark-2.4.0-bin-hadoop2.7/conf/
sudo cp spark-env.sh.template spark-env.sh
sudo gedit spark-env.sh
[email protected]:~$ cd /usr/lib/spark/spark-2.4.0-bin-hadoop2.7/conf/
[email protected]:/usr/lib/spark/spark-2.4.0-bin-hadoop2.7/conf$ sudo cp spark-env.sh.template spark-env.sh
[email protected]:/usr/lib/spark/spark-2.4.0-bin-hadoop2.7/conf$ sudo gedit spark-env.sh
在spark-env.sh檔案末尾追加:
JAVA_HOME=/usr/lib/jdk/jdk1.8.0_191
SPARK_WORKER_MEMORY=3g
(6)然後我們需要配置PATH路徑,讓jdk命令在任何路徑下都能夠直接執行
sudo gedit /etc/profile
[email protected]:~$ sudo gedit /etc/profile
在配置檔案後加上
#spark
export SPARK_HOME=/usr/lib/spark/spark-2.4.0-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:$PATH
(7)重新載入/etc/profile配置檔案
source /etc/profile
[email protected]:~$ source /etc/proflie
(8)執行 pyspark 檢視spark是否安裝成功,出現如下結果說明安裝成功

2.利用Linear Regression預測Boston房價
(1)在jupyter notebook使用spark時,通過findspark來呼叫spark。
切換到自己的python環境下,執行:
pip install findspark使用anaconda開啟jupyter notebook,在文件開頭輸入下列內容即可
import findspark
findspark.init()
(2)接下來採用Boston房價資訊資料集(https://www.kaggle.com/c/boston-housing/data)利用線性迴歸預測Boston房價。
Boston房價資訊:
crim:城鎮人均犯罪率
zn:佔地面積超過25,000平方英尺的住宅用地比例
indus:每個城鎮非零售業務的比例
chas: Charles River虛擬變數
nox:氮氧化物濃度(每千萬份)
rm:每間住宅的平均房間數
age: 1940年以前建造的自住單位比例
dis:到五個波士頓就業中心的距離的加權平均值
rad:徑向高速公路的可達性指數
tax:每10,000美元的全額物業稅率
ptratio:城鎮的學生與教師比例
black:1000(Bk — 0.63)² 其中Bk是城鎮黑人的比例
lstat:人口較低的地位(百分比)
medv:自住房屋的中位數價值1000美元,這是目標變數
(3)輸入資料集包含有關各種房屋細節的資料。根據所提供的資訊,目標是提出一個模型來預測該地區特定房屋的中值。
載入資料
from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
sc= SparkContext()
sqlContext = SQLContext(sc)
house_df = sqlContext.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('boston.csv')
house_df.take(1)
[Row(ID=1, crim=0.00632, zn=18.0, indus=2.31, chas=0, nox=0.538, rm=6.575, age=65.2, dis=4.09, rad=1, tax=296, ptratio=15.3, black=396.9, lstat=4.98, medv=24.0)]
(4)以樹形模式列印資料
house_df.cache()
house_df.printSchema()

(5)執行描述性分析
house_df.describe().toPandas().transpose()
(6)散點矩陣可以粗略確定是否在多個自變數之間具有線性相關性
import pandas as pd
%matplotlib inline
numeric_features = [t[0] for t in house_df.dtypes if t[1] == 'int' or t[1] == 'double']
sampled_data = house_df.select(numeric_features).sample(False, 0.8).toPandas()
axs = pd.scatter_matrix(sampled_data, figsize=(10, 10))
n = len(sampled_data.columns)
for i in range(n):
v = axs[i, 0]
v.yaxis.label.set_rotation(0)
v.yaxis.label.set_ha('right')
v.set_yticks(())
h = axs[n-1, i]
h.xaxis.label.set_rotation(90)
h.set_xticks(())

(7)確定自變數和目標變數之間的相關性
import six
for i in house_df.columns:
if not( isinstance(house_df.select(i).take(1)[0][0], six.string_types)):
print( "Correlation to medv for ", i, house_df.stat.corr('medv',i))
相關係數的範圍從-1到1。當它接近1時,意味著存在強正相關;例如,當房間數量增加時,中值往往會上升。當係數接近-1時,意味著存在強烈的負相關; 當人口較低地位的百分比上升時,中值往往會下降。最後,接近零的係數意味著沒有線性相關。
(8)準備機器學習資料。(特徵feautures和標籤medv):
vhouse_df = vhouse_df.select(['features', 'medv'])
vhouse_df.show(3)

(9)切分資料集,70%資料作為訓練集,30%資料作為測試集。
splits = vhouse_df.randomSplit([0.7, 0.3])
train_df = splits[0]
test_df = splits[1]
(10)線性迴歸
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(featuresCol = 'features', labelCol='medv', maxIter=10, regParam=0.3, elasticNetParam=0.8)
lr_model = lr.fit(train_df)
print("Coefficients: " + str(lr_model.coefficients))#
print("Intercept: " + str(lr_model.intercept))
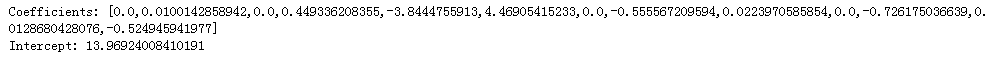
(11)訓練集上的評價指標:
trainingSummary = lr_model.summary
print("RMSE: %f" % trainingSummary.rootMeanSquaredError)
print("r2: %f" % trainingSummary.r2)
![]()
(12)RMSE通過模型和實際值測量預測值之間的差異。然而,在我們與實際的“medv”值(例如平均值,最小值和最大值)進行比較之前,僅RMSE是沒有意義的。
train_df.describe().show()
(13)R平方為0.71表明在我們的模型中,使用該模型可以解釋“medv”中大約71%的變異性。這與Scikit-Learn的結果一致。測試集上的表現與訓練集上有一些差異。
lr_predictions = lr_model.transform(test_df)
lr_predictions.select("prediction","medv","features").show(5)
from pyspark.ml.evaluation import RegressionEvaluator
lr_evaluator = RegressionEvaluator(predictionCol="prediction", \
labelCol="medv",metricName="r2")
print("R Squared (R2) on test data = %g" % lr_evaluator.evaluate(lr_predictions))

test_result = lr_model.evaluate(test_df)
print("Root Mean Squared Error (RMSE) on test data = %g" % test_result.rootMeanSquaredError)
Root Mean Squared Error (RMSE) on test data = 5.42683
(15)使用線性迴歸模型做一些預測:
predictions = lr_model.transform(test_df)
predictions.select("prediction","medv","features").show()
