
【4opencv】識別複雜的答題卡1(主要演算法)
阿新 • • 發佈:2018-12-15
一、問題提出
 下一步就是需要從這張圖片中,識別出人眼識別出來的那些資訊,並且將這個過程儘可能地魯棒化,提高識別的準確率。
二、思路探索
在從圖片到數字的轉變過程中,既是一個“量化”的過程,也是一個“降維”的過程,需要特定的角度非常重要。這就像很多人站在一起拍集體照,選擇不同的角度能夠得到這群人不同的像,高明的攝像師能夠很快地找到角度,將所有的人都拍攝其中;我們影象處理程式也是同樣的道理,有經驗的工程師能夠善於模式思考,快速找到解決方法的途徑。
對於我們這裡的這張答題卡圖片,和之前的較為簡單的答題卡想比較,有很多不同,比較兩者的二值圖片,就可以發現:
下一步就是需要從這張圖片中,識別出人眼識別出來的那些資訊,並且將這個過程儘可能地魯棒化,提高識別的準確率。
二、思路探索
在從圖片到數字的轉變過程中,既是一個“量化”的過程,也是一個“降維”的過程,需要特定的角度非常重要。這就像很多人站在一起拍集體照,選擇不同的角度能夠得到這群人不同的像,高明的攝像師能夠很快地找到角度,將所有的人都拍攝其中;我們影象處理程式也是同樣的道理,有經驗的工程師能夠善於模式思考,快速找到解決方法的途徑。
對於我們這裡的這張答題卡圖片,和之前的較為簡單的答題卡想比較,有很多不同,比較兩者的二值圖片,就可以發現:

 最大的不同在於沒有可以供標定的基礎點。因此我們必須採用其它的方法來進行定位。
此外,答題區域為矩形密集分佈,因此我想到的是直接“網格化”進行處理。
三、演算法過程和主要程式碼
step1:灰度-二值-形態學
最大的不同在於沒有可以供標定的基礎點。因此我們必須採用其它的方法來進行定位。
此外,答題區域為矩形密集分佈,因此我想到的是直接“網格化”進行處理。
三、演算法過程和主要程式碼
step1:灰度-二值-形態學


 step2:輪廓分析
對識別出來的二值影象通過輪廓進一步地進行處理,得到下圖的識別結果,就為下一步定量打下基礎
step2:輪廓分析
對識別出來的二值影象通過輪廓進一步地進行處理,得到下圖的識別結果,就為下一步定量打下基礎

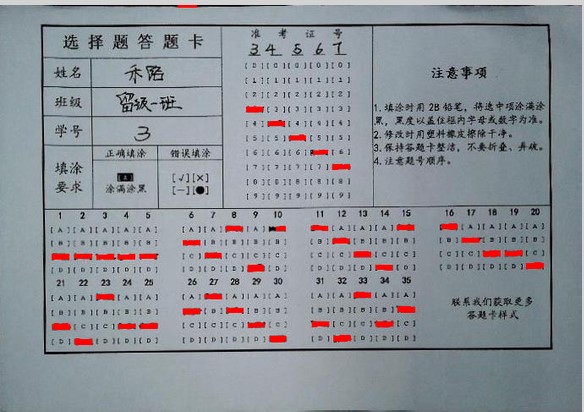 step3:模板匹配
想得到識別的結果,首先就是需要對現有的圖片進行分割出來。在沒有定位點的前提下,如何準確切割?
step3:模板匹配
想得到識別的結果,首先就是需要對現有的圖片進行分割出來。在沒有定位點的前提下,如何準確切割?
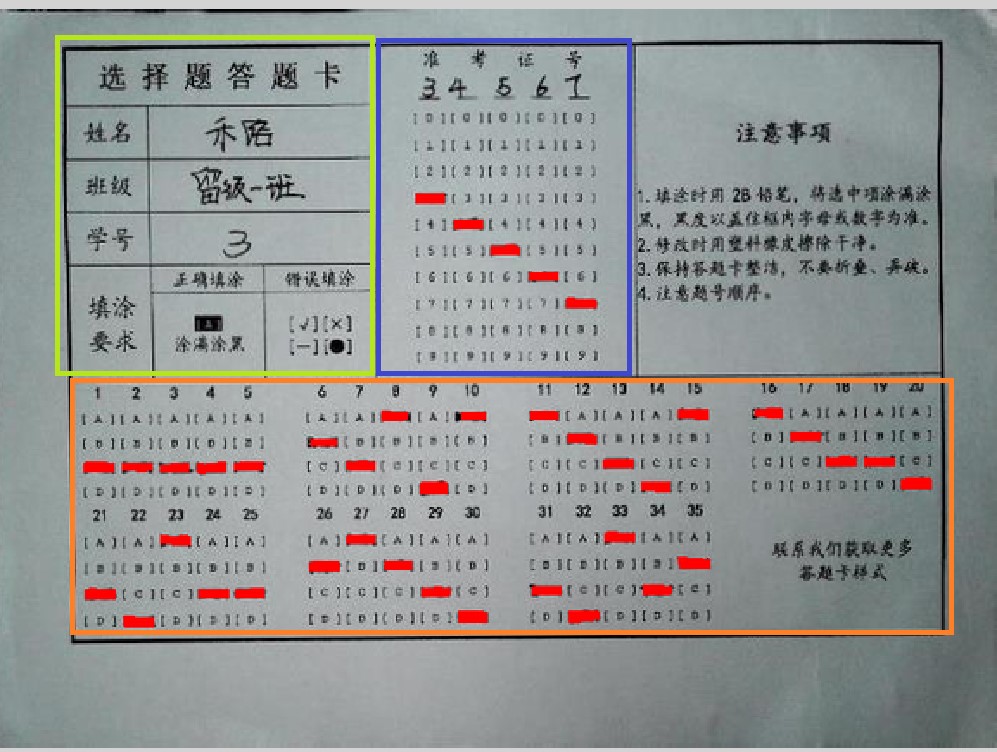 根據以前的經驗,基本的思路是這樣:
a、根據模板識別,準確的獲得可定位地址(比如我選擇使用“選擇題答題卡”幾個字作為模板,得到下圖定位結果,注意圖中白點);
根據以前的經驗,基本的思路是這樣:
a、根據模板識別,準確的獲得可定位地址(比如我選擇使用“選擇題答題卡”幾個字作為模板,得到下圖定位結果,注意圖中白點);

 細節:
細節:
 編寫以下程式碼:
編寫以下程式碼:
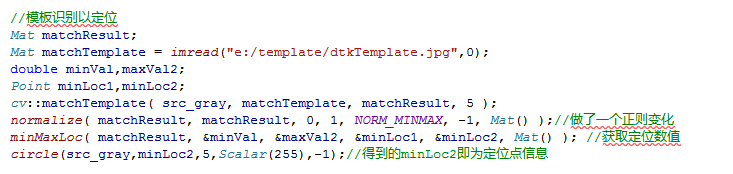 得到以下結果:
得到以下結果:
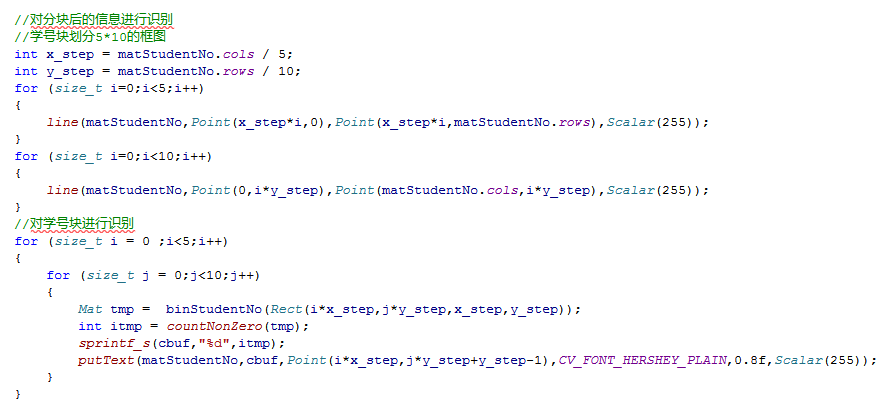
 step4:分塊面積識別
直接識別劃分區域的面積,得到定量結果
step4:分塊面積識別
直接識別劃分區域的面積,得到定量結果

 全圖:
全圖:
 細節:
細節:
 step5:轉化得到識別結果
編寫相關識別的結果為:
step5:轉化得到識別結果
編寫相關識別的結果為:

 四、需要注意的地方:
1、模板識別對於不同尺度採集的圖片,是否具有通用性。故我需要在不同的圖片、不同的採集模式下進行探索;
2、目前識別出來的結果缺乏對答題結果“重複”“遺漏”情況分析;
3、我們看見的是彩色或者灰度影象,實際上,需要識別出來的是bin區域。在實驗的過程中,我們會用到“彩色或者灰度”作為背景。
四、需要注意的地方:
1、模板識別對於不同尺度採集的圖片,是否具有通用性。故我需要在不同的圖片、不同的採集模式下進行探索;
2、目前識別出來的結果缺乏對答題結果“重複”“遺漏”情況分析;
3、我們看見的是彩色或者灰度影象,實際上,需要識別出來的是bin區域。在實驗的過程中,我們會用到“彩色或者灰度”作為背景。
由於GPY進行了糾偏,所以在採集的時候,就已經獲得了質量較高的答題卡圖片
下一步就是需要從這張圖片中,識別出人眼識別出來的那些資訊,並且將這個過程儘可能地魯棒化,提高識別的準確率。
二、思路探索
在從圖片到數字的轉變過程中,既是一個“量化”的過程,也是一個“降維”的過程,需要特定的角度非常重要。這就像很多人站在一起拍集體照,選擇不同的角度能夠得到這群人不同的像,高明的攝像師能夠很快地找到角度,將所有的人都拍攝其中;我們影象處理程式也是同樣的道理,有經驗的工程師能夠善於模式思考,快速找到解決方法的途徑。
對於我們這裡的這張答題卡圖片,和之前的較為簡單的答題卡想比較,有很多不同,比較兩者的二值圖片,就可以發現:
最大的不同在於沒有可以供標定的基礎點。因此我們必須採用其它的方法來進行定位。
此外,答題區域為矩形密集分佈,因此我想到的是直接“網格化”進行處理。
三、演算法過程和主要程式碼
step1:灰度-二值-形態學
step2:輪廓分析
對識別出來的二值影象通過輪廓進一步地進行處理,得到下圖的識別結果,就為下一步定量打下基礎
step3:模板匹配
想得到識別的結果,首先就是需要對現有的圖片進行分割出來。在沒有定位點的前提下,如何準確切割?
根據以前的經驗,基本的思路是這樣:
a、根據模板識別,準確的獲得可定位地址(比如我選擇使用“選擇題答題卡”幾個字作為模板,得到下圖定位結果,注意圖中白點);
細節:
編寫以下程式碼:
得到以下結果:
step4:分塊面積識別
直接識別劃分區域的面積,得到定量結果
全圖:
細節:
step5:轉化得到識別結果
編寫相關識別的結果為:
四、需要注意的地方:
1、模板識別對於不同尺度採集的圖片,是否具有通用性。故我需要在不同的圖片、不同的採集模式下進行探索;
2、目前識別出來的結果缺乏對答題結果“重複”“遺漏”情況分析;
3、我們看見的是彩色或者灰度影象,實際上,需要識別出來的是bin區域。在實驗的過程中,我們會用到“彩色或者灰度”作為背景。