
Python爬蟲入門教程 9-100 河北陽光理政投訴板塊
寫在前面
之前幾篇文章都是在寫圖片相關的爬蟲,今天寫個留言板爬出,為另一套資料分析案例的教程做做準備,作為一個河北人,遵紀守法,有事投訴是必備的技能,那麼咱看看我們大河北人都因為什麼投訴過呢?
今天要爬取的網站地址 http://yglz.tousu.hebnews.cn/l-1001-5-,一遍爬取一遍嘀咕,別因為爬這個網站在去喝茶,再次宣告,學習目的,切勿把人家網站爬癱瘓了。

開始擼程式碼
今天再次嘗試使用一個新的模組 lxml ,它可以配合xpath快速解析HTML文件,官網網站 https://lxml.de/index.html
利用pip安裝lxml,如果安裝失敗,可以在搜尋引擎多搜搜,內容很多,100%有解決方案。
pip install lxml
廢話不多說,直接通過requests模組獲取百度首頁,然後用lxml進行解析
import requests
from lxml import etree # 從lxml中匯入etree
response = requests.get("http://www.baidu.com")
html = response.content.decode("utf-8")
tree=etree.HTML(html) # 解析html
print(tree)
當你列印的內容為下圖所示,你就接近成功了!

下面就是 配合xpath 語法獲取網頁元素了,關於xpath
通過xpath我們進行下一步的操作,程式碼註釋可以多看一下。
tree=etree.HTML(html) # 解析html
hrefs = tree.xpath('//a') #通過xpath獲取所有的a元素
# 注意網頁中有很多的a標籤,所以獲取到的是一個數組,那麼我們需要用迴圈進行操作
for href in hrefs:
print(href)
列印結果如下
<Element a at 0x1cf64252408> <Element a at 0x1cf642523c8> <Element a at 0x1cf64252288> <Element a at 0x1cf64252308> <Element a at 0x1cf64285708> <Element a at 0x1cf642aa108> <Element a at 0x1cf642aa0c8> <Element a at 0x1cf642aa148> <Element a at 0x1cf642aa048> <Element a at 0x1cf64285848> <Element a at 0x1cf642aa188>
在使用xpath配合lxml中,記住只要輸出上述內容,就代表獲取到東西了,當然這個不一定是你需要的,不過程式碼至少是沒有錯誤的。
繼續編寫程式碼
# 注意網頁中有很多的a標籤,所以獲取到的是一個數組,那麼我們需要用迴圈進行操作
for href in hrefs:
print(href)
print(href.get("href")) # 獲取html元素屬性
print(href.text) # 獲取a標籤內部文字
輸出結果
<Element a at 0x1c7b76c2408>
http://news.baidu.com
新聞
<Element a at 0x1c7b76c23c8>
http://www.hao123.com
hao123
<Element a at 0x1c7b76c2288>
http://map.baidu.com
地圖
<Element a at 0x1c7b76c2308>
http://v.baidu.com
視訊
<Element a at 0x1c7b76f5708>
http://tieba.baidu.com
貼吧
現在你已經看到,我們已經獲取到了百度首頁的所有a標籤,並且獲取到了a標籤的href屬性和a標籤的文字。有這些內容,你就能很容易的去獲取我們的目標網站了。
爬取投訴資料
找到我們的目標網頁,結果發現,出事情了,頁面竟然是用aspx動態生成的,技術你就不需要研究了,總之,碰到了一個比較小的問題。
首先,點選下一頁的時候,頁面是區域性重新整理的

post方式,這個需要留意一下,最要緊的是下面第2張圖片和第3張圖片。
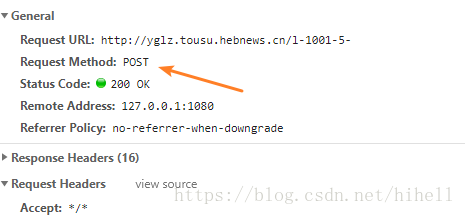
viewstate
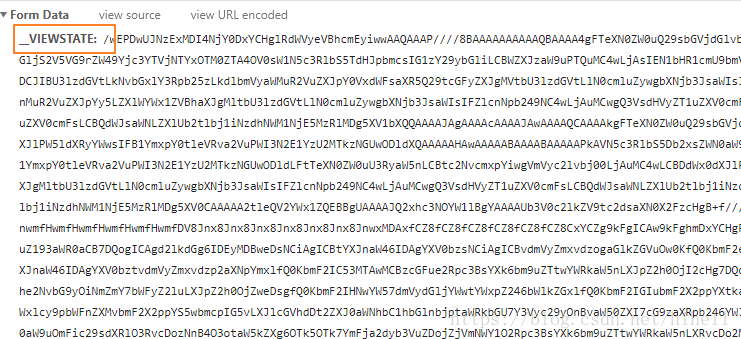
這張圖片也有一些奇怪的引數

這些引數都是典型的動態網頁引數。
解決這個問題,還要從源頭抓起!

開啟我們要爬取的首頁http://yglz.tousu.hebnews.cn/l-1001-5- 第1點需要確定,post的地址經過分析就是這個頁面。
所以這段程式碼是必備的了,注意下面的post
response = requests.post("http://yglz.tousu.hebnews.cn/l-1001-5-")
html = response.content.decode("utf-8")
右鍵檢視原始碼之後,發現原始碼中有一些比較重要的隱藏域 裡面獲取就是我們要的必備資訊

- 獲取原始碼
- lxml通過xpath解析隱藏域,取值
import requests
from lxml import etree # 從lxml中匯入etree
try:
response = requests.post("http://yglz.tousu.hebnews.cn/l-1001-5-")
html = response.content.decode("utf-8")
except Exception as e:
print(e)
tree=etree.HTML(html) # 解析html
hids = tree.xpath('//input[@type="hidden"]') # 獲取隱藏域
# 宣告一個字典,用來儲存後面的資料
common_param = {}
# 迴圈取值
for ipt in hids:
common_param.update({ipt.get("name"):ipt.get("value")}) # 這個地方可以分開寫,應該會很清楚,我就不寫了,總之,就是把上面獲取到的隱藏域的name屬性和value屬性都獲取到了
上面的程式碼寫完之後,其實已經完成了,非常核心的內容了,後面就是繼續爬取了
我們按照post要的引數補充完整其他的引數即可
import requests
from lxml import etree # 從lxml中匯入etree
try:
response = requests.post("http://yglz.tousu.hebnews.cn/l-1001-5-")
html = response.content.decode("utf-8")
except Exception as e:
print(e)
tree=etree.HTML(html) # 解析html
hids = tree.xpath('//input[@type="hidden"]')
common_param = {}
for ipt in hids:
common_param.update({ipt.get("name"):ipt.get("value")})
##############################################################
for i in range(1,691):
common_param.update({"__CALLBACKPARAM":f"Load|*|{i}", # 注意這個地方,由於我直接看到了總共有690頁資料,所以直接寫死了迴圈次數
"__CALLBACKID": "__Page",
"__EVENTTARGET":"",
"__EVENTARGUMENT":""})
到這一步,就可以抓取真實的資料了,我在下面的程式碼中最關鍵的一些地方加上註釋,希望你能看懂
for i in range(1,691):
common_param.update({"__CALLBACKPARAM":f"Load|*|{i}",
"__CALLBACKID": "__Page",
"__EVENTTARGET":"",
"__EVENTARGUMENT":""})
response = requests.post("http://yglz.tousu.hebnews.cn/l-1001-5-",data=common_param,headers=headers)
html = response.content.decode("utf-8")
print("*"*200)
tree = etree.HTML(html) # 解析html
divs = tree.xpath('//div[@class="listcon"]') # 解析列表區域div
for div in divs: # 迴圈這個區域
try:
# 注意下面是通過div去進行的xpath查詢,同時加上try方式報錯
shouli = div.xpath('span[1]/p/a/text()')[0] # 受理單位
type = div.xpath('span[2]/p/text()')[0].replace("\n","") # 投訴型別
content = div.xpath('span[3]/p/a/text()')[0] # 投訴內容
datetime = div.xpath('span[4]/p/text()')[0].replace("\n","") # 時間
status = div.xpath('span[6]/p/text()')[0].replace("\n","") # 時間
one_data = {"shouli":shouli,
"type":type,
"content":content,
"datetime":datetime,
"status":status,
}
print(one_data) # 列印資料,方便儲存到mongodb裡面
except Exception as e:
print("內部資料報錯")
print(div)
continue
程式碼完成,非常爽

最後抓取到了 13765 條資料,官方在我抓取的時候是13790,差了25條資料,沒有大的影響~
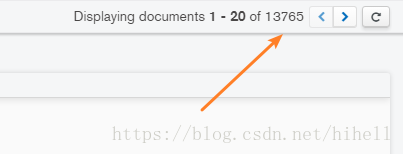
資料我都儲存在了 mongodb裡面,關於這個如何使用,請去看我以前的程式碼吧~~~~

這些資料,放著以後做資料分析用了。