
Spark函式詳解系列之RDD基本轉換+例項
RDD:彈性分散式資料集,是一種特殊集合 ‚ 支援多種來源 ‚ 有容錯機制 ‚ 可以被快取 ‚ 支援並行操作,一個RDD代表一個分割槽裡的資料集
RDD有兩種操作運算元:
Transformation(轉換):Transformation屬於延遲計算,當一個RDD轉換成另一個RDD時並沒有立即進行轉換,僅僅是記住了資料集的邏輯操作
Ation(執行):觸發Spark作業的執行,真正觸發轉換運算元的計算
本系列主要講解Spark中常用的函式操作:
1.RDD基本轉換
本節所講函式
4.mapPartitionsWithIndex(func)
5.simple(withReplacement,fraction,seed)
10.coalesce(numPartitions,shuffle)
13.randomSplit(weight:Array[Double],seed)
基礎轉換操作:
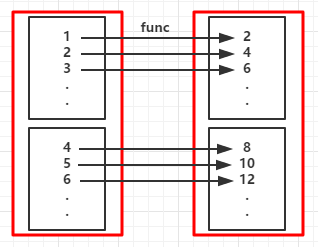
1.map(func):資料集中的每個元素經過使用者自定義的函式轉換形成一個新的RDD,新的RDD叫MappedRDD
(例1)
| 1 2 3 4 5 6 7 8 9 10 |
|
輸出:
2 4 6 8 10 12 14 16 18 20
(RDD依賴圖:紅色塊表示一個RDD區,黑色塊表示該分割槽集合,下同)
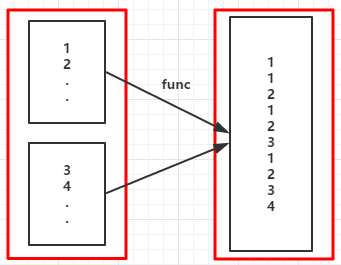
2.flatMap(func):與map類似,但每個元素輸入項都可以被對映到0個或多個的輸出項,最終將結果”扁平化“後輸出
(例2)
| 1 2 3 4 |
|
輸出:
1 1 2 1 2 3 1 2 3 4 1 2 3 4 5
如果是map函式其輸出如下:
Range(1) Range(1, 2) Range(1, 2, 3) Range(1, 2, 3, 4) Range(1, 2, 3, 4, 5)
(RDD依賴圖)
3.mapPartitions(func):類似與map,map作用於每個分割槽的每個元素,但mapPartitions作用於每個分割槽工
func的型別:Iterator[T] => Iterator[U]
假設有N個元素,有M個分割槽,那麼map的函式的將被呼叫N次,而mapPartitions被呼叫M次,當在對映的過程中不斷的建立物件時就可以使用mapPartitions比map的效率要高很多,比如當向資料庫寫入資料時,如果使用map就需要為每個元素建立connection物件,但使用mapPartitions的話就需要為每個分割槽建立connetcion物件
(例3):輸出有女性的名字:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
輸出:
kpop lucy
其實這個效果可以用一條語句完成
| 1 |
|
之所以不那麼做是為了演示函式的定義
(RDD依賴圖)
4.mapPartitionsWithIndex(func):與mapPartitions類似,不同的時函式多了個分割槽索引的引數
func型別:(Int, Iterator[T]) => Iterator[U]
(例4):將例3橙色的註釋部分去掉即是
輸出:(帶了分割槽索引)
[0]kpop [1]lucy
5.sample(withReplacement,fraction,seed):以指定的隨機種子隨機抽樣出數量為fraction的資料,withReplacement表示是抽出的資料是否放回,true為有放回的抽樣,false為無放回的抽樣
(例5):從RDD中隨機且有放回的抽出50%的資料,隨機種子值為3(即可能以1 2 3的其中一個起始值)
| 1 2 3 4 5 |
|
6.union(ortherDataset):將兩個RDD中的資料集進行合併,最終返回兩個RDD的並集,若RDD中存在相同的元素也不會去重
| 1 2 3 4 5 6 |
|
輸出:
1 2 3 3 4 5
7.intersection(otherDataset):返回兩個RDD的交集
| 1 2 3 4 5 6 |
|
輸出:
3 4
8.distinct([numTasks]):對RDD中的元素進行去重
| 1 2 3 4 5 |
|
輸出:
1 6 9 5 2
9.cartesian(otherDataset):對兩個RDD中的所有元素進行笛卡爾積操作
| 1 2 3 4 5 |
|
輸出:

(1,2) (1,3) (1,4) (1,5) (2,2) (2,3) (2,4) (2,5) (3,2) (3,3) (3,4) (3,5)
(RDD依賴圖)

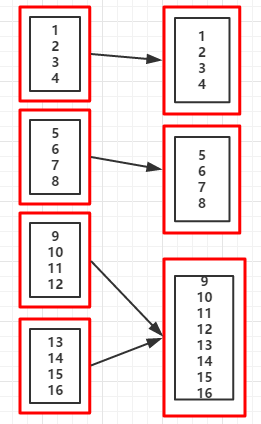
10.coalesce(numPartitions,shuffle):對RDD的分割槽進行重新分割槽,shuffle預設值為false,當shuffle=false時,不能增加分割槽數
目,但不會報錯,只是分割槽個數還是原來的
(例9:)shuffle=false
| 1 2 3 4 |
|
輸出:
重新分割槽後的分割槽個數:3 //分割槽後的資料集 List(1, 2, 3, 4) List(5, 6, 7, 8) List(9, 10, 11, 12, 13, 14, 15, 16)
(例9.1:)shuffle=true
| 1 2 3 4 5 |
|
輸出:
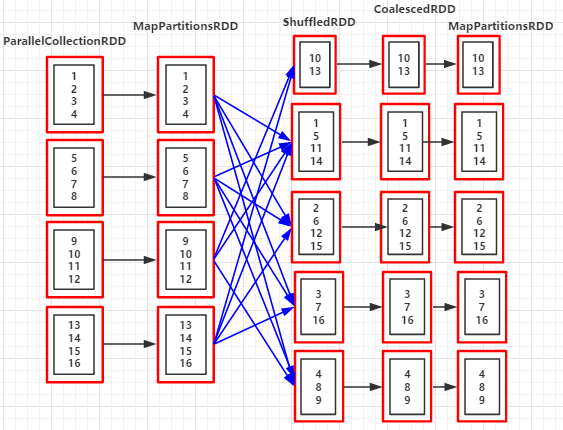
重新分割槽後的分割槽個數:5 RDD依賴關係:(5) MapPartitionsRDD[4] at coalesce at Coalesce.scala:14 [] | CoalescedRDD[3] at coalesce at Coalesce.scala:14 [] | ShuffledRDD[2] at coalesce at Coalesce.scala:14 [] +-(4) MapPartitionsRDD[1] at coalesce at Coalesce.scala:14 [] | ParallelCollectionRDD[0] at parallelize at Coalesce.scala:13 [] //分割槽後的資料集 List(10, 13) List(1, 5, 11, 14) List(2, 6, 12, 15) List(3, 7, 16) List(4, 8, 9)
(RDD依賴圖:coalesce(3,flase))
(RDD依賴圖:coalesce(3,true))
11.repartition(numPartition):是函式coalesce(numPartition,true)的實現,效果和例9.1的coalesce(numPartition,true)的一樣
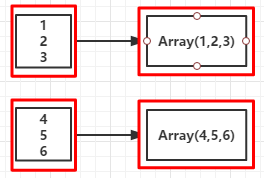
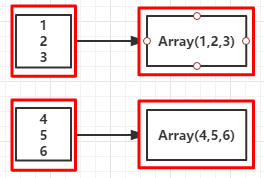
12.glom():將RDD的每個分割槽中的型別為T的元素轉換換陣列Array[T]
| 1 2 3 4 5 |
|
輸出:
int[] //說明RDD中的元素被轉換成陣列Array[Int]
13.randomSplit(weight:Array[Double],seed):根據weight權重值將一個RDD劃分成多個RDD,權重越高劃分得到的元素較多的機率就越大
| 1 2 3 4 5 6 7 |
|
輸出:
2 4 3 8 9 1 5 6 7 10