
Apache Kafka入門教程輕鬆學-第四章 Kafka核心元件和流程-設計-原理(一)控制器
本入門教程,涵蓋Kafka核心內容,通過例項和大量圖表,幫助學習者理解,任何問題歡迎留言。
目錄:
通過前幾章的學習,我們已經從巨集觀層面瞭解了kafka的設計理念。包括kafka叢集的組成、訊息的主題、主題的分割槽、分割槽的副本等內容。接下來我們會繼續深入,瞭解kafka的主要元件以及核心的流程,最後還會介紹kafka的訊息是如何儲存的。此章非常重要,通過本章和上一章的學習,你已經能夠掌握kafka 80%的核心內容。當然隨著學習的深入,難度也會越來越大,有任何問題歡迎留言或者私信。
Kafka主要的元件如下:
控制器
協調器
日誌管理器
副本管理器
我們將會逐個進行講解,講解過長還將保持前面章節的特點,多用有形的圖表幫助讀者理解。
本篇部落格先講解控制器部分。其它元件再逐步發出
1、控制器
在前一章的學習中,我們已經知道Kafka的叢集由n個的broker所組成,每個broker就是一個kafka的例項或者稱之為kafka的服務。其實控制器也是一個broker,控制器也叫leader broker。
他除了具有一般broker的功能外,還負責分割槽leader的選取,也就是負責選舉partition的leader replica。
控制器是kafka核心中的核心,需要重點學習和理解。
控制器選舉
kafka每個broker啟動的時候,都會例項化一個KafkaController,並將broker的id註冊到zookeeper,這在第二章中已經通過例子做過講解。叢集在啟動過程中,通過選舉機制選舉出其中一個broker作為leader,也就是前面所說的控制器。
包括叢集啟動在內,有三種情況觸發控制器選舉:
1、叢集啟動
2、控制器所在代理髮生故障
3、zookeeper心跳感知,控制器與自己的session過期
按照慣例,先看圖。我們根據下圖來講解叢集啟動時,控制器選舉過程。
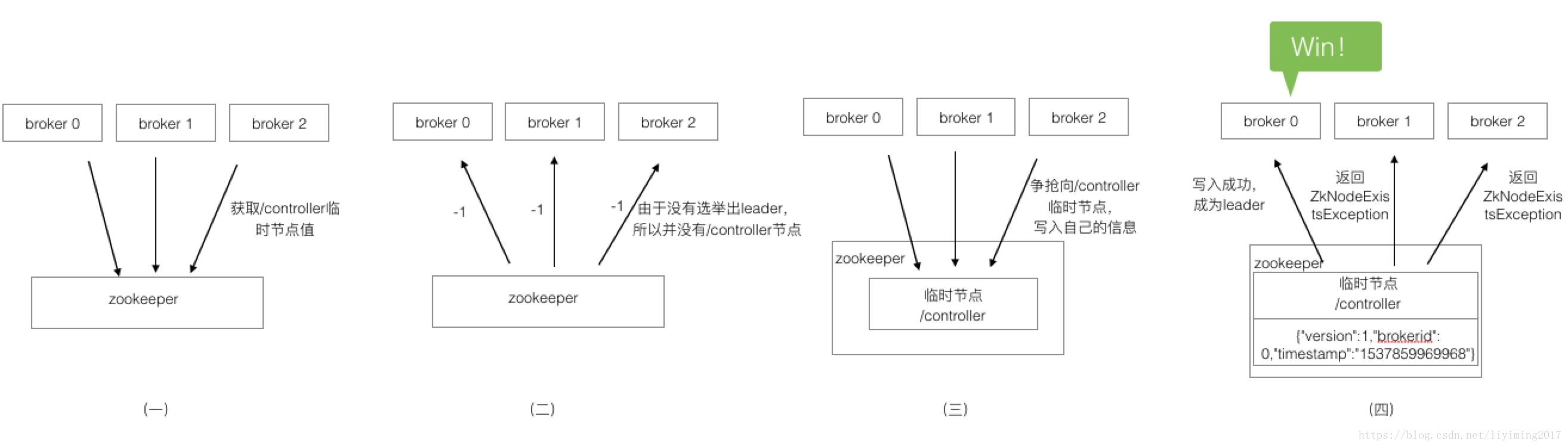
假設此叢集有三個broker,同時啟動。
(一)3個broker從zookeeper獲取/controller臨時節點資訊。/controller儲存的是選舉出來的leader資訊。此舉是為了確認是否已經存在leader。
(二)如果還沒有選舉出leader,那麼此節點是不存在的,返回-1。如果返回的不是-1,而是leader的json資料,那麼說明已經有leader存在,選舉結束。
(三)三個broker發現返回-1,瞭解到目前沒有leader,於是均會觸發向臨時節點/controller寫入自己的資訊。最先寫入的就會成為leader。
(四)假設broker 0的速度最快,他先寫入了/controller節點,那麼他就成為了leader。而broker1、broker2很不幸,因為晚了一步,他們在寫/controller的過程中會丟擲ZkNodeExistsException,也就是zk告訴他們,此節點已經存在了。
經過以上四步,broker 0成功寫入/controller節點,其它broker寫入失敗了,所以broker 0成功當選leader。
此外zk中還有controller_epoch節點,儲存了leader的變更次數,初始值為0,以後leader每變一次,該值+1。所有向控制器發起的請求,都會攜帶此值。如果控制器和自己記憶體中比較,請求值小,說明kafka叢集已經發生了新的選舉,此請求過期,此請求無效。如果請求值大於控制器記憶體的值,說明已經有新的控制器當選了,自己已經退位,請求無效。kafka通過controller_epoch保證叢集控制器的唯一性及操作的一致性。
由此可見,Kafka的控制器思想就是看誰先爭搶到/controller節點寫入自身資訊。
控制器初始化
控制器的初始化,其實是初始化控制器所用到的元件及監聽器,準備元資料。
前面提到過每個broker都會例項化並啟動一個KafkaController。KafkaController和他的元件關係,以及各個元件的介紹如下圖:

圖中箭頭為元件層級關係,元件下面還會再初始化其他元件。可見控制器內部還是有些複雜的,主要有以下元件:
1、ControllerContext,此物件儲存了控制器工作需要的所有上下文資訊,包括存活的代理、所有主題及分割槽分配方案、每個分割槽的AR、leader、ISR等資訊。
2、一系列的listener,通過對zookeeper的監聽,觸發相應的操作,黃色的框的均為listener
3、分割槽和副本狀態機,管理分割槽和副本。
4、當前代理選舉器ZookeeperLeaderElector,此選舉器有上位和退位的相關回調方法。
5、分割槽leader選舉器,PartitionLeaderSelector
6、主題刪除管理器,TopicDeletetionManager
7、leader向broker批量通訊的ControllerBrokerRequestBatch。快取狀態機處理後產生的request,然後統一發送出去。
8、控制器平衡操作的KafkaScheduler,僅在broker作為leader時有效。
圖片是我根據資料所總結,個人認為對於理解kafkaController的全貌很有幫助。本章節後面講到相應元件和流程時,還需要反覆回來理解此圖,思考元件所處的位置,對整體的作用。
故障轉移
故障轉移其實就是leader所在broker發生故障,leader轉移為其他的broker。轉移的過程就是重新選舉leader的過程。
重新選舉leader後,需要為該broker註冊相應許可權,呼叫的是ZookeeperLeaderElector的onControllerFailover()方法。在這個方法中初始化和啟動了一系列的元件來完成leader的各種操作。具體如下,其實和控制器初始化有很大的相似度。
1、註冊分割槽管理的相關監聽器
| 監聽名稱 | 監聽zookeeper節點 | 作用 |
| PartitionsReassignedListener | /admin/reassign_partitions | 節點變化將會引發分割槽重分配 |
| IsrChangeNotificationListener | /isr_change_notification | 處理分割槽的ISR發生變化引發的操作 |
| PreferredReplicaElectionListener | /admin/preferred_replica_election | 將優先副本選舉為leader副本 |
2、註冊主題管理的相關監聽
| 監聽名稱 | 監聽zookeeper節點 | 作用 |
| TopicChangeListener | /brokers/topics | 監聽主題發生變化時進行相應操作 |
| DeleteTopicsListener | /admin/delete_topics | 完成伺服器端刪除主題的相應操作。否則客戶端刪除主題僅僅是表示刪除 |
3、註冊代理變化監聽器
| 監聽名稱 | 監聽zookeeper節點 | 作用 |
| BrokerChangeListener | /brokers/ids | 代理髮生增減的時候進行相應的處理 |
4、重新初始化ControllerContext,
5、啟動控制器和其他代理之間通訊的ControllerChannelManager
6、建立用於刪除主題的TopicDeletionManager物件,並啟動。
7、啟動分割槽狀態機和副本狀態機
8、輪詢每個主題,新增監聽分割槽變化的PartitionModificationsListener
9、如果設定了分割槽平衡定時操作,那麼建立分割槽平衡的定時任務,預設300秒檢查並執行。
除了這些元件的啟動外,onControllerFailover方法中還做了如下操作:
1、/controller_epoch值+1,並且更新到ControllerContext
2、檢查是否出發分割槽重分配,並做相關操作
3、檢查需要將優先副本選為leader,並做相關操作
4、向kafka叢集所有代理髮送更新元資料的請求。
下面來看代理下線的方法onControllerResignation
1、該方法中登出了控制器的許可權。取消在zookeeper中對於分割槽、副本感知的相應監聽器的監聽。
2、關閉啟動的各個元件
3、最後把ControllerContext中記錄控制器版本的數值清零,並設定當前broker為RunnignAsBroker,變為普通的broker。
通過對控制器啟動過程的學習,我們應該已經對kafka工作的原理有了瞭解,核心是監聽zookeeper的相關節點,節點變化時觸發相應的操作。其它的處理流程都是相類似的。本篇教程接下來做簡要介紹,想要了解詳情的,可以先找其它資料。我後續也會再補充更為詳細的教程。
代理上下線
有新的broker加入叢集時,稱為代理上線。反之,當broker關閉,推出叢集時,稱為代理下線。
代理上線:
1、新代理啟動時向/brokers/ids寫資料
2、BrokerChangeListener監聽到變化。對新上線節點呼叫controllerChannelManager.addBroker(),完成新上線代理網路層初始化
3、呼叫KafkaController.onBrokerStartup()處理
3.1通過向所有代理髮送UpdateMetadataRequest,告訴所有代理有新代理加入
3.2根據分配給新上線節點的副本集合,對副本狀態做變遷。對分割槽也進行處理。
3.3觸發一次leader選舉,確認新加入的是否為分割槽leader
3.4輪詢分配給新broker的副本,呼叫KafkaController.onPartitionReassignment(),執行分割槽副本分配
3.5恢復因新代理上線暫停的刪除主題操作執行緒
代理下線:
1、查詢下線節點集合
2、輪詢下線節點,呼叫controllerChannelManager.removeBroker(),關閉每個下線節點網路連線。清空下線節點訊息佇列,關閉下線節點request請求
3、輪詢下線節點,呼叫KafkaController.onBrokerFailure處理
3.1處理leader副本在下線節點上上的分割槽,重新選出leader副本,傳送updateMetadataRequest請求。
3.2處理下線節點上的副本集合,做下線處理,從ISR集合中刪除,不再同步,傳送updateMetadataRequest請求。
4、向叢集全部存活代理髮送updateMetadataRequest請求
主題管理
通過分割槽狀態機及副本狀態機來進行主題管理
1、建立主題
/brokers/topics下建立主題對應子節點
TopicChangeListener監聽此節點
變化時獲取重入鎖ReentrantLock,呼叫handleChildChange方法進行處理。
通過對比zookeeper中/brokers/topics儲存的主題集合及控制器的ControllerContext中快取的主題集合的差集,得到新增的主題。反過來求差集,得到刪除的主題。
接下來遍歷新增的主題集合,進行主題操作的實質性操作。之前僅僅是在zookeeper中添加了主題。新增主題涉及的操作有分割槽、副本狀態的轉化、分割槽leader的分配、分割槽儲存日誌的建立等。
2、刪除主題
/admin/delete_topics建立刪除主題的子節點
DeleteTopicsListener監聽此節點,
變化時獲取重入鎖ReentrantLock,進行處理
具體的刪除邏輯再次就不再詳述。
分割槽管理
1、分割槽自動平衡
onControllerFailover方法中啟動分割槽自動平衡任務。定時檢查是否失去平衡。
自動平衡的操作就是把優先副本選為分割槽leader,AR中第一個副本為優先副本。
先查出所有可用副本,以分割槽AR頭節點分組。
輪詢代理節點,判斷分割槽不平衡率是否超過10%(leader為非優先副本的分割槽/該代理分割槽總數),則呼叫onPreferredReplicaElection(),讓優先副本成為leader。達到自動平衡。
分割槽平衡操作的流程已經在第三章做了很詳細的講解,此處不再重複,可以參考kafka核心概念。
2、分割槽重分配
當zk節點/admin/reassign_partitions變化時,觸發分割槽重分配操作。該節點儲存分割槽重分配的方案。
通過計算主題分割槽原AR(OAR)和重新分配後的AR(RAR),分別做相應處理:
1、OAR+RAR:更新到該主題分割槽AR,並通知副本節點同步。leader_epoch+1
2、RAR-OAR:副本設為NewReplica。
3、(OAR+RAR)- RAR:需要下線的副本,做下線操作
具體流程不再詳述
小結:關於控制器的相關知識點就先講到這裡,控制器初始化中的那張圖需要充分去理解,理解了此圖,對控制器內部的構造,以及控制器要做什麼事情、如何做的,就已經掌握了。另外考慮本教程定位為入門輕鬆學,所以具體的流程沒有展開來講,以後我會再寫相應的主題文章來說明。
--------------------- 本文來自 稀有氣體 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/liyiming2017/article/details/82843036?utm_source=copy