
Spark效能優化:資料傾斜調優
資料傾斜調優
調優概述
有的時候,我們可能會遇到大資料計算中一個最棘手的問題——資料傾斜,此時Spark作業的效能會比期望差很多。資料傾斜調優,就是使用各種技術方案解決不同型別的資料傾斜問題,以保證Spark作業的效能。
資料傾斜發生時的現象
1、絕大多數task執行得都非常快,但個別task執行極慢。比如,總共有1000個task,997個task都在1分鐘之內執行完了,但是剩餘兩三個task卻要一兩個小時。這種情況很常見。
2、原本能夠正常執行的Spark作業,某天突然報出OOM(記憶體溢位)異常,觀察異常棧,是我們寫的業務程式碼造成的。這種情況比較少見。
資料傾斜發生的原理
資料傾斜的原理很簡單:在進行shuffle的時候,必須將各個節點上相同的key拉取到某個節點上的一個task來進行處理,比如按照key進行聚合或join等操作。此時如果某個key對應的資料量特別大的話,就會發生資料傾斜。比如大部分key對應10條資料,但是個別key卻對應了100萬條資料,那麼大部分task可能就只會分配到10條資料,然後1秒鐘就執行完了;但是個別task可能分配到了100萬資料,要執行一兩個小時。因此,整個Spark作業的執行進度是由執行時間最長的那個task決定的。
因此出現數據傾斜的時候,Spark作業看起來會執行得非常緩慢,甚至可能因為某個task處理的資料量過大導致記憶體溢位。
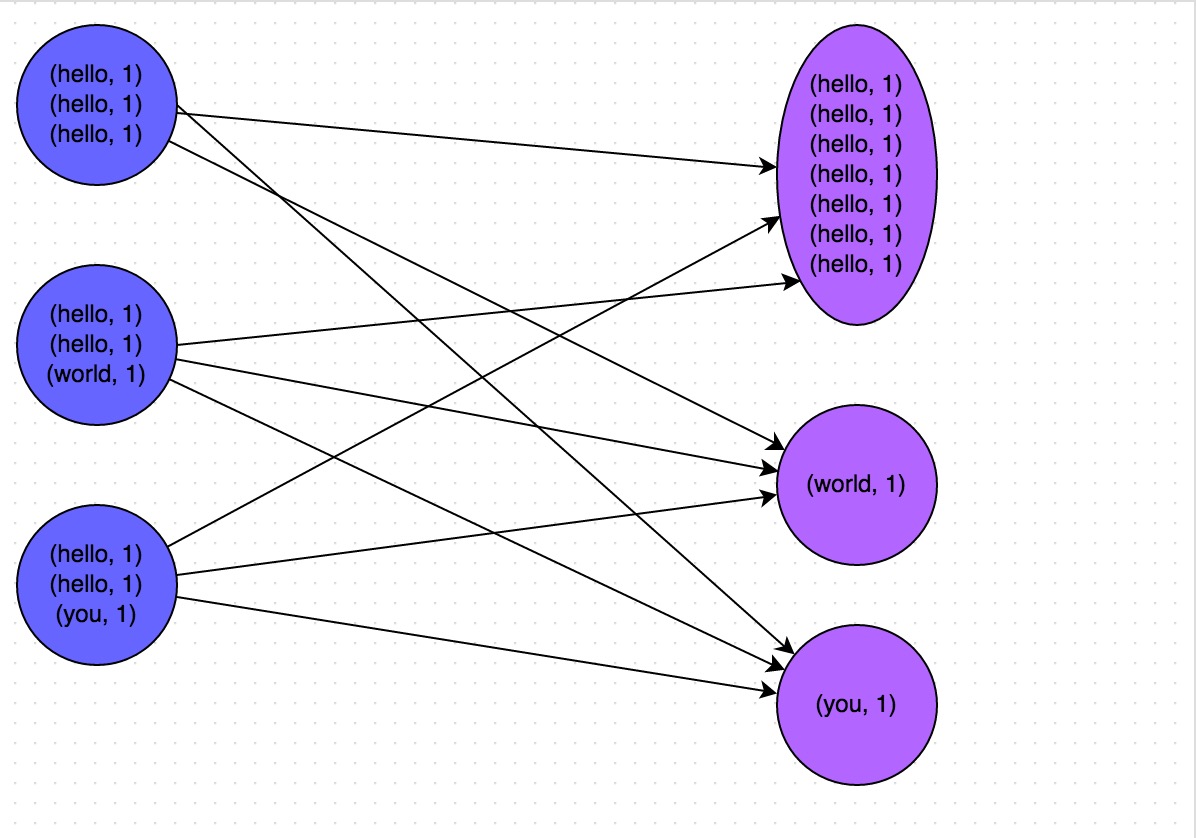
下圖就是一個很清晰的例子:hello這個key,在三個節點上對應了總共7條資料,這些資料都會被拉取到同一個task中進行處理;而world和you這兩個key分別才對應1條資料,所以另外兩個task只要分別處理1條資料即可。此時第一個task的執行時間可能是另外兩個task的7倍,而整個stage的執行速度也由執行最慢的那個task所決定。
如何定位導致資料傾斜的程式碼
資料傾斜只會發生在shuffle過程中。這裡給大家羅列一些常用的並且可能會觸發shuffle操作的運算元:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出現數據傾斜時,可能就是你的程式碼中使用了這些運算元中的某一個所導致的。
某個task執行特別慢的情況
首先要看的,就是資料傾斜發生在第幾個stage中。
如果是用yarn-client模式提交,那麼本地是直接可以看到log的,可以在log中找到當前執行到了第幾個stage;如果是用yarn-cluster模式提交,則可以通過Spark Web UI來檢視當前執行到了第幾個stage。此外,無論是使用yarn-client模式還是yarn-cluster模式,我們都可以在Spark Web UI上深入看一下當前這個stage各個task分配的資料量,從而進一步確定是不是task分配的資料不均勻導致了資料傾斜。
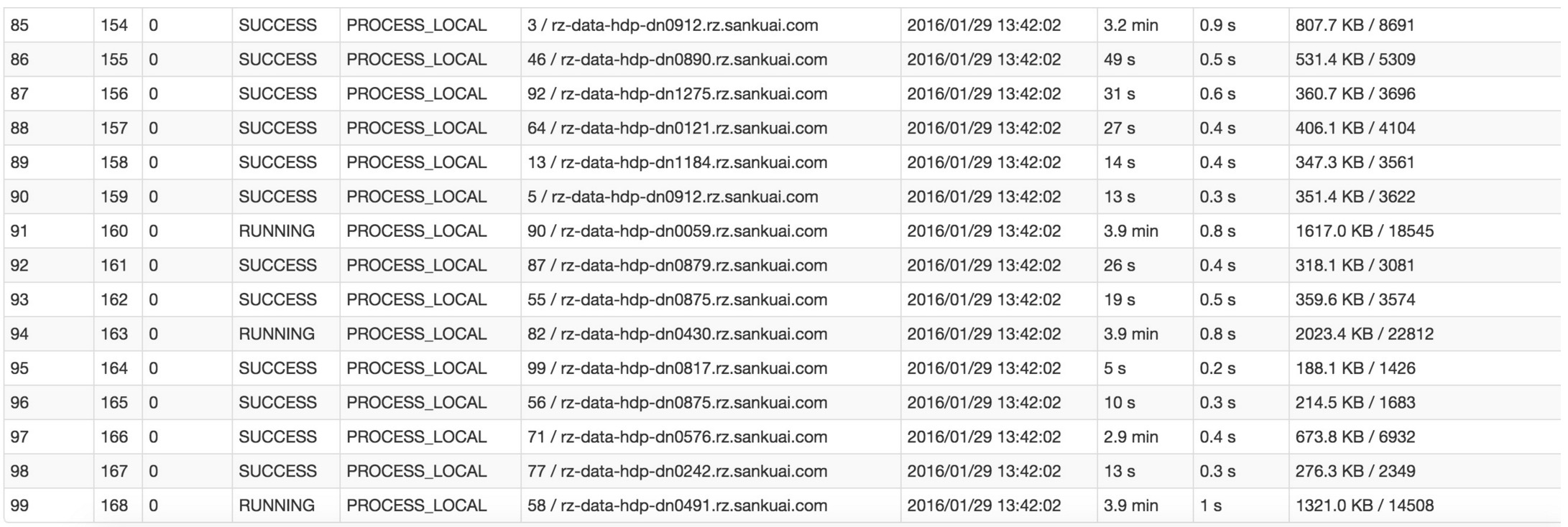
比如下圖中,倒數第三列顯示了每個task的執行時間。明顯可以看到,有的task執行特別快,只需要幾秒鐘就可以執行完;而有的task執行特別慢,需要幾分鐘才能執行完,此時單從執行時間上看就已經能夠確定發生資料傾斜了。此外,倒數第一列顯示了每個task處理的資料量,明顯可以看到,執行時間特別短的task只需要處理幾百KB的資料即可,而執行時間特別長的task需要處理幾千KB的資料,處理的資料量差了10倍。此時更加能夠確定是發生了資料傾斜。
知道資料傾斜發生在哪一個stage之後,接著我們就需要根據stage劃分原理,推算出來發生傾斜的那個stage對應程式碼中的哪一部分,這部分程式碼中肯定會有一個shuffle類運算元。精準推算stage與程式碼的對應關係,需要對Spark的原始碼有深入的理解,這裡我們可以介紹一個相對簡單實用的推算方法:只要看到Spark程式碼中出現了一個shuffle類運算元或者是Spark SQL的SQL語句中出現了會導致shuffle的語句(比如group by語句),那麼就可以判定,以那個地方為界限劃分出了前後兩個stage。
這裡我們就以Spark最基礎的入門程式——單詞計數來舉例,如何用最簡單的方法大致推算出一個stage對應的程式碼。如下示例,在整個程式碼中,只有一個reduceByKey是會發生shuffle的運算元,因此就可以認為,以這個運算元為界限,會劃分出前後兩個stage。
1、stage0,主要是執行從textFile到map操作,以及執行shuffle write操作。shuffle write操作,我們可以簡單理解為對pairs RDD中的資料進行分割槽操作,每個task處理的資料中,相同的key會寫入同一個磁碟檔案內。 2、stage1,主要是執行從reduceByKey到collect操作,stage1的各個task一開始執行,就會首先執行shuffle read操作。執行shuffle read操作的task,會從stage0的各個task所在節點拉取屬於自己處理的那些key,然後對同一個key進行全域性性的聚合或join等操作,在這裡就是對key的value值進行累加。stage1在執行完reduceByKey運算元之後,就計算出了最終的wordCounts RDD,然後會執行collect運算元,將所有資料拉取到Driver上,供我們遍歷和列印輸出。
|
|
通過對單詞計數程式的分析,希望能夠讓大家瞭解最基本的stage劃分的原理,以及stage劃分後shuffle操作是如何在兩個stage的邊界處執行的。然後我們就知道如何快速定位出發生資料傾斜的stage對應程式碼的哪一個部分了。比如我們在Spark Web UI或者本地log中發現,stage1的某幾個task執行得特別慢,判定stage1出現了資料傾斜,那麼就可以回到程式碼中定位出stage1主要包括了reduceByKey這個shuffle類運算元,此時基本就可以確定是由educeByKey運算元導致的資料傾斜問題。比如某個單詞出現了100萬次,其他單詞才出現10次,那麼stage1的某個task就要處理100萬資料,整個stage的速度就會被這個task拖慢。
某個task莫名其妙記憶體溢位的情況
這種情況下去定位出問題的程式碼就比較容易了。我們建議直接看yarn-client模式下本地log的異常棧,或者是通過YARN檢視yarn-cluster模式下的log中的異常棧。一般來說,通過異常棧資訊就可以定位到你的程式碼中哪一行發生了記憶體溢位。然後在那行程式碼附近找找,一般也會有shuffle類運算元,此時很可能就是這個運算元導致了資料傾斜。
但是大家要注意的是,不能單純靠偶然的記憶體溢位就判定發生了資料傾斜。因為自己編寫的程式碼的bug,以及偶然出現的資料異常,也可能會導致記憶體溢位。因此還是要按照上面所講的方法,通過Spark Web UI檢視報錯的那個stage的各個task的執行時間以及分配的資料量,才能確定是否是由於資料傾斜才導致了這次記憶體溢位。
檢視導致資料傾斜的key的資料分佈情況
知道了資料傾斜發生在哪裡之後,通常需要分析一下那個執行了shuffle操作並且導致了資料傾斜的RDD/Hive表,檢視一下其中key的分佈情況。這主要是為之後選擇哪一種技術方案提供依據。針對不同的key分佈與不同的shuffle運算元組合起來的各種情況,可能需要選擇不同的技術方案來解決。
此時根據你執行操作的情況不同,可以有很多種檢視key分佈的方式:
1、如果是Spark SQL中的group by、join語句導致的資料傾斜,那麼就查詢一下SQL中使用的表的key分佈情況。 2、如果是對Spark RDD執行shuffle運算元導致的資料傾斜,那麼可以在Spark作業中加入檢視key分佈的程式碼,比如RDD.countByKey()。然後對統計出來的各個key出現的次數,collect/take到客戶端列印一下,就可以看到key的分佈情況。
舉例來說,對於上面所說的單詞計數程式,如果確定了是stage1的reduceByKey運算元導致了資料傾斜,那麼就應該看看進行reduceByKey操作的RDD中的key分佈情況,在這個例子中指的就是pairs RDD。如下示例,我們可以先對pairs取樣10%的樣本資料,然後使用countByKey運算元統計出每個key出現的次數,最後在客戶端遍歷和列印樣本資料中各個key的出現次數。
|
|
資料傾斜的解決方案
解決方案一:使用Hive ETL預處理資料
方案適用場景:導致資料傾斜的是Hive表。如果該Hive表中的資料本身很不均勻(比如某個key對應了100萬資料,其他key才對應了10條資料),而且業務場景需要頻繁使用Spark對Hive表執行某個分析操作,那麼比較適合使用這種技術方案。
方案實現思路:此時可以評估一下,是否可以通過Hive來進行資料預處理(即通過Hive ETL預先對資料按照key進行聚合,或者是預先和其他表進行join),然後在Spark作業中針對的資料來源就不是原來的Hive表了,而是預處理後的Hive表。此時由於資料已經預先進行過聚合或join操作了,那麼在Spark作業中也就不需要使用原先的shuffle類運算元執行這類操作了。
方案實現原理:這種方案從根源上解決了資料傾斜,因為徹底避免了在Spark中執行shuffle類運算元,那麼肯定就不會有資料傾斜的問題了。但是這裡也要提醒一下大家,這種方式屬於治標不治本。因為畢竟資料本身就存在分佈不均勻的問題,所以Hive ETL中進行group by或者join等shuffle操作時,還是會出現資料傾斜,導致Hive ETL的速度很慢。我們只是把資料傾斜的發生提前到了Hive ETL中,避免Spark程式發生資料傾斜而已。
方案優點:實現起來簡單便捷,效果還非常好,完全規避掉了資料傾斜,Spark作業的效能會大幅度提升。
方案缺點:治標不治本,Hive ETL中還是會發生資料傾斜。
方案實踐經驗:在一些Java系統與Spark結合使用的專案中,會出現Java程式碼頻繁呼叫Spark作業的場景,而且對Spark作業的執行效能要求很高,就比較適合使用這種方案。將資料傾斜提前到上游的Hive ETL,每天僅執行一次,只有那一次是比較慢的,而之後每次Java呼叫Spark作業時,執行速度都會很快,能夠提供更好的使用者體驗。
專案實踐經驗:在美團·點評的互動式使用者行為分析系統中使用了這種方案,該系統主要是允許使用者通過Java Web系統提交資料分析統計任務,後端通過Java提交Spark作業進行資料分析統計。要求Spark作業速度必須要快,儘量在10分鐘以內,否則速度太慢,使用者體驗會很差。所以我們將有些Spark作業的shuffle操作提前到了Hive ETL中,從而讓Spark直接使用預處理的Hive中間表,儘可能地減少Spark的shuffle操作,大幅度提升了效能,將部分作業的效能提升了6倍以上。
解決方案二:過濾少數導致傾斜的key
方案適用場景:如果發現導致傾斜的key就少數幾個,而且對計算本身的影響並不大的話,那麼很適合使用這種方案。比如99%的key就對應10條資料,但是隻有一個key對應了100萬資料,從而導致了資料傾斜。
方案實現思路:如果我們判斷那少數幾個資料量特別多的key,對作業的執行和計算結果不是特別重要的話,那麼幹脆就直接過濾掉那少數幾個key。比如,在Spark SQL中可以使用where子句過濾掉這些key或者在Spark Core中對RDD執行filter運算元過濾掉這些key。如果需要每次作業執行時,動態判定哪些key的資料量最多然後再進行過濾,那麼可以使用sample運算元對RDD進行取樣,然後計算出每個key的數量,取資料量最多的key過濾掉即可。
方案實現原理:將導致資料傾斜的key給過濾掉之後,這些key就不會參與計算了,自然不可能產生資料傾斜。
方案優點:實現簡單,而且效果也很好,可以完全規避掉資料傾斜。
方案缺點:適用場景不多,大多數情況下,導致傾斜的key還是很多的,並不是只有少數幾個。
方案實踐經驗:在專案中我們也採用過這種方案解決資料傾斜。有一次發現某一天Spark作業在執行的時候突然OOM了,追查之後發現,是Hive表中的某一個key在那天資料異常,導致資料量暴增。因此就採取每次執行前先進行取樣,計算出樣本中資料量最大的幾個key之後,直接在程式中將那些key給過濾掉。
解決方案三:提高shuffle操作的並行度
方案適用場景:如果我們必須要對資料傾斜迎難而上,那麼建議優先使用這種方案,因為這是處理資料傾斜最簡單的一種方案。
方案實現思路:在對RDD執行shuffle運算元時,給shuffle運算元傳入一個引數,比如reduceByKey(1000),該引數就設定了這個shuffle運算元執行時shuffle read task的數量。對於Spark SQL中的shuffle類語句,比如group by、join等,需要設定一個引數,即spark.sql.shuffle.partitions,該引數代表了shuffle read task的並行度,該值預設是200,對於很多場景來說都有點過小。
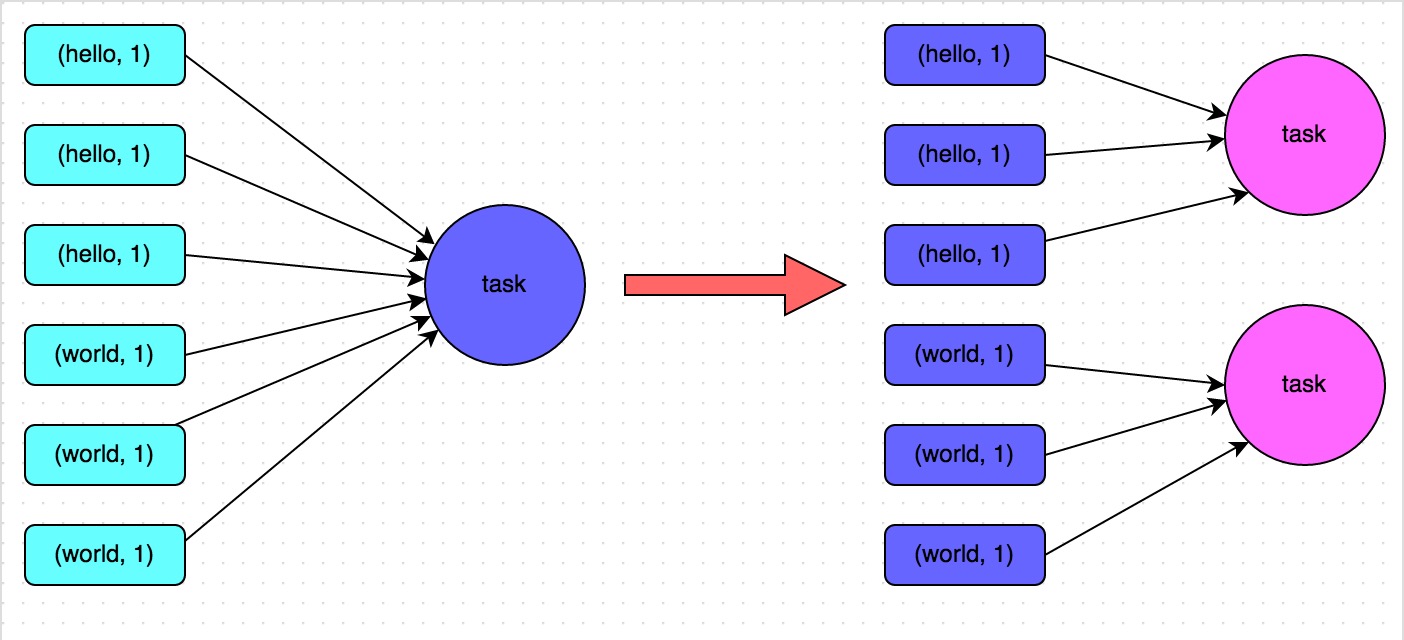
方案實現原理:增加shuffle read task的數量,可以讓原本分配給一個task的多個key分配給多個task,從而讓每個task處理比原來更少的資料。舉例來說,如果原本有5個key,每個key對應10條資料,這5個key都是分配給一個task的,那麼這個task就要處理50條資料。而增加了shuffle read task以後,每個task就分配到一個key,即每個task就處理10條資料,那麼自然每個task的執行時間都會變短了。具體原理如下圖所示。
方案優點:實現起來比較簡單,可以有效緩解和減輕資料傾斜的影響。
方案缺點:只是緩解了資料傾斜而已,沒有徹底根除問題,根據實踐經驗來看,其效果有限。
方案實踐經驗:該方案通常無法徹底解決資料傾斜,因為如果出現一些極端情況,比如某個key對應的資料量有100萬,那麼無論你的task數量增加到多少,這個對應著100萬資料的key肯定還是會分配到一個task中去處理,因此註定還是會發生資料傾斜的。所以這種方案只能說是在發現數據傾斜時嘗試使用的第一種手段,嘗試去用嘴簡單的方法緩解資料傾斜而已,或者是和其他方案結合起來使用。
解決方案四:兩階段聚合(區域性聚合+全域性聚合)
方案適用場景:對RDD執行reduceByKey等聚合類shuffle運算元或者在Spark SQL中使用group by語句進行分組聚合時,比較適用這種方案。
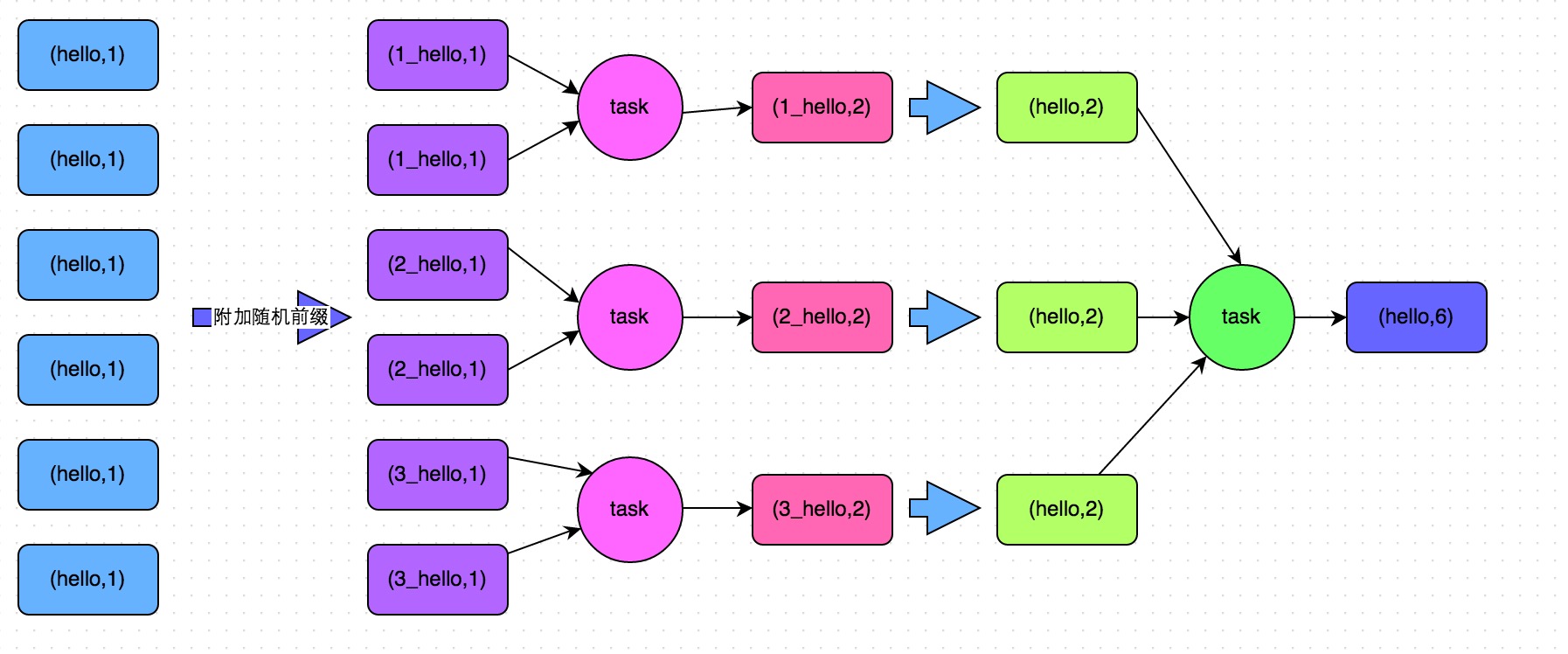
方案實現思路:這個方案的核心實現思路就是進行兩階段聚合。第一次是區域性聚合,先給每個key都打上一個隨機數,比如10以內的隨機數,此時原先一樣的key就變成不一樣的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就會變成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接著對打上隨機數後的資料,執行reduceByKey等聚合操作,進行區域性聚合,那麼區域性聚合結果,就會變成了(1_hello, 2) (2_hello, 2)。然後將各個key的字首給去掉,就會變成(hello,2)(hello,2),再次進行全域性聚合操作,就可以得到最終結果了,比如(hello, 4)。
方案實現原理:將原本相同的key通過附加隨機字首的方式,變成多個不同的key,就可以讓原本被一個task處理的資料分散到多個task上去做區域性聚合,進而解決單個task處理資料量過多的問題。接著去除掉隨機字首,再次進行全域性聚合,就可以得到最終的結果。具體原理見下圖。
方案優點:對於聚合類的shuffle操作導致的資料傾斜,效果是非常不錯的。通常都可以解決掉資料傾斜,或者至少是大幅度緩解資料傾斜,將Spark作業的效能提升數倍以上。
方案缺點:僅僅適用於聚合類的shuffle操作,適用範圍相對較窄。如果是join類的shuffle操作,還得用其他的解決方案。
|
|
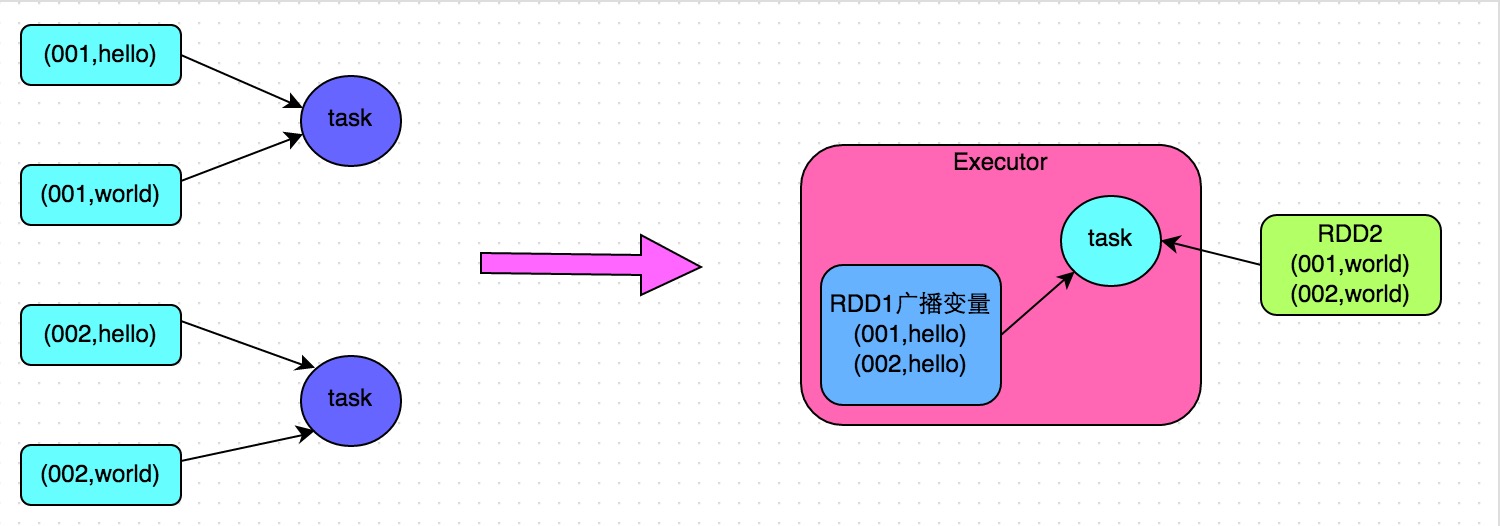
解決方案五:將reduce join轉為map join
方案適用場景:在對RDD使用join類操作,或者是在Spark SQL中使用join語句時,而且join操作中的一個RDD或表的資料量比較小(比如幾百M或者一兩G),比較適用此方案。
方案實現思路:不使用join運算元進行連線操作,而使用Broadcast變數與map類運算元實現join操作,進而完全規避掉shuffle類的操作,徹底避免資料傾斜的發生和出現。將較小RDD中的資料直接通過collect運算元拉取到Driver端的記憶體中來,然後對其建立一個Broadcast變數;接著對另外一個RDD執行map類運算元,在運算元函式內,從Broadcast變數中獲取較小RDD的全量資料,與當前RDD的每一條資料按照連線key進行比對,如果連線key相同的話,那麼就將兩個RDD的資料用你需要的方式連線起來。
方案實現原理:普通的join是會走shuffle過程的,而一旦shuffle,就相當於會將相同key的資料拉取到一個shuffle read task中再進行join,此時就是reduce join。但是如果一個RDD是比較小的,則可以採用廣播小RDD全量資料+map運算元來實現與join同樣的效果,也就是map join,此時就不會發生shuffle操作,也就不會發生資料傾斜。具體原理如下圖所示。
方案優點:對join操作導致的資料傾斜,效果非常好,因為根本就不會發生shuffle,也就根本不會發生資料傾斜。
方案缺點:適用場景較少,因為這個方案只適用於一個大表和一個小表的情況。畢竟我們需要將小表進行廣播,此時會比較消耗記憶體資源,driver和每個Executor記憶體中都會駐留一份小RDD的全量資料。如果我們廣播出去的RDD資料比較大,比如10G以上,那麼就可能發生記憶體溢位了。因此並不適合兩個都是大表的情況。
|
|
解決方案六:取樣傾斜key並分拆join操作
方案適用場景:兩個RDD/Hive表進行join的時候,如果資料量都比較大,無法採用“解決方案五”,那麼此時可以看一下兩個RDD/Hive表中的key分佈情況。如果出現數據傾斜,是因為其中某一個RDD/Hive表中的少數幾個key的資料量過大,而另一個RDD/Hive表中的所有key都分佈比較均勻,那麼採用這個解決方案是比較合適的。
方案實現思路:
1、對包含少數幾個資料量過大的key的那個RDD,通過sample運算元取樣出一份樣本來,然後統計一下每個key的數量,計算出來資料量最大的是哪幾個key。 2、然後將這幾個key對應的資料從原來的RDD中拆分出來,形成一個單獨的RDD,並給每個key都打上n以內的隨機數作為字首,而不會導致傾斜的大部分key形成另外一個RDD。 3、接著將需要join的另一個RDD,也過濾出來那幾個傾斜key對應的資料並形成一個單獨的RDD,將每條資料膨脹成n條資料,這n條資料都按順序附加一個0~n的字首,不會導致傾斜的大部分key也形成另外一個RDD。 4、再將附加了隨機字首的獨立RDD與另一個膨脹n倍的獨立RDD進行join,此時就可以將原先相同的key打散成n份,分散到多個task中去進行join了。 5、而另外兩個普通的RDD就照常join即可。 6、最後將兩次join的結果使用union運算元合併起來即可,就是最終的join結果。
方案實現原理:對於join導致的資料傾斜,如果只是某幾個key導致了傾斜,可以將少數幾個key分拆成獨立RDD,並附加隨機字首打散成n份去進行join,此時這幾個key對應的資料就不會集中在少數幾個task上,而是分散到多個task進行join了。具體原理見下圖。
方案優點:對於join導致的資料傾斜,如果只是某幾個key導致了傾斜,採用該方式可以用最有效的方式打散key進行join。而且只需要針對少數傾斜key對應的資料進行擴容n倍,不需要對全量資料進行擴容。避免了佔用過多記憶體。
方案缺點:如果導致傾斜的key特別多的話,比如成千上萬個key都導致資料傾斜,那麼這種方式也不適合。

|
|
解決方案七:使用隨機字首和擴容RDD進行join
方案適用場景:如果在進行join操作時,RDD中有大量的key導致資料傾斜,那麼進行分拆key也沒什麼意義,此時就只能使用最後一種方案來解決問題了。
方案實現思路:
1、該方案的實現思路基本和“解決方案六”類似,首先檢視RDD/Hive表中的資料分佈情況,找到那個造成資料傾斜的RDD/Hive表,比如有多個key都對應了超過1萬條資料。 2、然後將該RDD的每條資料都打上一個n以內的隨機字首。 3、同時對另外一個正常的RDD進行擴容,將每條資料都擴容成n條資料,擴容出來的每條資料都依次打上一個0~n的字首。 4、最後將兩個處理後的RDD進行join即可。
方案實現原理:將原先一樣的key通過附加隨機字首變成不一樣的key,然後就可以將這些處理後的“不同key”分散到多個task中去處理,而不是讓一個task處理大量的相同key。該方案與“解決方案六”的不同之處就在於,上一種方案是儘量只對少數傾斜key對應的資料進行特殊處理,由於處理過程需要擴容RDD,因此上一種方案擴容RDD後對記憶體的佔用並不大;而這一種方案是針對有大量傾斜key的情況,沒法將部分key拆分出來進行單獨處理,因此只能對整個RDD進行資料擴容,對記憶體資源要求很高。
方案優點:對join型別的資料傾斜基本都可以處理,而且效果也相對比較顯著,效能提升效果非常不錯。
方案缺點:該方案更多的是緩解資料傾斜,而不是徹底避免資料傾斜。而且需要對整個RDD進行擴容,對記憶體資源要求很高。
方案實踐經驗:曾經開發一個數據需求的時候,發現一個join導致了資料傾斜。優化之前,作業的執行時間大約是60分鐘左右;使用該方案優化之後,執行時間縮短到10分鐘左右,效能提升了6倍。
|
|
解決方案八:多種方案組合使用
在實踐中發現,很多情況下,如果只是處理較為簡單的資料傾斜場景,那麼使用上述方案中的某一種基本就可以解決。但是如果要處理一個較為複雜的資料傾斜場景,那麼可能需要將多種方案組合起來使用。比如說,我們針對出現了多個數據傾斜環節的Spark作業,可以先運用解決方案一和二,預處理一部分資料,並過濾一部分資料來緩解;其次可以對某些shuffle操作提升並行度,優化其效能;最後還可以針對不同的聚合或join操作,選擇一種方案來優化其效能。大家需要對這些方案的思路和原理都透徹理解之後,在實踐中根據各種不同的情況,靈活運用多種方案,來解決自己的資料傾斜問題。