zookeeper-非常重要的zab協議-《每日五分鐘搞定大資料》
 上篇文章paxos與一致性說到zab是在paxos的基礎上做了重要的改造,解決了一系列的問題,這一篇我們就來說下這個zab。
上篇文章paxos與一致性說到zab是在paxos的基礎上做了重要的改造,解決了一系列的問題,這一篇我們就來說下這個zab。
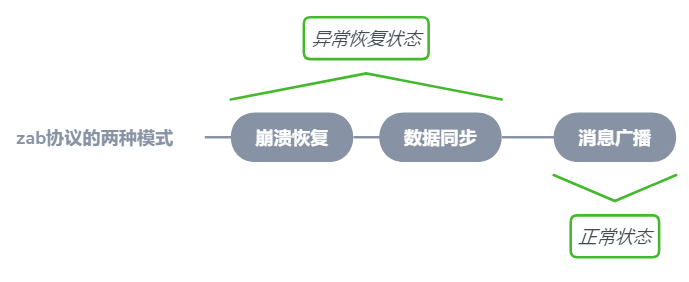
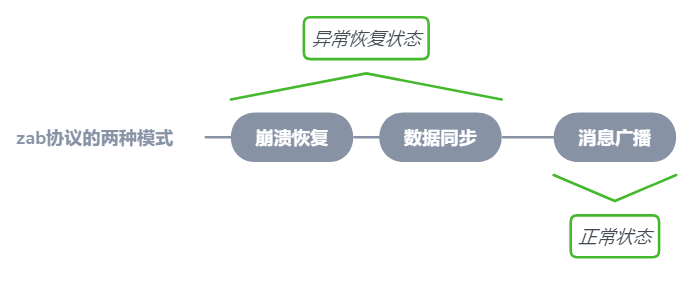
zab協議的全稱是ZooKeeper Atomic Broadcast即zookeeper“原子”“廣播”協議。它規定了兩種模式:崩潰恢復和訊息廣播
恢復模式
什麼時候進入?
- 當整個服務框架在啟動過程中
- 當Leader伺服器出現網路中斷崩潰退出與重啟等異常情況
- 當有新的伺服器加入到叢集中且叢集處於正常狀態(廣播模式),新服會與leader進行資料同步,然後進入訊息廣播模式
這三種情況ZAB都會進入恢復模式
幹了什麼?
選舉產生新的Leader伺服器,同時叢集中已有的過半的機器會與該Leader完成狀態同步,這些工作完成後,ZAB協議就會退出崩潰恢復模式
廣播模式
什麼時候進入?
叢集狀態穩定,有了leader且過半機器狀態同步完成,退出崩潰恢復模式後進入訊息廣播模式
幹了什麼?
正常的訊息同步,把日常產生資料從leader同步到learner的過程

總結一下zab協議規定的兩種模式在實際操作中經歷了三個步驟,如上圖,下面我再詳細地說下這兩個過程都幹了些什麼
1.崩潰恢復狀態 - 即選主過程
進入崩潰恢復模式說明叢集目前是存在問題的了,那麼此時就需要開始一個選主的過程。
zookeeper使用的預設選主演算法是FastLeaderElection,它是標準的Fast Paxos演算法實現,可解決LeaderElection選舉演算法收斂速度慢的問題(上篇文章也有提到過)。
zab協議規定的狀態
LOOKING 當前叢集沒有leader,準備選舉 FOLLOWING 已經存在leader,當前伺服器為跟隨者 LEADING 唯一的領導,維護與Follower間的心跳 OBSERVING 觀察者狀態。表明當前伺服器角色是Observer
投票流程
投票的依據
投票的依據就是下面的兩個id,投票即是給所有伺服器傳送(myid,zxid)資訊
myid:使用者在配置檔案中自己配置,每個節點都要配置的一個唯一值,從1開始往後累加。
zxid:zxid有64位,分成兩部分:
高32位是Leader的epoch:選舉時鐘,每次選出新的Leader,epoch累加1
低32位是在這輪epoch內的事務id
:對於使用者的每一次更新操作叢集都會累加1。
注意:zk把epoch和事務id合在一起,每次epoch變化,都將低32位的序號重置,這樣做是為了方便對比出最新的資料,保證了zxid的全域性遞增性。(其實這樣也會存在問題,雖然概率小,這裡就先不說了後面的文章會詳細講)。
關於傳送選票
第一輪投給自己,之後每個服把上述所有資訊傳送給其他所有服,票箱中只會記錄每一投票者的最後一票
關於接收投票
伺服器會嘗試從其它伺服器獲取投票,並記入自己的投票箱內。如果無法獲取任何外部投票,則會確認自己是否與叢集中其它伺服器保持著有效連線。如果是,則再次傳送自己的投票;如果否,則馬上與之建立連線。
關於選舉輪次
由於所有有效的投票都必須在同一輪次中。每開始新一輪投票自身的logicClock自增1。
- 接收到的logicClock大於自己的。說明自己落後了,更新logicClock後正常。
- 接收到的logicClock小於自己的。忽略該票。
- 接收到的logickClock與自己的相等,正常判斷。
關於選票判斷
對比自身的和接收到的(myid,zxid)
- 首先對比zxid高32位的選舉時鐘epoch
- 一致則對比zxid低32的事務id
- 仍然一致則對比使用者自己配置的myid 選完後廣播選出的(myid,zxid)
關於選舉結束 過半伺服器選了同一個,則投票結束,根據投票結果更新自身狀態為leader或者follower
還有兩個問題
上面說過zookeeper是一個原子廣播協議,在這個崩潰恢復的過程就體現了它的原子性,zookeeper在選主過程保證了兩個問題:
- commit過的資料不丟失
- 未commit過的資料丟棄
(myid,zxid)的選票設計剛好解決了這兩個問題。
- commit過的資料半數以上參加選舉的follwer都有,而且成為leader的條件是要有最高事務id即資料是最新的。
- 未commit過的資料只存在於leader,但是leader宕機無法參加首輪選舉,epoch會小一輪,最終資料會丟棄。
2.訊息廣播狀態 - 即資料同步
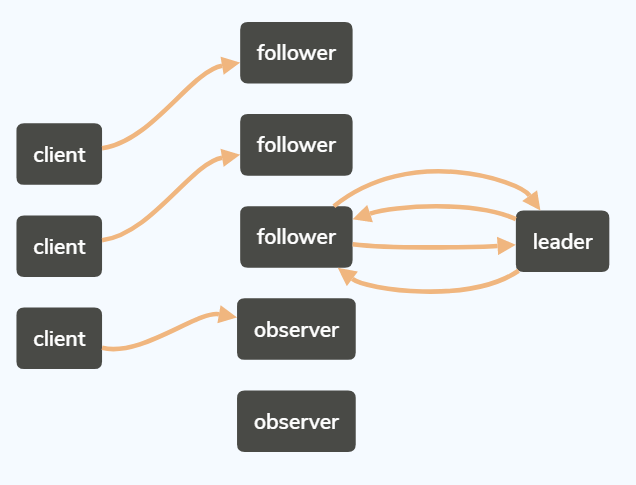
如上圖,client端發起請求,讀請求由follower和observer直接返回,寫請求由它們轉發給leader。
Leader 首先為這個事務分配一個全域性單調遞增的唯一事務ID (即 ZXID )。
然後發起proposal給follower,Leader 會為每一個 Follower 都各自分配一個單獨的佇列,然後將需要廣播的事務 Proposal 依次放入這些佇列中去,並且根據 FIFO策略進行訊息傳送。
每一個 Follower 在接收到這個事務 Proposal 之後,都會首先將其以事務日誌的形式寫入到本地磁碟中去,並且在成功寫入後反饋給 Leader 伺服器一個 Ack 響應。
當 Leader 伺服器接收到超過半數 Follower 的 Ack 響應後,就會廣播一個Commit 訊息給所有的 Follower 伺服器以通知其進行事務提交,同時 Leader 自身也會完成對事務的提交。
後記
最近這幾篇理論性的東西太多,下一篇寫點簡單的程式碼,zookeeper分散式鎖的實現。感謝閱讀。