
Hadoop快速入門 -- (Hadoop叢集的配置及啟動 含編譯軟體)
hadoop: hdfs叢集:負責檔案讀寫 yarn叢集:負責為mapreduce程式分配運算硬體資源
name node 本身的地位是很重要的,它記錄了使用者上傳的檔案分別在哪些dat node 上,記錄了這些檔案的元資訊.所以它叫名稱節點,記錄了檔案的名稱和實際對應的實體地址.它如果掛掉了,那麼客戶端是無法知道這些檔案在哪臺機器上的,所以name node 是很重要的,所以這個是單獨一臺機器的. 在做MAPREDUCE運算的時候,是靠yarn來執行的,yarn的老大也很重要,老大 resource manager 掛了話,那麼就沒人去管資源排程了.所以resource manager 也單獨放一臺機器. 其他的data node 跟 node manager 是應該放在一起的,如果data node 跟node manager是分開的,那麼客戶端傳送一個mapreduce程式執行,是在node manager上執行,那麼需要去讀取hdfs檔案系統上的資料,那麼就得走網路檔案傳輸了.這個時候會很慢.
但是在學習的時候,我們為了節省一點機器,就將 name node 跟 resource manager 放在同一臺機器上.它們兩個工作的埠是不同的,所以是不影響的.
1.首先需要新建一個使用者 hadoop, 用來統一操作hadoop
useradd hadoop
passwd hadoop
echo $JAVA_HOME
檢視jdk的安裝路徑:
sudo scp -r /usr/local/jdk1.7.0_745 bd4:/usr/local
使用scp需要輸入密碼 如果沒有配置 sudo 則可以先使用 su 切換到root使用者,使用scp複製jdk. 然後在bd4-hadoop 配置 /etc/profile: 在後面追加
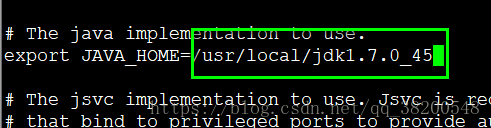
export JAVA_HOME=/usr/local/jdk1.7.0_45
export PATH=$PATH:$JAVA_HOME/bin
然後使用 source /etc/profile 使之生效
需要注意的是此時使用spurce 需要在hadoop使用者下,如果只是在root使用者下進行source,那麼hadoop使用者下是不會生效的
3.為了便於使用root使用者的許可權,我們可以配置sudo 3.1現在一臺機器上進行配置,然後scp到其他的機器上: 配置之前要先切換到 root使用者下,使用 su 進行切換
vi /etc/sudoers
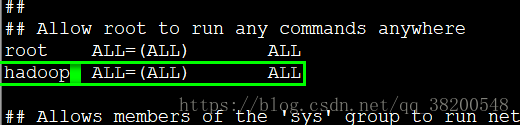
root ALL=(ALL) ALL 這一行,將名字改成hadoop
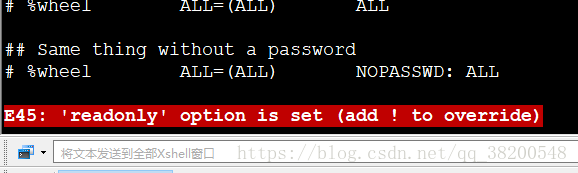
:wq!
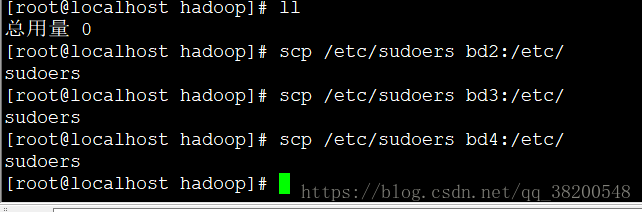
3.2 將配置好的檔案複製到另外的三臺機器上.
scp /etc/sudoers bd2:/etc/
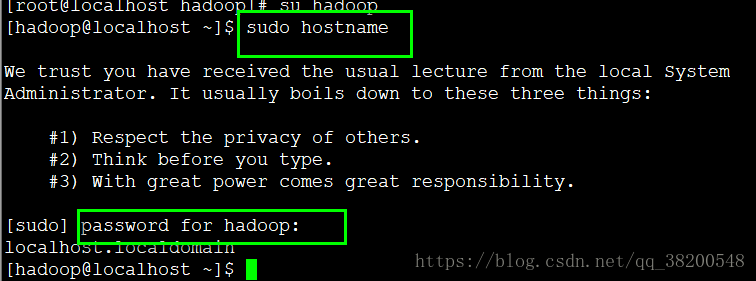
3.3測試 sudo 是否配置成功:
sudo hostname
4.每臺機器都切換到root使用者,然後關閉防火牆
service iptables stop
配置下次啟動時自動關閉防火牆:
chkconfig iptables off
5.hadoop的安裝包,需要編譯好的安裝包:
5.1 將軟體包上傳到一臺伺服器上 - bd1 可以使用 rz 命令 進行檔案上傳 在 /root目錄下新建一個資料夾 apps 之後所有的軟體都放在這個資料夾裡面. 解壓壓縮包到 apps/ 裡面
tar -zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C apps/
hadoop的目錄結構:
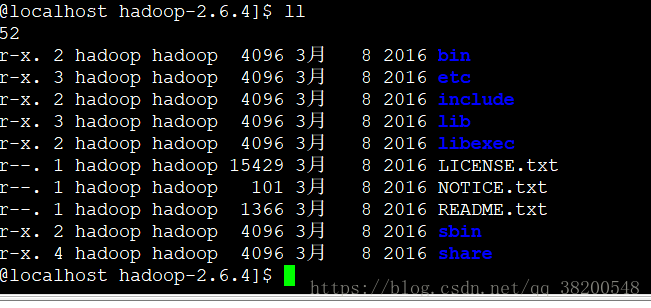
bin : 自己的操作命令 sbin : 系統啟動管理的命令 etc : 配置檔案 include : C 語言本地庫的頭 lib : 本地庫 裡面有一個 native 資料夾 .so share : doc (文件) 和 hadoop (jar包)
6.配置Hadoop
進入:/home/hadoop/apps/hadoop-2.6.4/etc/hadoop
裡面有非常多的配置檔案
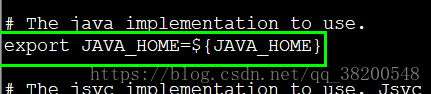
6.1 配置 hadoop-env.sh – 執行時的環境變數
只需要給它一個 java 就可以了
先獲取JAVA_HOME:
echo $JAVA_HOME — — /usr/local/jdk1.7.0_45
然後修改 hadoop-env.sh 找到JAVE_HOME處的配置
剩下的都是Hadoop執行時引數配置: 這些引數其實是配在哪個檔案裡面都可以的,之所以要分開,是為了對用不同的功能,便於管理檢視
6.2 core-site.xml – 核心的配置 (公共的配置)
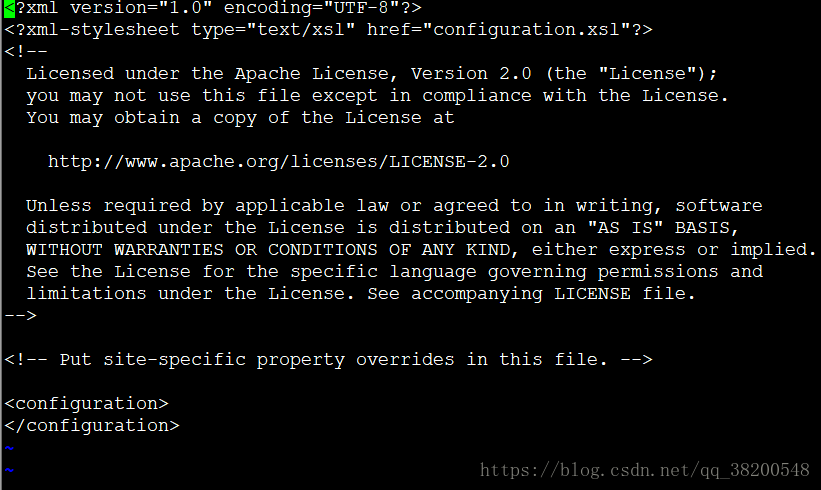
注意修改的時候,別改錯了,裡面是xml檔案
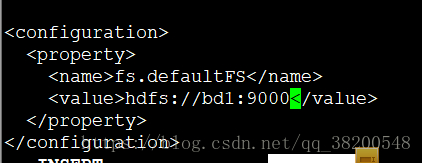
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bd1:9000</value>
</property>
</configuration>
上面配置的其實就是name node, name node 才是為客戶提供服務的,客戶端去訪問hdfs的時候,hdfs是有好多好多臺機器的,所以要統統找name node , name node 是記錄了哪些檔案存在哪些機器上的. 所以客戶端訪問的時候首先訪問的是name node
hadoop.tmp.dir:
hadoop是一個叢集版的軟體,沒一臺機器上都有它的工作程序,既然有工作程序那麼肯定有本地的工作目錄,hadoop.tmp.dir就是這個工作目錄
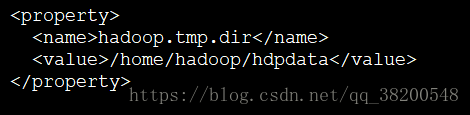
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
6.3 hdfs-site.xml
這個配置檔案可以配很多,也可以不用配,因為它都有預設值
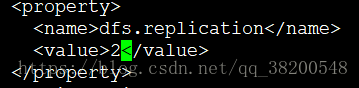
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
客戶端把檔案交給hdfs之後,hdfs如果只給我保留一份,萬一它保留的那份資料的機器宕機了,那麼資料就拿不到了,配置副本為2,宕機一臺還有另一臺,預設是3
6.4 mapred-site.xml.template
mapreduce執行的平臺的名稱: yarn
mapreduce程式提交完之後就交給yarn去跑了
預設是local,如果是local的話,那麼mapreduce程式就會在本機單機上模擬跑一下,就不會到叢集上分散式運行了,就變成了一個單機版的小程式,
也能執行
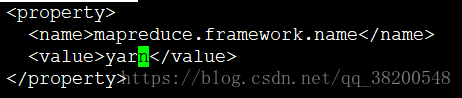
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改之後還需要將檔名mapred-site.xml.template變成mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
6.5 yarn-site.xml
找一個老大yarn去分配資源
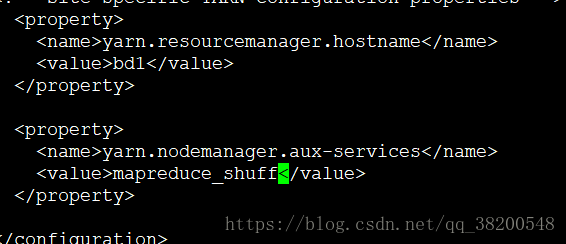
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bd1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuff</value>
</property>
遇到叢集搭建出現問題的時候,一般都是配置檔案配置的時候出現問題. 在配置的時候需要注意點
完成上面的配置之後,hadoop的配置就完成了.接下來就是要將bd1上配置好的hadoop分發到其他的三臺機器上
scp -r apps bd2:/home/hadoop
scp -r apps bd3:/home/hadoop
scp -r apps bd4:/home/hadoop
複製完之後,還先不能啟動hadoop,需要先對hadoop做格式化. hdfs不是一個底層的檔案系統,而是架構再Linux檔案系統之上的檔案系統,它存檔案就是把檔案分散地放在Linux檔案系統裡面的.hdfs檔案系統是一個高層的抽象的檔案系統,藉助於作業系統的本地的檔案系統的檔案系統,它的格式化無非就是生成相應的檔案目錄.把資料目錄生成
1.先配置hadoop的環境變數,不然每一次在敲命令的時候都要進入bin目錄
進入hadoop-2.6.4安裝目錄:
pwd:
/home/hadoop/apps/hadoop-2.6.4

export JAVA_HOME=/usr/local/jdk1.7.0_45
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
bd1配置了hadoop的環境變數之後,將配置檔案scp到其他的機器上:
sudo scp /etc/profile bd2:/etc/
sudo scp /etc/profile bd3:/etc/
sudo scp /etc/profile bd4:/etc/

source /etc/profile
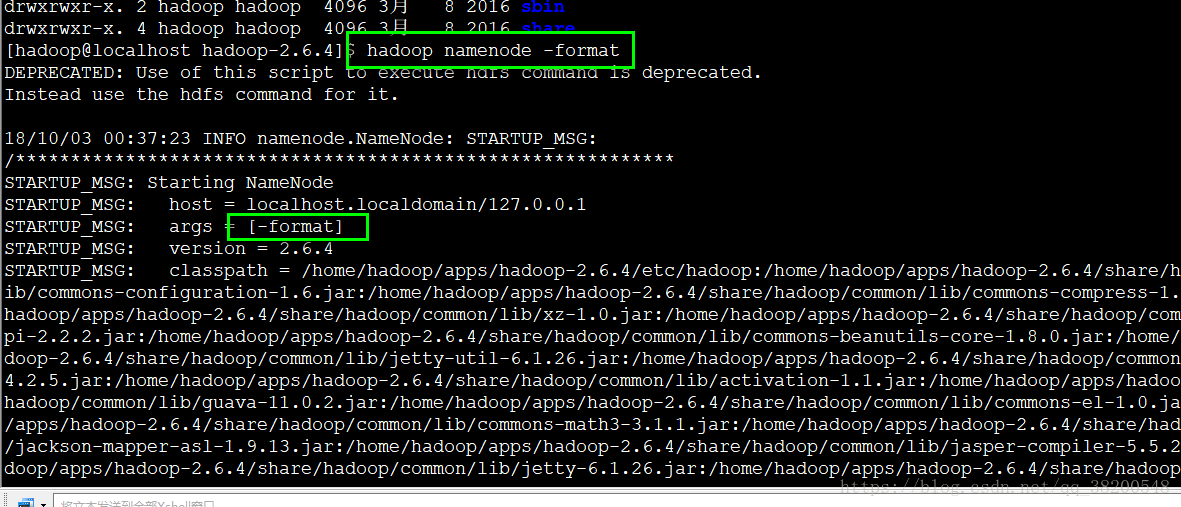
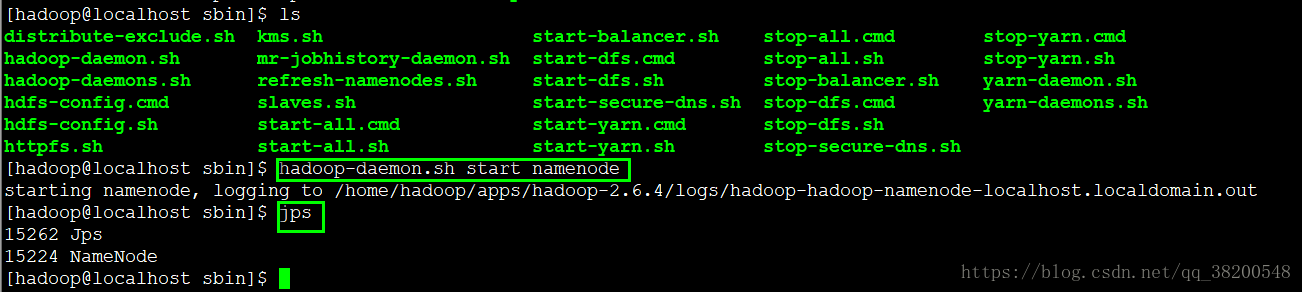
配置好了hadoop的環境變數之後就需要做格式化了: 需要格式化 name node (name node 是記錄整個檔案的位置,需要生成一些初識目錄)
hadoop namenode -format
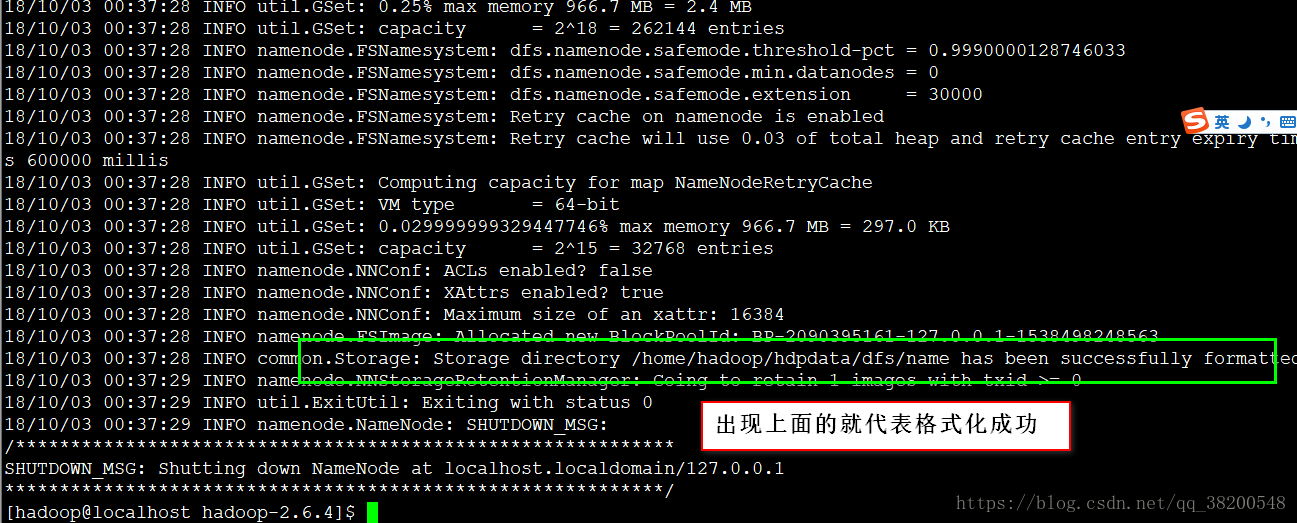
檢視hdpdata目錄裡面生成的內容:
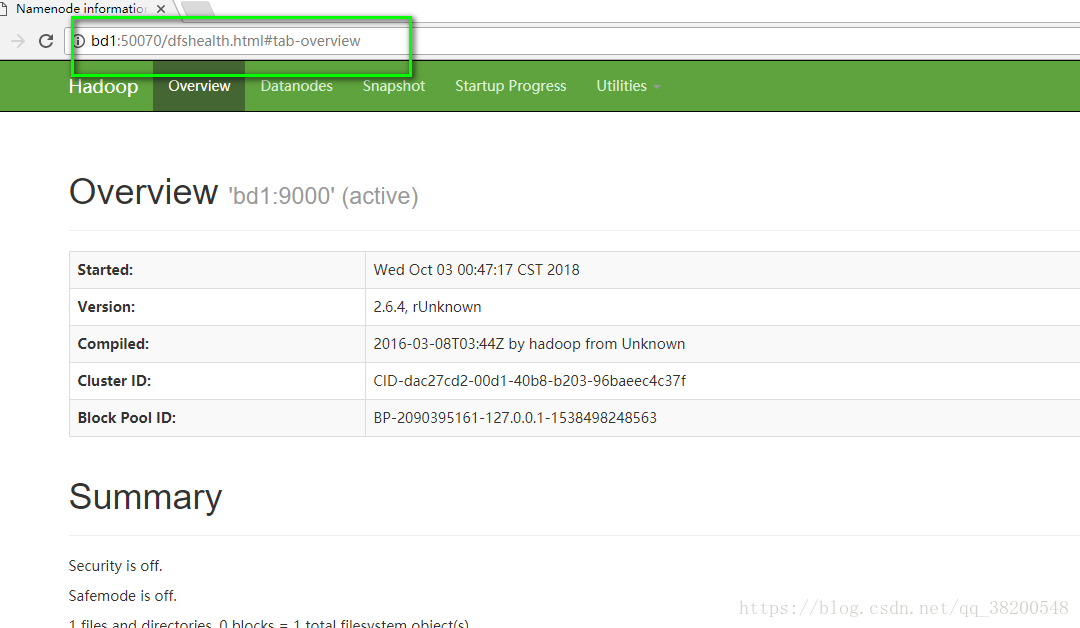
http://bd1:50070/
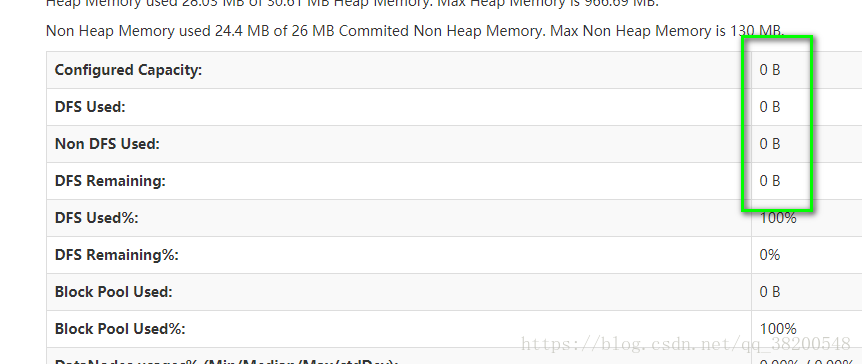
你會發現檔案系統的空間為0 原因是沒有配置 data note , 只有data note才是存放資料的
在 bd3 上啟動datanode
hadoop-daemon.sh start datanode
把start 換成 stop 就可以關閉了
每一臺機器上的hadoop的配置檔案都是一樣的,所以每一臺機器都能看到name node 的地址,所以其他的機器就可以跟name node 握手成功.
問題:
我啟動了一臺name node , bd3 跟 bd4 都能正常啟動data node ,但是bd2 卻一直啟動不了data node.
所以我們需要檢視日誌,看報錯在哪?
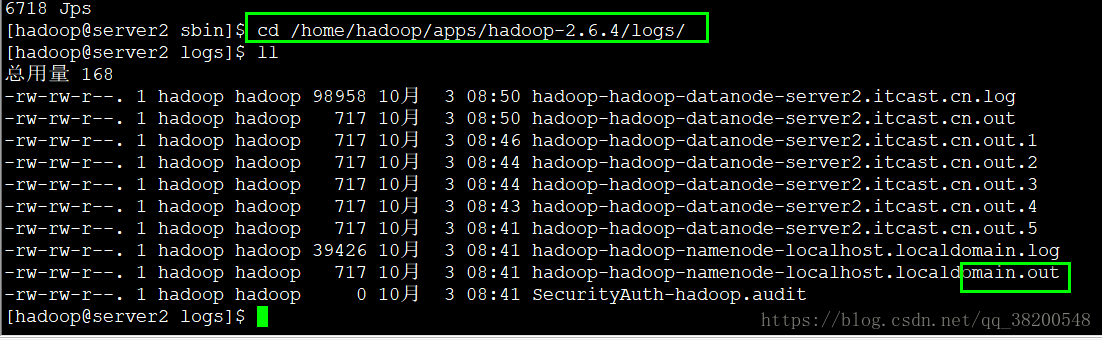
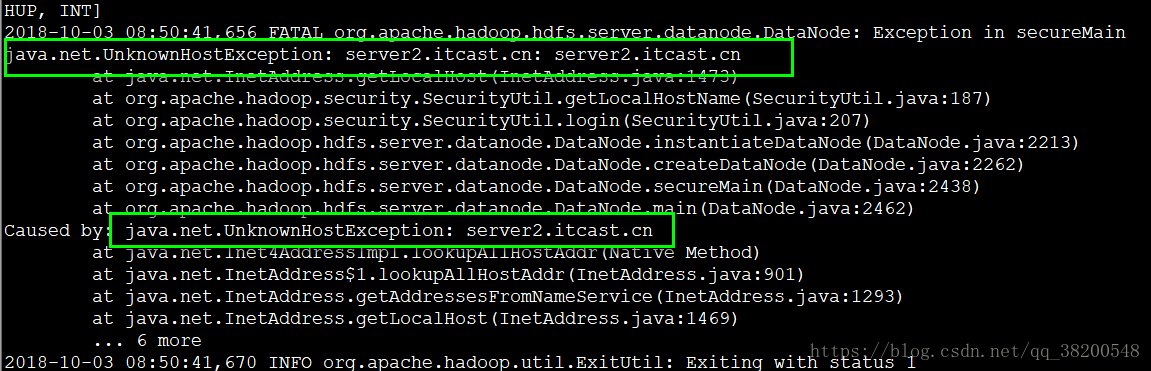
媽的,我之前/etc/sysconfig/network 這個檔案跟其他的不一致 所以得修改成主機名字,修改之後,得 reboot 重新啟動,否則是不會生效的
------即使是一臺機器的data node 啟動失敗了,也不會影響整個機器的啟動
通過指令碼自動化啟動 hadoop 叢集
hadoop自身帶了啟動叢集的指令碼:

但是有這個指令碼之外,還得有一個檔案告訴它,我需要啟動的機器在哪裡 在hadoop的配置檔案 etc 裡面就有這個檔案:
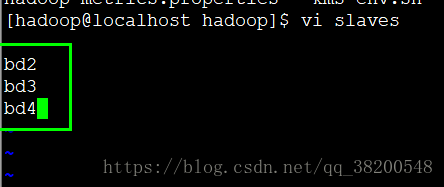
ssh bd2 hadoop-daemon.sh start datanode
ssh bd3 hadoop-daemon.sh start datanode
ssh bd4 hadoop-daemon.sh start datanode
ssh 需要輸入密碼:
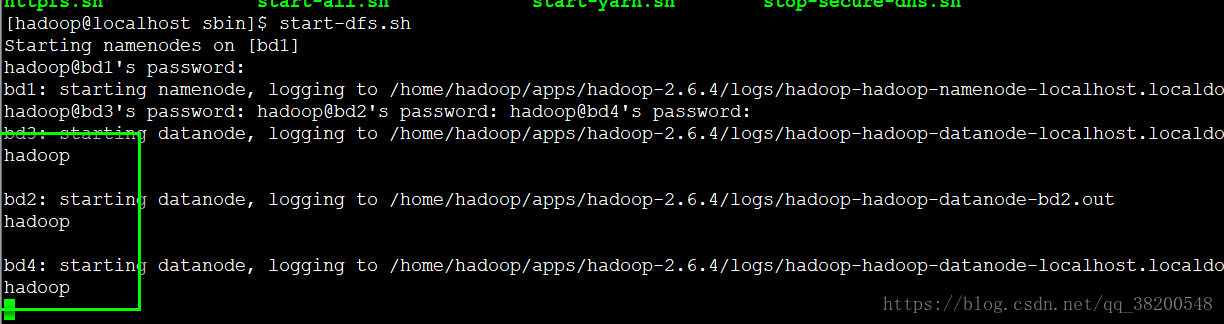
根據它的提示輸入密碼會出現錯位的情況,根本就不知道哪個地方等待的時候是需要輸入密碼的
所以現在需要配置免密登入: bd1 到 bd2 , bd3, bd4 的免密登入 因為是在bd1上啟動這個指令碼的:
ssh-keygen
ssh-copy-id bd1
ssh-copy-id bd2
ssh-copy-id bd3
ssh-copy-id bd4
測試免密登入是否成功:
ssh bd2
ssh bd3
ssh bd4
這樣就可以直接使用自動化的指令碼了,啟動跟關閉的時候都不需要輸入密碼