
如何自己實現一個scrapy框架——框架雛形(一)
#一、瞭解框架
##1、首先明確一下,什麼是框架:
框架是為了為解決一類問題而開發的程式,框架兩個字可以分開理解,框:表示指定解決問題的邊界,明確要解決的問題;架:表達的是能夠提供一定的支撐性和可擴充套件性;從而實現解決這類問題達到快速開發的目的。
##2、實現框架的好處是什麼
2.1現成開源第三方框架的侷限性
現成開源第三方框架是為了儘可能滿足大部分的需求,不可能做到面面俱到,以及第三方框架的除錯相對複雜
2.2解決特定的工作需求
工作中會有很多特殊的需求,會經常使用某種套路去實現這些需求,那麼為了提高效率可以專門把這種套路封裝成一個框架
比如專門針對電商網站、新聞資訊寫一個爬蟲框架;再比如針對斷點續爬、增量抓取等需求寫一個框架
2.3提高自己的技術能力
不一定需要親自造輪子,但是應該知道如何造輪子
#二、框架設計思路
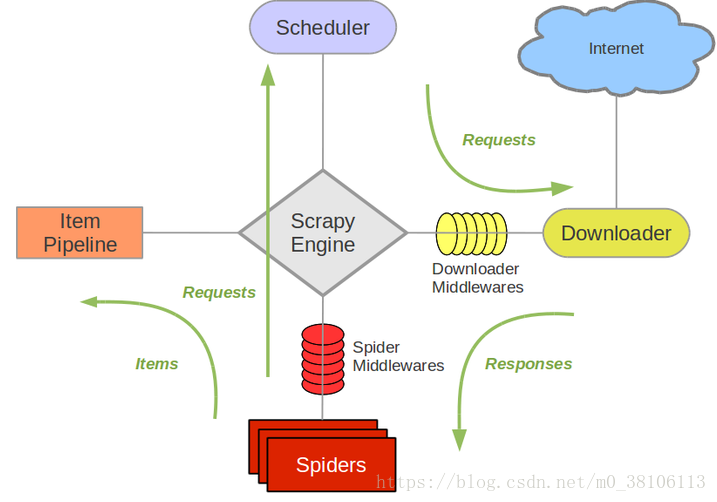 從上圖可以看出,scrapy分為:
(1)三個內建物件
請求物件(Request)
響應物件(Response)
資料物件(Item)
(2)五個核心元件
爬蟲元件
構建請求資訊(初始的),也就是生成請求物件(Request)
解析響應物件,返回資料物件(Item)或者新的請求物件(Request)
排程器元件
快取請求物件(Request),併為下載器提供請求物件,實現請求的排程
對請求物件進行去重判斷
下載器元件
根據請求物件(Request),發起HTTP、HTTPS網路請求,
拿到HTTP、HTTPS響應,構建響應物件(Response)並返回
管道元件
負責處理資料物件(Item)
引擎元件
負責驅動各大元件,通過呼叫各自對外提供的API介面,實現它們之間的互動和協作
提供整個框架的啟動入口
(3)兩個中介軟體
爬蟲中介軟體
對請求物件和資料物件進行預處理
下載器中介軟體
對請求物件和響應物件進行預處理
從上圖可以看出,scrapy分為:
(1)三個內建物件
請求物件(Request)
響應物件(Response)
資料物件(Item)
(2)五個核心元件
爬蟲元件
構建請求資訊(初始的),也就是生成請求物件(Request)
解析響應物件,返回資料物件(Item)或者新的請求物件(Request)
排程器元件
快取請求物件(Request),併為下載器提供請求物件,實現請求的排程
對請求物件進行去重判斷
下載器元件
根據請求物件(Request),發起HTTP、HTTPS網路請求,
拿到HTTP、HTTPS響應,構建響應物件(Response)並返回
管道元件
負責處理資料物件(Item)
引擎元件
負責驅動各大元件,通過呼叫各自對外提供的API介面,實現它們之間的互動和協作
提供整個框架的啟動入口
(3)兩個中介軟體
爬蟲中介軟體
對請求物件和資料物件進行預處理
下載器中介軟體
對請求物件和響應物件進行預處理#三、程式碼實現分析
##1、明確模組之間的邏輯關係
五個核心模組和三個內建的物件是關鍵模組,需要優先實現,先拋開中介軟體,分析下它們之間的邏輯關係是:
構造spider中start_urls中的請求
傳遞給調取器進行儲存,之後從中取出
取出的request物件交給下載的進行下載,返回response
response交給爬蟲模組進行解析,提取結果
如果結果是request物件,重新交給排程器,如果結果是item物件,交給管道處理
##2、設計程式碼結構
框架名字起名為scrapy_plus
繼續對模組進行解耦和分類:
把核心模組放置在一起
請求物件模組和響應物件模組統一作為http模組
資料物件單獨作為一個分類
暫定程式碼結構為
sequenceDiagram
participant scrapy_plus
scrapy_plus->>__init__.py:
scrapy_plus->>core:
scrapy_plus->>http:
scrapy_plus->>item.py:
core->>end:__init__.py
core->>end:spider.py
core->>end:scheduler.py
core->>end:download.py
core->>end:pipeline
core->>end:engine.py
http->>end:__init__.py
http->>end:request.py
http->>end:response.py
markdown最近才開始使用,畫的不是太好請見諒
#四、框架雛形
##1、實現http模組和item模組
建立http模組包
(1)request模組的封裝
對HTTP基本的請求屬性進行簡單封裝,實現一個Request物件
# scrapy/http/request.py
'''封裝Request物件'''
class Request(object):
'''框架內建請求物件,設定請求資訊'''
def __init__(self, url, method='GET',\
headers=None, params=None, data=None):
self.url = url # 請求地址
self.method = method # 請求方法
self.headers = headers # 請求頭
self.params = params # 請求引數
self.data = data # 請求體
(2)response物件的封裝 對HTTP基本的響應屬性進行簡單封裝,實現一個Response物件
# scrapy/http/response.py
'''封裝Response物件'''
class Response(object):
'''框架內建Response物件'''
def __init__(self, url, status_code, headers, body):
self.url = url # 響應url
self.status_code = status_code # 響應狀態碼
self.headers = headers # 響應頭
self.body = body # 響應體
(3)item物件的封裝 對資料進行簡單封裝,實現Item物件
# scrapy/item.py
'''item物件'''
class Item(object):
'''框架內建Item物件'''
def __init__(self, data):
# data表示傳入的資料
self._data = data # 設定為簡單的私有屬性
@property
def data(self):
'''對外提供data進行訪問,一定程度達到保護的作用'''
return self._data
- 其中property的理解:
- property 能夠讓呼叫一個方法和呼叫一個屬性一樣容易,即不用打括號
- property 能夠讓這個屬性的值是隻讀的,即不能夠對其進行重新賦值,達到一定的保護的目的 ##2、核心模組的實現 (1)spider模組的封裝 1.1 爬蟲元件功能: 構建請求資訊(初始的),也就是生成請求物件(Request) 解析響應物件,返回資料物件(Item)或者新的請求物件(Request) 1.2 實現方案: 實現start_requests方法,返回請求物件 實現parse方法,返回Item物件或者新的請求物件 具體實現 建立core模組包
# scrapy_plus/core/spider.py
'''爬蟲元件封裝'''
from scrapy_plus.item import Item # 匯入Item物件
from scrapy_plus.http.request import Request # 匯入Request物件
class Spider(object):
'''
1. 構建請求資訊(初始的),也就是生成請求物件(Request)
2. 解析響應物件,返回資料物件(Item)或者新的請求物件(Request)
'''
start_url = 'http://www.baidu.com' # 預設初始請求地址
def start_requests(self):
'''構建初始請求物件並返回'''
return Request(self.start_url)
def parse(self, response):
'''解析請求
並返回新的請求物件、或者資料物件
'''
return Item(response.body) # 返回item物件
(2) 排程器模組的封裝 2.1 排程器功能: 快取請求物件(Request),併為下載器提供請求物件,實現請求的排程: 對請求物件進行去重判斷:實現去重方法_filter_request,該方法對內提供,因此設定為私有方法 2.2 實現方案: 利用佇列FIFO儲存請求; 實現add_request方法新增請求,接收請求物件作為引數; 實現get_request方法對外提供從佇列取出的請求物件
# scrapy_plus/core/scheduler.py
'''排程器模組封住'''
# 利用six模組實現py2和py3相容
from six.moves.queue import Queue
class Scheduler(object):
'''
1. 快取請求物件(Request),併為下載器提供請求物件,實現請求的排程
2. 對請求物件進行去重判斷
'''
def __init__(self):
self.queue = Queue()
def add_request(self, request):
'''新增請求物件'''
self.queue.put(request)
def get_request(self):
'''獲取一個請求物件並返回'''
request = self.queue.get()
return request
def _filter_request(self):
'''請求去重'''
# 暫時不實現
pass
這裡queue的匯入在pycharm中會報錯,不用管它,這是pycharm的問題,程式碼的OK的
(3)下載器模組的封裝 3.1 下載器功能: 根據請求物件(Request),發起HTTP、HTTPS網路請求,拿到HTTP、HTTPS響應,構建響應物件(Response)並返回 3.1 實現方案: 利用requests、urllib2等模組發請求,這裡使用requests模組 實現get_response方法,接收request請求物件作為引數,發起請求,獲取響應
# scrapy_plus/core/downloader.py
'''下載器元件'''
import requests
from scrapy_plus.http.response import Response
class Downloader(object):
'''根據請求物件(Request),發起HTTP、HTTPS網路請求,拿到HTTP、HTTPS響應,構建響應物件(Response)並返回'''
def get_response(self, request):
'''發起請求獲取響應的方法'''
# 1. 根據請求物件,發起請求,獲取響應
# 判斷請求方法:
if request.method.upper() == 'GET':
resp = requests.get(request.url, headers=request.headers,\
params=request.params)
elif request.method.upper() == 'POST':
resp = requests.post(request.url,headers=request.headers,\
params=request.params,data=request.data)
else:
# 如果方法不是get或者post,丟擲一個異常
raise Exception("不支援的請求方法")
# 2. 構建響應物件,並返回
return Response(resp.url, resp.status_code, resp.headers, resp.content)
(4)管道模組的封裝 4.1 管道元件功能: 負責處理資料物件 4.2 實現方案: 實現process_item方法,接收資料物件作為引數
# scrapy_plus/core/pipeline.py
'''管道元件封裝'''
class Pipeline(object):
'''負責處理資料物件(Item)'''
def process_item(self, item):
'''處理item物件'''
print("item: ", item)
(5)引擎模組的封裝 5.1 引擎元件功能: 對外提供整個的程式的入口 依次呼叫其他元件對外提供的介面,實現整個框架的運作(驅動) 5.2 實現方案: 利用init方法初始化其他元件物件,在內部使用 實現start方法,由外部呼叫,啟動引擎 實現_start_engine方法,完成整個框架的執行邏輯 具體參考上一小節中雛形結構引擎的邏輯
# scrapy_plus/core/engine.py
'''引擎元件'''
from scrapy_plus.http.request import Request # 匯入Request物件
from .scheduler import Scheduler
from .downloader import Downloader
from .pipeline import Pipeline
from .spider import Spider
class Engine(object):
'''
a. 對外提供整個的程式的入口
b. 依次呼叫其他元件對外提供的介面,實現整個框架的運作(驅動)
'''
def __init__(self):
self.spider = Spider() # 接收爬蟲物件
self.scheduler = Scheduler() # 初始化排程器物件
self.downloader = Downloader() # 初始化下載器物件
self.pipeline = Pipeline() # 初始化管道物件
def start(self):
'''啟動整個引擎'''
self._start_engine()
def _start_engine(self):
'''依次呼叫其他元件對外提供的介面,實現整個框架的運作(驅動)'''
# 1. 爬蟲模組發出初始請求
start_request = self.spider.start_requests()
# 2. 把初始請求新增給排程器
self.scheduler.add_request(start_request)
# 3. 從排程器獲取請求物件,交給下載器發起請求,獲取一個響應物件
request = self.scheduler.get_request()
# 4. 利用下載器發起請求
response = self.downloader.get_response(request)
# 5. 利用爬蟲的解析響應的方法,處理響應,得到結果
result = self.spider.parse(response)
# 6. 判斷結果物件
# 6.1 如果是請求物件,那麼就再交給排程器
if isinstance(result, Request):
self.scheduler.add_request(result)
# 6.2 否則,就交給管道處理
else:
self.pipeline.process_item(result)
#五、框架安裝
##1 安裝框架的目的
利用setup.py將框架安裝到python環境中,在編寫爬蟲時候,作為第三方模組來呼叫
##2 框架安裝第一步:完成setup.py的編寫
以下程式碼相當於一個模板,只用更改name欄位出,改為對應的需要安裝的模組名稱就可以,比如這裡是:scrapy_plus
將setup.py檔案放到scrapy_plus的同級目錄下
from os.path import dirname, join
# from pip.req import parse_requirements
from setuptools import (
find_packages,
setup,
)
def parse_requirements(filename):
""" load requirements from a pip requirements file """
lineiter = (line.strip() for line in open(filename))
return [line for line in lineiter if line and not line.startswith("#")]
with open(join(dirname(__file__), './VERSION.txt'), 'rb') as f:
version = f.read().decode('ascii').strip()
setup(
name='scrapy-plus', # 模組名稱
version=version,
description='A mini spider framework, like Scrapy', # 描述
packages=find_packages(exclude=[]),
author='itcast',
author_email='[email protected]',
license='Apache License v2',
package_data={'': ['*.*']},
url='#',
install_requires=parse_requirements("requirements.txt"), # 所需的執行環境
zip_safe=False,
classifiers=[
'Programming Language :: Python',
'Operating System :: Microsoft :: Windows',
'Operating System :: Unix',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
'Programming Language :: Python :: 3.6',
],
)
注意: 上面程式碼中可能會報錯需要額外安裝packaging模組,更新setuptools
pip install packaging
pip install --upgrade setuptools
pip.req可能不存在,對應的可以:
def parse_requirements(filename):
""" load requirements from a pip requirements file """
lineiter = (line.strip() for line in open(filename))
return [line for line in lineiter if line and not line.startswith("#")]
##3、 框架安裝第二步:完成requirements.txt的編寫 功能: 寫明依賴環境所支援的模組及其版本 使用: 在setup.py中使用 放置在setup.py同級目錄下
requests>=2.18.4
six>=1.11.0
##4 框架安裝第三步:完成VERSION.txt的編寫 功能: 標明當前版本,一個合格的模組,應當具備相應的版本號 使用: 在setup.py中使用 放置在setup.py同級目錄下
1.0
##5 框架安裝第四步:執行安裝命令 步驟: 切換到setup.py所在目錄 切換到對應需要python虛擬環境下 在終端執行python setup.py install 顯示結果:
Adding chardet 3.0.4 to easy-install.pth file
Installing chardetect-script.py script to C:\Users\Star Platinum\AppData\Local\Programs\Python\Python35\Scripts
Installing chardetect.exe script to C:\Users\Star Platinum\AppData\Local\Programs\Python\Python35\Scripts
Using c:\users\star platinum\appdata\local\programs\python\python35\lib\site-packages
Finished processing dependencies for scrapy-plus==1.0
#六、框架執行
##1 編寫main.py
在其他路徑下建立一個專案資料夾 project_dir
# project_dir/main.py
from scrapy_plus.core.engine import Engine # 匯入引擎
if __name__ == '__main__':
engine = Engine() # 建立引擎物件
engine.start() # 啟動引擎
執行結果:管道中列印的item物件 報錯:
File "C:\Users\Star Platinum\AppData\Local\Programs\Python\Python35\lib\site-packages\urllib3\packages\six.py", line 82, in _import_module
__import__(name)
ImportError: No module named 'http.client'
這裡的問題是window下匯入包的時候路徑優先找本專案下的http包,所以沒有找到client,解決方法是: 修改http資料夾的名字,改為htttp(自定義),同時路徑也跟著修改
再不行就看看這些庫是否下載,版本不對也無所謂,不要低就好 requests2.11.1 gcloud0.17.0 oauth2client3.0.0 requests-toolbelt0.7.0 python-jwt2.0.1 pycrypto2.6.1 執行成功之後顯示結果:
item物件:<scrapy_plus.item.Item object at 0x10759eef0>