
決策樹模型 ID3/C4.5/CART演算法比較
決策樹模型在監督學習中非常常見,可用於分類(二分類、多分類)和迴歸。雖然將多棵弱決策樹的Bagging、Random Forest、Boosting等tree ensembel 模型更為常見,但是“完全生長”決策樹因為其簡單直觀,具有很強的解釋性,也有廣泛的應用,而且決策樹是tree ensemble 的基礎,值得好好理解。一般而言一棵“完全生長”的決策樹包含,特徵選擇、決策樹構建、剪枝三個過程,這篇文章主要是簡單梳理比較ID3、C4.5、CART演算法。《統計學習方法》中有比較詳細的介紹。
一、決策樹的優點和缺點
優點:
- 決策樹演算法中學習簡單的決策規則建立決策樹模型的過程非常容易理解,
- 決策樹模型可以視覺化,非常直觀
- 應用範圍廣,可用於分類和迴歸,而且非常容易做多類別的分類
- 能夠處理數值型和連續的樣本特徵
缺點:
- 很容易在訓練資料中生成複雜的樹結構,造成過擬合(overfitting)。剪枝可以緩解過擬合的負作用,常用方法是限制樹的高度、葉子節點中的最少樣本數量。
- 學習一棵最優的決策樹被認為是NP-Complete問題。實際中的決策樹是基於啟發式的貪心演算法建立的,這種演算法不能保證建立全域性最優的決策樹。Random Forest 引入隨機能緩解這個問題
二、ID3演算法
ID3由Ross Quinlan在1986年提出。ID3決策樹可以有多個分支,但是不能處理特徵值為連續的情況。決策樹是一種貪心演算法,每次選取的分割資料的特徵都是當前的最佳選擇,並不關心是否達到最優。在ID3中,每次根據“最大資訊熵增益”選取當前最佳的特徵來分割資料,並按照該特徵的所有取值來切分,也就是說如果一個特徵有4種取值,資料將被切分4份,一旦按某特徵切分後,該特徵在之後的演算法執行中,將不再起作用,所以有觀點認為這種切分方式過於迅速。ID3演算法十分簡單,核心是根據“最大資訊熵增益”原則選擇劃分當前資料集的最好特徵,資訊熵是資訊理論裡面的概念,是資訊的度量方式,不確定度越大或者說越混亂,熵就越大。在建立決策樹的過程中,根據特徵屬性劃分資料,使得原本“混亂”的資料的熵(混亂度)減少,按照不同特徵劃分資料熵減少的程度會不一樣。在ID3中選擇熵減少程度最大的特徵來劃分資料(貪心),也就是“最大資訊熵增益”原則。下面是計算公式,建議看

三、C4.5演算法
C4.5是Ross Quinlan在1993年在ID3的基礎上改進而提出的。.ID3採用的資訊增益度量存在一個缺點,它一般會優先選擇有較多屬性值的Feature,因為屬性值多的Feature會有相對較大的資訊增益?(資訊增益反映的給定一個條件以後不確定性減少的程度,必然是分得越細的資料集確定性更高,也就是條件熵越小,資訊增益越大).為了避免這個不足C4.5中是用資訊增益比率(gain ratio)來作為選擇分支的準則。資訊增益比率通過引入一個被稱作分裂資訊(Split information)的項來懲罰取值較多的Feature。除此之外,C4.5還彌補了ID3中不能處理特徵屬性值連續的問題。但是,對連續屬性值需要掃描排序,會使C4.5效能下降,有興趣可以參考
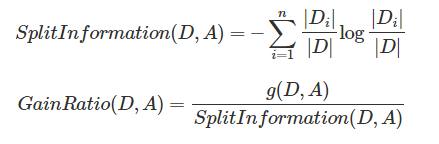
五、CART演算法
CART(Classification and Regression tree)分類迴歸樹由L.Breiman,J.Friedman,R.Olshen和C.Stone於1984年提出。ID3中根據屬性值分割資料,之後該特徵不會再起作用,這種快速切割的方式會影響演算法的準確率。CART是一棵二叉樹,採用二元切分法,每次把資料切成兩份,分別進入左子樹、右子樹。而且每個非葉子節點都有兩個孩子,所以CART的葉子節點比非葉子多1。相比ID3和C4.5,CART應用要多一些,既可以用於分類也可以用於迴歸。CART分類時,使用基尼指數(Gini)來選擇最好的資料分割的特徵,gini描述的是純度,與資訊熵的含義相似。CART中每一次迭代都會降低GINI係數。下圖顯示資訊熵增益的一半,Gini指數,分類誤差率三種評價指標非常接近。迴歸時使用均方差作為loss function。基尼係數的計算與資訊熵增益的方式非常類似,公式如下
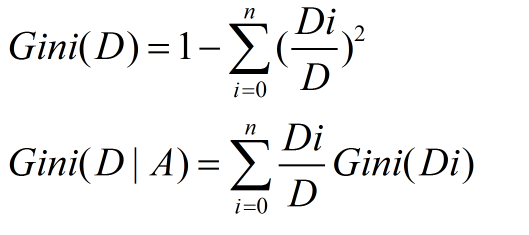
六、分類樹 VS 迴歸樹
提到決策樹演算法,很多想到的就是上面提到的ID3、C4.5、CART分類決策樹。其實決策樹分為分類樹和迴歸樹,前者用於分類,如晴天/陰天/雨天、使用者性別、郵件是否是垃圾郵件,後者用於預測實數值,如明天的溫度、使用者的年齡等。
作為對比,先說分類樹,我們知道ID3、C4.5分類樹在每次分枝時,是窮舉每一個特徵屬性的每一個閾值,找到使得按照feature<=閾值,和feature>閾值分成的兩個分枝的熵最大的feature和閾值。按照該標準分枝得到兩個新節點,用同樣方法繼續分枝直到所有人都被分入性別唯一的葉子節點,或達到預設的終止條件,若最終葉子節點中的性別不唯一,則以多數人的性別作為該葉子節點的性別。
迴歸樹總體流程也是類似,不過在每個節點(不一定是葉子節點)都會得一個預測值,以年齡為例,該預測值等於屬於這個節點的所有人年齡的平均值。分枝時窮舉每一個feature的每個閾值找最好的分割點,但衡量最好的標準不再是最大熵,而是最小化均方差--即(每個人的年齡-預測年齡)^2 的總和 / N,或者說是每個人的預測誤差平方和 除以 N。這很好理解,被預測出錯的人數越多,錯的越離譜,均方差就越大,通過最小化均方差能夠找到最靠譜的分枝依據。分枝直到每個葉子節點上人的年齡都唯一(這太難了)或者達到預設的終止條件(如葉子個數上限),若最終葉子節點上人的年齡不唯一,則以該節點上所有人的平均年齡做為該葉子節點的預測年齡。