
深度學習基礎系列(一)| 一文看懂用kersa構建模型的各層含義(掌握輸出尺寸和可訓練引數數量的計算方法)
我們在學習成熟神經模型時,如VGG、Inception、Resnet等,往往面臨的第一個問題便是這些模型的各層引數是如何設定的呢?另外,我們如果要設計自己的網路模型時,又該如何設定各層引數呢?如果模型引數設定出錯的話,其實模型也往往不能運行了。
所以,我們需要首先了解模型各層的含義,比如輸出尺寸和可訓練引數數量。理解後,大家在設計自己的網路模型時,就可以先在紙上畫出網路流程圖,設定各引數,計算輸出尺寸和可訓練引數數量,最後就可以照此進行編碼實現了。
而在keras中,當我們構建模型或拿到一個成熟模型後,往往可以通過model.summary()來觀察模型各層的資訊。
本文將通過一個簡單的例子來進行說明。本例以keras官網的一個簡單模型VGG-like模型為基礎,稍加改動程式碼如下:
from tensorflow import keras from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Flatten from tensorflow.keras.layers import Conv2D, MaxPool2D (train_data, train_labels), (test_data, test_labels) = keras.datasets.mnist.load_data() train_data = train_data.reshape(-1, 28, 28, 1) print("train data type:{}, shape:{}, dim:{}".format(type(train_data), train_data.shape, train_data.ndim)) # 第一組 model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu', input_shape=(28, 28, 1))) model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu')) model.add(MaxPool2D(pool_size=(2, 2))) model.add(Dropout(0.25)) # 第二組 model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu')) model.add(Conv2D(filters=64, kernel_size=(3, 3), strides=(1, 1), padding='valid', activation='relu')) model.add(MaxPool2D(pool_size=(2, 2))) model.add(Dropout(0.25)) # 第三組 model.add(Flatten()) model.add(Dense(units=256, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units=10, activation='softmax')) model.summary()
本例的資料來源於mnist,這是尺寸為28*28,通道數為1,也即只有黑白兩色的圖片。其中卷積層的引數含義為:
- filters:表示過濾器的數量,每一個過濾器都會與對應的輸入層進行卷積操作;
- kernel_size:表示過濾器的尺寸,一般為奇數值,如1,3,5,這裡設定為3*3大小;
- strides:表示步長,即每一次過濾器在圖片上移動的步數;
- padding:表示是否對圖片邊緣填充畫素,一般有兩個值可選,一是預設的valid,表示不填充畫素,卷積後圖片尺寸會變小;另一種是same,填充畫素,使得輸出尺寸和輸入尺寸保持一致。
如果選擇valid,假設輸入尺寸為n * n,過濾器的大小為f * f,步長為s,則其輸出圖片的尺寸公式為:[(n - f)/s + 1] * [(n -f)/s + 1)],若計算結果不為整數,則向下取整;
如果選擇same,假設輸入尺寸為n * n,過濾器的大小為f * f,要填充的邊緣畫素寬度為p,則計算p的公式為:n + 2p -f +1 = n, 最後得 p = (f -1) /2。
執行上述例子,可以看到如下結果:
train data type:<class 'numpy.ndarray'>, shape:(60000, 28, 28, 1), dim:4
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
conv2d_1 (Conv2D) (None, 24, 24, 32) 9248
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 12, 12, 32) 0
_________________________________________________________________
dropout (Dropout) (None, 12, 12, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 10, 10, 64) 18496
_________________________________________________________________
conv2d_3 (Conv2D) (None, 8, 8, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 4, 4, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 256) 262400
_________________________________________________________________
dropout_2 (Dropout) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 2570
=================================================================
Total params: 329,962
Trainable params: 329,962
Non-trainable params: 0讓我們解讀下,首先mnist為輸入資料,尺寸大小為 (60000, 28, 28, 1), 這是典型的NHWC結構,即(圖片數量,寬度,高度,通道數);
其次我們需要關注表格中的"output shape"輸出尺寸,其遵循mnist一樣的結構,只不過第一位往往是None,表示圖片數待定,後三位則按照上述規則進行計算;
最後關注的是"param"可訓練引數數量,不同的模型層計算方法不一樣:
- 對於卷積層而言,假設過濾器尺寸為f * f, 過濾器數量為n, 若開啟了bias,則bias數固定為1,輸入圖片的通道數為c,則param計算公式= (f * f * c + 1) * n;
- 對於池化層、flatten、dropout操作而言,是不需要訓練引數的,所以param為0;
- 對於全連線層而言,假設輸入的列向量大小為i,輸出的列向量大小為o,若開啟bias,則param計算公式為=i * o + o
按照程式碼中劃分的三組模型層次,其輸出尺寸和可訓練引數數量的計算方法可如下圖所示:
第一組:
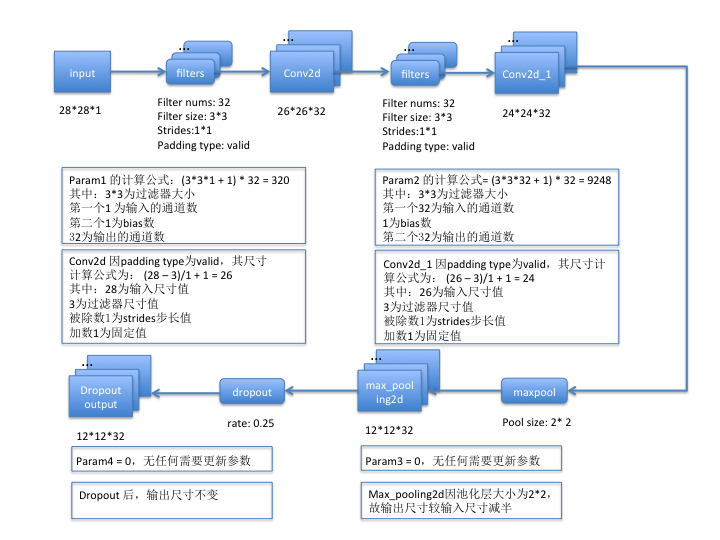
第二組:
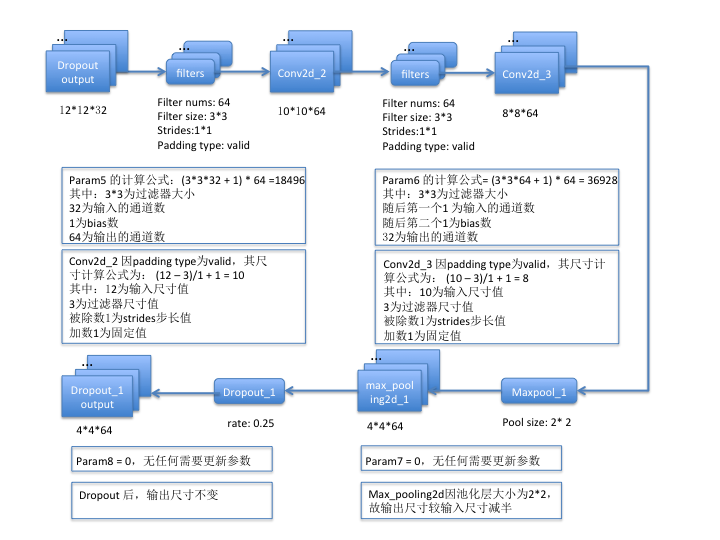
第三組:
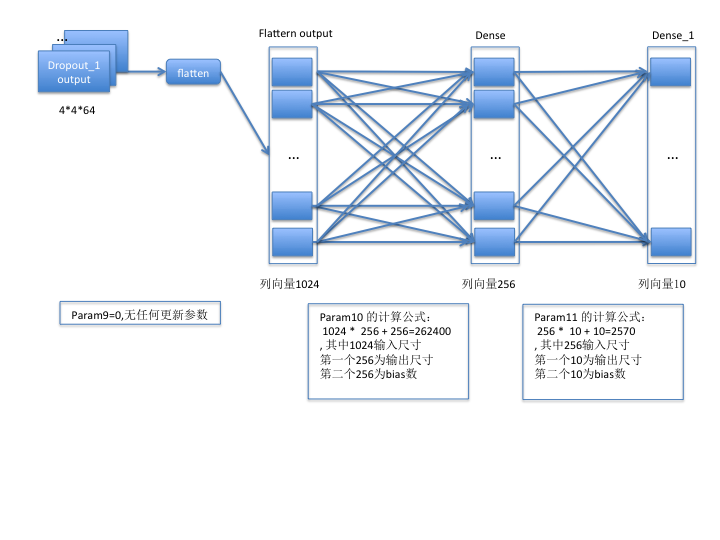
至此,模型各層的含義和相關計算方法已介紹完畢,希望此文能幫助大家更好地理解模型的構成和相關計算。